

소규모 비즈니스가 문서 파싱, 고객 지원, 시각적 자동화, 코딩 지원 등의 작업에 AI를 도입하려 할 때, Qwen3-VL-235B-A22B와 GLM 4.5V 같은 강력한 오픈소스 모델 사이에서 선택하는 것은 압도적으로 느껴질 수 있습니다. 성능, 비용, 접근성, 배포 난이도 사이의 실제 차이는 무엇일까요?
이 글에서는 아키텍처, 응용 기능, 성능 벤치마크, 가격, 접근 방식을 비교 분석하여 어떤 모델이 비즈니스에 가장 적합한지 명확히 알려드립니다. 지능형 워크플로우를 구축하든, 로컬에 배포하든, API를 호출하든, 이 가이드는 정보에 기반한 확신 있는 선택을 돕습니다.
Qwen3-VL-235B-A22B와 GLM 4.5V가 소규모 비즈니스에 실제로 제공할 수 있는 기능은?
어떤 모델이 워크플로우에 가장 적합한지 확인해보세요.
Qwen3-VL-235B-A22B와 GLM 4.5V 모두 Novita AI에서 무료 온라인 데모를 제공합니다!
| 응용 분야 | Qwen3-VL-235B-A22B | GLM 4.5V | 승자 |
|---|---|---|---|
| GUI 상호작용 | PC/모바일 UI 조작, 인터페이스 요소 이해, 도구 호출 가능 | 화면 읽기 및 기본 데스크탑 작업 지원 | 비슷함 |
| 시각→코드 생성 | ✅ 스크린샷/비디오를 HTML, CSS, JS, Draw.io 다이어그램으로 변환 가능 | ❌ 시각→코드 기능 미공개 | Qwen 승 |
| 3D 및 공간 추론 | ✅ 고급: 객체 위치, 가림, 시점 인식; 3D 그라운딩 가능 | ⚠️ 이미지 간 공간 레이아웃 처리, 3D 그라운딩 또는 임베디드 AI 없음 | Qwen 승 |
| 비디오 이해 | ✅ 256K–1M 토큰 컨텍스트로 장시간 비디오 처리; 세밀한 시간적 분석 가능 | ⚠️ 이벤트 분할 지원하나 66K 토큰 윈도우에 제한될 가능성 | Qwen 승 |
| 시각 인식 범위 | ✅ "모든 것을 인식"하도록 훈련: 유명인, 애니메이션, 희귀종, 랜드마크, 표지판, 고대 문자 | ⚠️ 강력한 장면 분석, 하지만 특수/희귀 개체 인식 주장 없음 | Qwen 승 |
| OCR/텍스트 추출 | ✅ 32개 언어, 흐림/기울임에도 강함, 희귀/고대 문자 및 구조화된 레이아웃 지원 | ⚠️ 긴 문서 추출은 잘하지만 언어 및 희귀 텍스트 범위 부족 | Qwen 승 |
| 텍스트 이해 | ✅ 순수 LLM과 유사; 유창한 시각-텍스트 융합으로 이해력 손실 없음 | ✅ “추론 모드” 토글 지원, 높은 언어 품질 | 비슷함 |
| 접근 용이성 | API 또는 데모로 이용 가능 | API/데모 및 이미지, PDF, 비디오 등을 지원하는 데스크탑 어시스턴트 제공 | GLM 승 |
Qwen3-VL-235B-A22B와 GLM 4.5V는 아키텍처 측면에서 어떻게 다른가?
Qwen3-VL은 “헤비급” 옵션으로, 규모와 정보 용량에 중점을 둡니다: 총 235B 파라미터, 256K(확장 시 1M) 토큰 컨텍스트 창, 특화된 추론 변형으로 대규모 작업에 이상적입니다.
반면 GLM 4.5V는 성능 저하 없이 유연성과 효율성을 강조합니다. 더 컴팩트한 106B 파라미터 설계, 128K 토큰 컨텍스트 창, 토글 가능한 "Thinking Mode"가 있는 통합 모델로 속도와 깊이 사이의 균형을 잘 맞춥니다.
| 비교 항목 | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|
| 모델 크기 및 MoE 아키텍처 | 총 파라미터: 235B 입력당 활성 파라미터: 22B |
총 파라미터: 106B 입력당 활성 파라미터: 12B |
| 컨텍스트 윈도우 용량 | 기본: 256K 토큰 확장 가능: 1M 토큰 |
기본: 128K 토큰 |
| 추론 및 명령 모드 | Thinking Mode 스위치로 빠른 응답과 심층 추론 간 균형 가능 | Thinking Mode 스위치로 빠른 응답과 심층 추론 간 균형 가능 |
| 시각 처리 | ViT 기반 인코더 + 텍스트 디코더 개선: Interleaved-MRoPE (비디오 추론), 융합 시각 특징 |
ViT 기반 인코더 + 텍스트 디코더 개선: 시각-언어 융합을 위한 깔끔한 어댑터 |
| 속도 | 지연 시간 1.8-2초 | 지연 시간 0.3-1.5초 |
| 하드웨어 요구사항 | NVIDIA H200 GPU 8개 | 16비트 정밀도에서 단일 80GB GPU (예: NVIDIA A100/H100 80GB) |
그렇다면 어떤 모델이 더 나은 성능을 보여주는가: Qwen3-VL-235B-A22B vs GLM 4.5V?
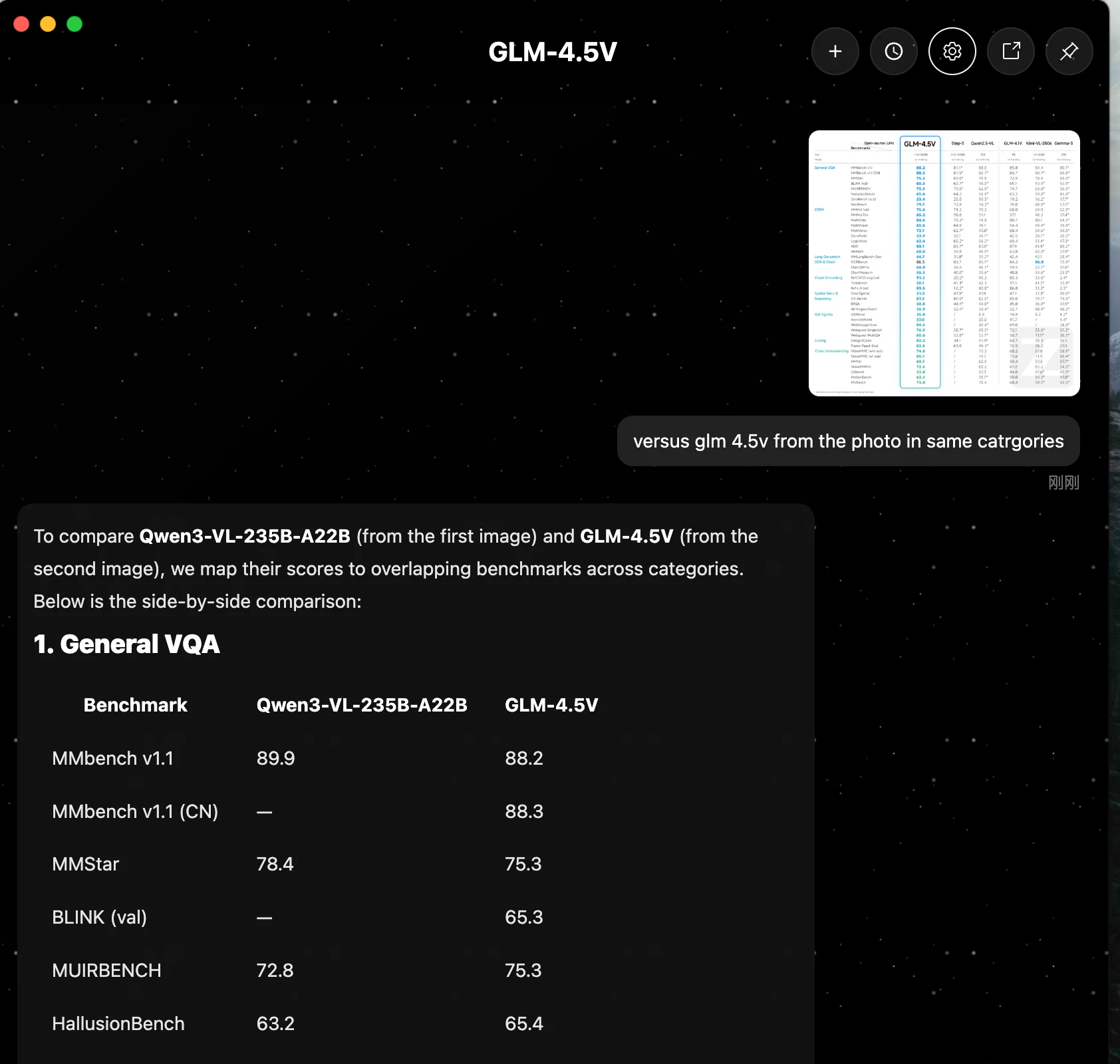
Qwen3-VL-235B-A22B는 일반적으로 핵심 추론, 문서 처리, 코드 생성에서 앞서 있습니다. GLM 4.5V는 여러 작업에서 근접한 성능을 보이지만, 제시된 벤치마크에서 Qwen을 능가하지는 못합니다.
| 카테고리 | 벤치마크 | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|---|
| 1. 일반 VQA | MMbench v1.1 | 89.9 | 88.2 |
| MMStar | 78.4 | 75.3 | |
| MUIRBENCH | 72.8 | 75.3 | |
| HallusionBench | 63.2 | 65.4 | |
| 2. STEM 및 퍼즐 | MMMU (val) | 78.7 | 75.4 |
| MMMU Pro | 68.1 | 65.2 | |
| MathVista | 84.9 | 84.6 | |
| MathVision | 66.5 | 65.6 | |
| MathVerse | 72.5 | 72.1 | |
| AI2D | 89.7 | 88.1 | |
| 3. 긴 문서 및 OCR/차트 | MMLongBench-Doc | 57.0 | 44.7 |
| OCRBench | 920.0* | 86.5 | |
| 4. 코딩 | Design2Code | 92.0 | 82.2 |
| 5. 비디오 이해 | VideoMME (자막 없음) | 79.2 | 74.6 |
또한 Novita AI API 키를 사용하면 GLM의 데스크탑 어시스턴트를 무료로 이용할 수 있습니다. 공식 사이트와 달리 결제가 필요 없습니다!
데스크탑은 GLM 시리즈 멀티모달 모델 (GLM-4.5V, GLM-4.1V 호환)을 위해 설계되었으며, 텍스트, 이미지, 비디오, PDF, PPT 등과의 대화형 상호작용을 지원합니다. GLM 멀티모달 API에 연결하여 다양한 시나리오에서 지능형 서비스를 제공합니다.
설정:
모델 이름: zai-org/glm-4.5v
API URL: https://api.novita.ai/openai
엔드포인트: /v1/chat/completions
API 키: Novita AI에서 발급
지금 API 키를 받고 GLM 데스크탑 어시스턴트를 무료로 사용해보세요!
Qwen3-VL-235B-A22B와 GLM 4.5V를 저렴하고 빠르게 사용하는 방법은?
Novita AI는 Qwen3-VL API를 131K 컨텍스트 윈도우에 입력 $0.98, 출력 $3.95에 제공합니다. 또한 GLM-4.6V API를 208K 컨텍스트 윈도우에 입력 $0.60, 출력 $2.20에 제공하며, 구조화된 출력 및 함수 호출을 지원합니다.
1. 웹 인터페이스 (초보자에게 가장 쉬움)
2. API 접근 (개발자용)
1단계: 로그인 및 모델 라이브러리 접속
계정에 로그인하고 Model Library 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.

3단계: 무료 체험 시작
선택한 모델의 기능을 살펴보기 위해 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새 API 키를 제공합니다. “Settings” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사하세요.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.
설치 후, 필요한 라이브러리를 개발 환경에 가져오세요. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작하세요. 다음은 Python 사용자를 위한 chat completions API 예제입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. 로컬 배포 (고급 사용자)
요구 사항:
- Qwen3-VL-235B-A22B: NVIDIA H200 GPU 8개
- GLM 4.5V: 16비트 정밀도에서 단일 80GB GPU (예: NVIDIA A100/H100 80GB)
설치 단계:
- HuggingFace 또는 ModelScope에서 모델 가중치 다운로드
- 추론 프레임워크 선택: vLLM 또는 SGLang 지원
- 공식 GitHub 저장소의 배포 가이드 참조
4. 통합
CLI 사용 (예: Trae, Claude Code, Qwen Code)
로컬 환경이나 IDE에서 AI 코딩 지원을 위해 Novita AI의 최고 모델(Qwen3-Coder, Kimi K2, DeepSeek R1 등)을 사용하려면 간단합니다: API 키를 받고, 도구를 설치하고, 환경 변수를 구성하고, 코딩을 시작하면 됩니다.
자세한 설정 명령과 예제는 공식 튜토리얼을 확인하세요:
- Trae : IDE에서 AI 모델에 접근하는 단계별 가이드
- Claude Code: Windows, Mac, Linux에서 Claude Code로 Kimi-K2 사용하기
- Qwen Code: Qwen Code에서 OpenAI 호환 API 사용하기 (60초 설정!)
OpenAI Agents SDK를 이용한 멀티 에이전트 워크플로우
Novita AI를 OpenAI Agents SDK와 통합하여 고급 멀티 에이전트 시스템을 구축하세요:
- 플러그 앤 플레이: Novita AI의 LLM을 모든 OpenAI Agents 워크플로우에서 사용 가능.
- 핸드오프, 라우팅, 도구 사용 지원: 에이전트가 작업을 위임, 분류 또는 함수를 실행하도록 설계 가능, 모두 Novita AI의 모델 지원.
- Python 통합: SDK 엔드포인트를
https://api.novita.ai/v3/openai로 설정하고 API 키를 사용하면 됩니다.
타사 플랫폼에서 API 연결
OpenAI 호환 API: Cline 및 Cursor와 같은 도구로 간편하게 마이그레이션하고 통합할 수 있으며, OpenAI API 표준을 준수합니다.
Hugging Face: Spaces, 파이프라인 또는 Transformers 라이브러리에서 Novita AI 엔드포인트를 통해 모델을 사용하세요.
에이전트 및 오케스트레이션 프레임워크: Continue, AnythingLLM,LangChain, Dify, Langflow와 같은 파트너 플랫폼을 공식 커넥터 및 단계별 통합 가이드를 통해 Novita AI와 쉽게 연결하세요.
Qwen3-VL-235B-A22B는 고급 추론, 시각 코딩, 다국어 OCR, 긴 컨텍스트 처리에서 뚜렷한 강점을 보여주며, 까다로운 워크플로우와 멀티모달 작업에 최고의 선택이 됩니다.
GLM 4.5V는 원시 성능에서 약간 뒤쳐지지만, 더 가볍고 데스크탑 어시스턴트, 더 빠른 추론 속도, 더 넓은 플러그 앤 플레이 사용성을 제공하여 특히 개발자와 스타트업에게 적합합니다. 대부분의 사용 사례에서 Qwen3-VL-235B-A22B는 깊이와 복잡성에 이상적이며, GLM 4.5V는 사용 편의성과 유연성에서 탁월합니다.
자주 묻는 질문
GLM 4.5V를 오프라인이나 브라우저 외부에서 사용할 수 있나요?
네, GLM 4.5V는 (Novita AI를 통해) 무료 데스크탑 어시스턴트를 지원하여 사용자가 로컬에서 텍스트, 이미지, 비디오, PDF와 상호작용할 수 있습니다. 이는 Qwen3-VL-235B-A22B가 기본적으로 제공하지 않는 기능입니다.
Qwen3-VL-235B-A22B와 GLM 4.5V를 가장 저렴하고 빠르게 체험하는 방법은?
Qwen3-VL API: 131K 컨텍스트, 입력 $0.98, 출력 $3.95
GLM-4.6V API: 208K 컨텍스트, 입력 $0.60, 출력 $2.20, 구조화된 출력 및 함수 호출 지원
벤치마크 평가에서 Qwen3-VL-235B-A22B와 GLM 4.5V 중 어떤 모델이 더 우수한가요?
Qwen3-VL-235B-A22B는 STEM 추론(예: MMMU), 긴 문서 분석(MMLongBench-Doc), OCR(OCRBench), 코딩(Design2Code) 등에서 GLM 4.5V보다 일관되게 높은 점수를 기록합니다. GLM 4.5V도 준수한 성능을 보이지만, 제시된 벤치마크에서 Qwen을 능가하지는 못합니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 지원하는 AI 클라우드 플랫폼이며, 동시에 구축 및 확장에 저렴하고 안정적인 GPU 클라우드를 제공합니다.



