

- Was können Qwen3-VL-235B-A22B und GLM 4.5V wirklich für Ihr kleines Unternehmen leisten?
- Wie unterscheiden sich Qwen3-VL-235B-A22B und GLM 4.5V in der Architektur?
- Welches Modell schneidet also besser ab: Qwen3-VL-235B-A22B oder GLM 4.5V?
- Wie können Sie Qwen3-VL-235B-A22B und GLM 4.5V auf günstige und schnelle Weise nutzen?
Da kleine Unternehmen KI für Aufgaben wie Dokumentenanalyse, Kundensupport, visuelle Automatisierung oder Programmierunterstützung einsetzen möchten, kann die Wahl zwischen leistungsstarken Open-Source-Modellen wie Qwen3-VL-235B-A22B und GLM 4.5V überwältigend sein. Was sind die tatsächlichen Unterschiede bei Leistung, Kosten, Zugänglichkeit und Aufwand für die Bereitstellung?
Dieser Artikel vergleicht die Modelle über die Dimensionen Architektur, Anwendungsmöglichkeiten, Leistungsbenchmarks, Preise und Zugriffsmethoden und gibt Ihnen eine klare Entscheidungshilfe, um das passende Modell für Ihr Unternehmen zu finden. Egal, ob Sie intelligente Workflows erstellen, lokal bereitstellen oder APIs aufrufen möchten – dieser Leitfaden hilft Ihnen, eine fundierte und sichere Entscheidung zu treffen.
Was können Qwen3-VL-235B-A22B und GLM 4.5V wirklich für Ihr kleines Unternehmen leisten?
Möchten Sie sehen, welches Modell am besten zu Ihrem Workflow passt?
Sowohl Qwen3-VL-235B-A22B als auch GLM 4.5V bieten kostenlose Online-Demos von Novita AI!
| Anwendungsbereich | Qwen3-VL-235B-A22B | GLM 4.5V | Sieger |
|---|---|---|---|
| GUI-Interaktion | Steuert PC-/Mobil-Benutzeroberflächen, versteht Oberflächenelemente und ruft Tools auf. | Unterstützt Bildschirmlesen und grundlegende Desktop-Aktionen. | Mögliches Unentschieden |
| Visuelle Code-Generierung | ✅ Konvertiert Screenshots/Videos in HTML, CSS, JS und Draw.io-Diagramme. | ❌ Keine visuellen Code-Generierungsfunktionen bekannt. | Qwen gewinnt |
| 3D- und räumliches Reasoning | ✅ Erweitert: Erkennt Objektposition, Verdeckung und Blickwinkel; ermöglicht 3D-Grounding. | ⚠️ Verarbeitet räumliche Layouts über Bilder hinweg, keine 3D-Grounding- oder verkörperte KI-Funktionen. | Qwen gewinnt |
| Video-Verständnis | ✅ Verarbeitet stundenlange Videos mit 256K–1M Token Kontext; feingranulare zeitliche Analyse. | ⚠️ Unterstützt Event-Segmentierung, ist aber wahrscheinlich durch ein 66K Token-Fenster begrenzt. | Qwen gewinnt |
| Umfang der visuellen Erkennung | ✅ Trainiert, um „alles zu erkennen“: Prominente, Anime, seltene Arten, Wahrzeichen, Schilder und alte Schriftzeichen. | ⚠️ Starke Szenenanalyse, aber keine Angaben zur Erkennung von Nischen- oder seltenen Entitäten. | Qwen gewinnt |
| OCR/Text-Extraktion | ✅ 32 Sprachen, robust bei Unschärfe/Neigung, unterstützt seltene/antike Schriftzeichen und strukturierte Layouts. | ⚠️ Extrahiert lange Dokumente gut, aber fehlt es an Sprach- und Seltentext-Vielfalt. | Qwen gewinnt |
| Textverständnis | ✅ Vergleichbar mit reinen LLMs; fließende Vision-Text-Fusion ohne Verständnisverlust. | ✅ Starker Generator mit umschaltbarem „Reasoning-Modus“; hohe Sprachqualität. | Mögliches Unentschieden |
| Zugänglichkeit | Verfügbar über API oder Demo. | Verfügbar über API oder Demo sowie einen Desktop-Assistenten, der Bilder, PDFs, Videos usw. unterstützt. | GLM gewinnt |
Wie unterscheiden sich Qwen3-VL-235B-A22B und GLM 4.5V in der Architektur?
Qwen3-VL sticht als „Schwergewicht“-Option hervor, die Skalierung und Informationskapazität priorisiert: Seine 235B Gesamtparameter, das 256K (auf 1M erweiterbare) Token-Kontextfenster und spezialisierte Reasoning-Varianten machen es ideal für groß angelegte Aufgaben.
GLM 4.5V hingegen betont Flexibilität und Effizienz, ohne Leistung einzubüßen. Sein kompakteres 106B-Parameter-Design, das 128K Token-Kontextfenster und das einheitliche Modell mit umschaltbarem „Thinking-Modus“ schaffen eine Balance zwischen Geschwindigkeit und Tiefe.
| Vergleichsdimension | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|
| Modellgröße & MoE-Architektur | Gesamtparameter: 235B Aktive Parameter pro Eingabe: 22B |
Gesamtparameter: 106B Aktive Parameter pro Eingabe: 12B |
| Kontextfenster-Kapazität | Nativ: 256K Token Erweiterbar auf: 1M Token |
Nativ: 128K Token |
| Reasoning- und Steuerungsmodi | Ein Thinking-Modus-Schalter, der es Nutzern ermöglicht, zwischen schnellen Antworten und tiefem Reasoning abzuwägen. | Ein Thinking-Modus-Schalter, der es Nutzern ermöglicht, zwischen schnellen Antworten und tiefem Reasoning abzuwägen. |
| Visuelle Verarbeitung | ViT-basierter Encoder + Text-Decoder Erweiterungen: Interleaved-MRoPE (Video-Reasoning), fusionierte Vision-Funktionen |
ViT-basierter Encoder + Text-Decoder Erweiterung: Sauberer Adapter für Vision-Sprach-Fusion |
| Geschwindigkeit | Latenz von 1,8–2 s | Latenz von 0,3–1,5 s |
| Hardware-Anforderungen | 8 NVIDIA H200 GPUs. | Eine einzelne 80-GB-GPU (z. B. eine NVIDIA A100/H100 80 GB) in 16-Bit-Präzision |
Welches Modell schneidet also besser ab: Qwen3-VL-235B-A22B oder GLM 4.5V?
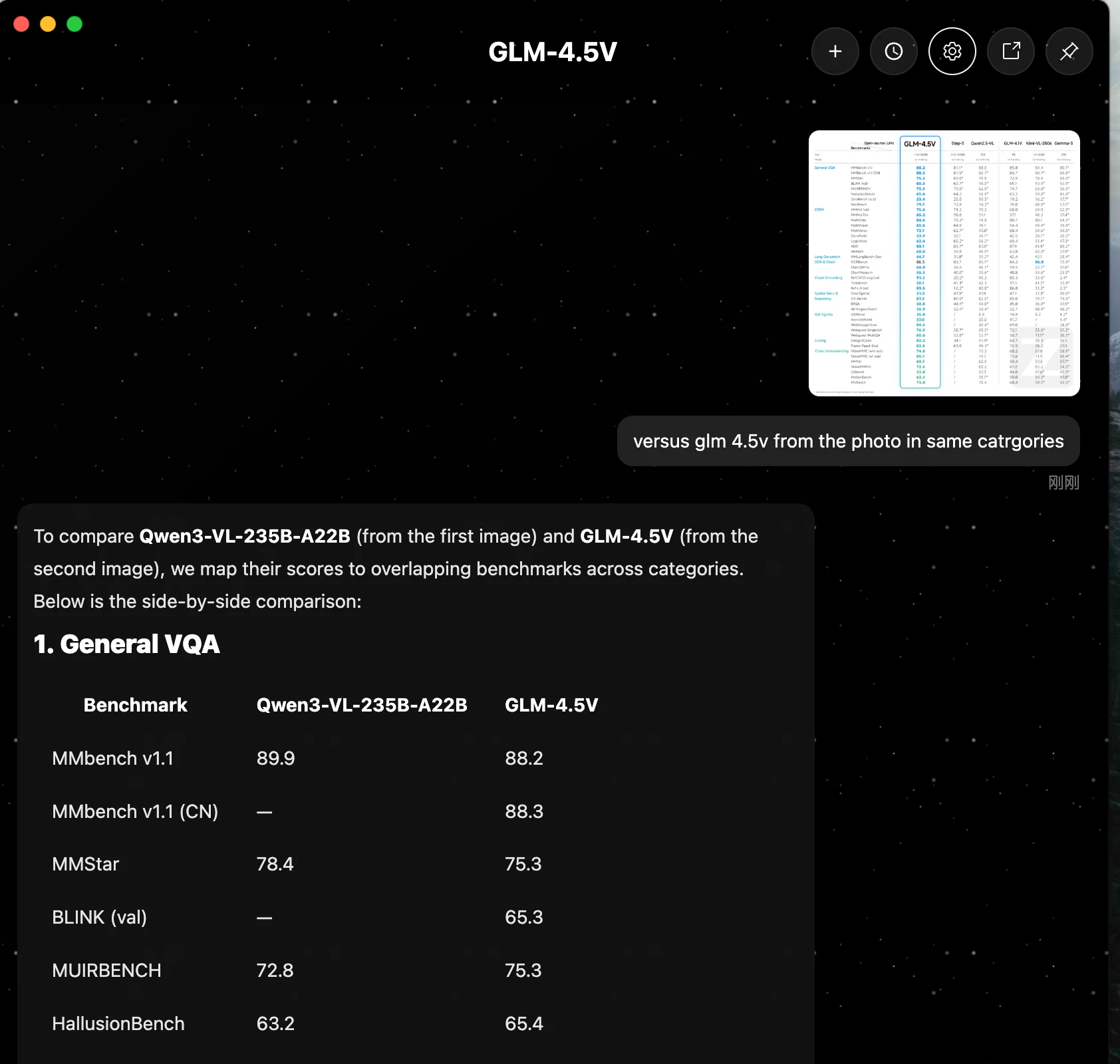
Qwen3-VL-235B-A22B liegt bei Kern-Reasoning, Dokumentenverarbeitung und Code-Generierung generally vorne. GLM 4.5V schneidet bei mehreren Aufgaben ähnlich gut ab, übertrifft Qwen aber in keinem der gezeigten Benchmarks.
| Kategorie | Benchmark | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|---|
| 1. Allgemeine VQA | MMBench v1.1 | 89.9 | 88.2 |
| MMStar | 78.4 | 75.3 | |
| MUIRBENCH | 72.8 | 75.3 | |
| HallusionBench | 63.2 | 65.4 | |
| 2. STEM & Rätsel | MMMU (val) | 78.7 | 75.4 |
| MMMU Pro | 68.1 | 65.2 | |
| MathVista | 84.9 | 84.6 | |
| MathVision | 66.5 | 65.6 | |
| MathVerse | 72.5 | 72.1 | |
| AI2D | 89.7 | 88.1 | |
| 3. Lange Dokumente & OCR/Diagramme | MMLongBench-Doc | 57.0 | 44.7 |
| OCRBench | 920.0* | 86.5 | |
| 4. Programmierung | Design2Code | 92.0 | 82.2 |
| 5. Video-Verständnis | VideoMME (w/o sub) | 79.2 | 74.6 |
Sie können auch einen Novita AI API-Schlüssel verwenden, um auf GLMs Desktop-Assistenten kostenlos zuzugreifen – im Gegensatz zur offiziellen Seite ist keine Zahlung erforderlich!
Der Desktop ist für die multimodalen Modelle der GLM-Serie ausgelegt (GLM-4.5V, kompatibel mit GLM-4.1V) und unterstützt interaktive Gespräche mit Text, Bildern, Videos, PDFs, PPTs und mehr. Er verbindet sich mit der GLM-Multimodal-API, um intelligente Dienste in verschiedenen Szenarien zu ermöglichen.
Die Einstellungen:
Modellname: zai-org/glm-4.5v
API-URL: https://api.novita.ai/openai
Endpunkt: /v1/chat/completions
API-Schlüssel: von Novita AI
Jetzt API-Schlüssel holen und GLMs kostenlosen Desktop-Assistenten testen!
Wie können Sie Qwen3-VL-235B-A22B und GLM 4.5V auf günstige und schnelle Weise nutzen?
Novita AI bietet Qwen3-VL-APIs mit einem 131K-Kontextfenster für 0,98 $ pro Eingabe und 3,95 $ pro Ausgabe. Außerdem stellt es GLM-4.6V-APIs mit einem 208K-Kontextfenster für 0,60 $ pro Eingabe und 2,20 $ pro Ausgabe bereit, die strukturierte Ausgaben und Funktionsaufrufe unterstützen.
1. Weboberfläche (Am einfachsten für Einsteiger)
Qwen 3 VL 235B A22B jetzt testen!
2. API-Zugriff (Für Entwickler)
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihren Account ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die benötigten Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. Lokale Bereitstellung (Für fortgeschrittene Nutzer)
Anforderungen:
- Qwen3-VL-235B-A22B: 8 NVIDIA H200 GPUs.
- GLM 4.5V: Eine einzelne 80-GB-GPU (z. B. eine NVIDIA A100/H100 80 GB) in 16-Bit-Präzision
Installationsschritte:
- Laden Sie die Modellgewichte von HuggingFace oder ModelScope herunter
- Wählen Sie ein Inferenz-Framework: vLLM oder SGLang werden unterstützt
- Befolgen Sie den Bereitstellungsleitfaden im offiziellen GitHub-Repository
4. Integration
Nutzung von CLIs wie Trae, Claude Code, Qwen Code
Wenn Sie die Top-Modelle von Novita AI (wie Qwen3-Coder, Kimi K2, DeepSeek R1) für KI-Programmierunterstützung in Ihrer lokalen Umgebung oder IDE nutzen möchten, ist der Prozess einfach: Holen Sie sich Ihren API-Schlüssel, installieren Sie das Tool, konfigurieren Sie Umgebungsvariablen und beginnen Sie mit dem Programmieren.
Ausführliche Einrichtungsbefehle und Beispiele finden Sie in den offiziellen Tutorials:
- Trae: Schritt-für-Schritt-Anleitung zum Zugriff auf KI-Modelle in Ihrer IDE
- Claude Code: So verwenden Sie Kimi-K2 in Claude Code unter Windows, Mac und Linux
- Qwen Code: So verwenden Sie die OpenAI-kompatible API in Qwen Code (60-Sekunden-Einrichtung!)
Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Nutzen Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die Aufgaben delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von den Modellen von Novita AI.
- Python-Integration: Setzen Sie einfach den SDK-Endpunkt auf
https://api.novita.ai/v3/openaiund verwenden Sie Ihren API-Schlüssel.
API auf Drittanbieterplattformen verbinden
OpenAI-kompatible API: Genießen Sie problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard ausgelegt sind.
Hugging Face: Nutzen Sie Modelle in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
Agent- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsleitfäden.
Qwen3-VL-235B-A22B zeigt klare Stärken in fortgeschrittenem Reasoning, visuellem Coding, mehrsprachiger OCR und Langkontextverarbeitung – was es zur ersten Wahl für anspruchsvolle Workflows und multimodale Aufgaben macht.
GLM 4.5V ist zwar bei der Rohleistung leicht unterlegen, aber leichter und bietet einen Desktop-Assistenten, schnellere Inferenzgeschwindigkeit und breitere Plug-and-Play-Nutzbarkeit – insbesondere für Entwickler und Startups. Für die meisten Anwendungsfälle eignet sich Qwen3-VL-235B-A22B ideal für Tiefe und Komplexität, während GLM 4.5V bei Benutzerfreundlichkeit und Flexibilität glänzt.
Häufig gestellte Fragen
Kann GLM 4.5V offline oder außerhalb des Browsers verwendet werden?
Ja, GLM 4.5V unterstützt einen kostenlosen Desktop-Assistenten (über Novita AI), der es Nutzern ermöglicht, lokal mit Text, Bildern, Videos und PDFs zu interagieren – etwas, das Qwen3-VL-235B-A22B nativ nicht bietet.
Was ist der günstigste und schnellste Weg, Qwen3-VL-235B-A22B und GLM 4.5V auszuprobieren?
Qwen3-VL-API: 131K Kontext, 0,98 $/Eingabe, 3,95 $/Ausgabe
GLM-4.6V-API: 208K Kontext, 0,60 $/Eingabe, 2,20 $/Ausgabe, mit strukturierter Ausgabe und Funktionsaufrufen
Welches Modell schneidet bei Benchmark-Auswertungen besser ab – Qwen3-VL-235B-A22B oder GLM 4.5V?
Qwen3-VL-235B-A22B erzielt durchgängig höhere Werte als GLM 4.5V in Kategorien wie STEM-Reasoning (z. B. MMMU), Langdokumentenanalyse (MMLongBench-Doc), OCR (OCRBench) und Programmierung (Design2Code). GLM 4.5V schneidet zwar gut ab, übertrifft Qwen aber in keinem der aufgeführten Benchmarks.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren von Anwendungen bereitstellt.



