

مع سعي الشركات الصغيرة لاعتماد الذكاء الاصطناعي لمهام مثل تحليل المستندات، ودعم العملاء، والأتمتة المرئية، أو مساعدة البرمجة، يمكن أن يكون الخيار بين النماذج مفتوحة المصدر القوية مثل Qwen3-VL-235B-A22B و GLM 4.5V أمرًا مربكًا. ما هو الفرق الحقيقي بين أدائهما، وتكلفتهما، وسهولة الوصول إليهما، وصعوبة نشرهما؟
يقارن هذا المقال عبر البنية المعمارية، وقدرات التطبيق، ومقاييس الأداء، والتسعير، وطرق الوصول، مما يمنحك مسارًا واضحًا لتحديد النموذج الذي يناسب عملك بشكل أفضل. سواء كنت تبني سير عمل ذكي، أو تنشر محليًا، أو تستدعي واجهات برمجة التطبيقات (APIs)، فإن هذا الدليل يساعدك على اتخاذ خيار مستنير وواثق.
ماذا يمكن أن يفعله Qwen3-VL-235B-A22B و GLM 4.5V حقًا لشركتك الصغيرة؟
هل تريد معرفة أي نموذج يناسب سير عملك بشكل أفضل؟
يقدم كل من Qwen3-VL-235B-A22B و GLM 4.5V عروض تجريبية مجانية عبر الإنترنت من Novita AI!
| مجال التطبيق | Qwen3-VL-235B-A22B | GLM 4.5V | الفائز |
|---|---|---|---|
| تفاعل واجهة المستخدم الرسومية (GUI) | يتحكم في واجهات المستخدم لأجهزة الكمبيوتر/الهواتف المحمولة، يفهم عناصر الواجهة، ويستدعي الأدوات. | يدعم قراءة الشاشة والإجراءات الأساسية لسطح المكتب. | قد يتعادلان |
| توليد الكود من المدخلات المرئية | ✅ يحول لقطات الشاشة/الفيديوهات إلى HTML و CSS و JS ومخططات Draw.io. | ❌ لم يتم الإعلان عن قدرات توليد الكود من المدخلات المرئية. | يفوز Qwen |
| الاستدلال ثلاثي الأبعاد والمكاني | ✅ متقدم: يتعرف على موقع الجسم، والاحتجاب، وزاوية الرؤية؛ ويمكن من التثبيت المكاني ثلاثي الأبعاد. | ⚠️ يتعامل مع التخطيط المكاني عبر الصور، ولكن لا يوجد تثبيت ثلاثي الأبعاد أو ذكاء اصطناعي مدمج. | يفوز Qwen |
| فهم الفيديو | ✅ يتعامل مع مقاطع الفيديو التي تصل إلى ساعات طويلة مع سياق 256K–1M رمز؛ وتحليل زمني دقيق. | ⚠️ يدعم تقسيم الأحداث ولكن على الأرجح محدود بنافذة 66K رمز. | يفوز Qwen |
| نطاق التعرف البصري | ✅ مدرب لـ “التعرف على كل شيء”: المشاهير، أنيمي، الأنواع النادرة، المعالم، اللافتات، النصوص القديمة. | ⚠️ تحليل قوي للمشهد، ولكن لا يوجد ادعاء بالتعرف على الكيانات المتخصصة/النادرة. | يفوز Qwen |
| التعرف الضوئي على الحروف/استخراج النصوص | ✅ 32 لغة، متين تحت الضبابية أو الميلان، يدعم الأحرف النادرة/القديمة والتخطيطات المنظمة. | ⚠️ يستخرج المستندات الطويلة جيدًا ولكنه يفتقر إلى تنوع اللغات والنصوص النادرة. | يفوز Qwen |
| فهم النصوص | ✅ قابل للمقارنة مع نماذج اللغات الكبيرة البحتة؛ اندماج سلس بين الرؤية والنص دون فقدان الفهم. | ✅ مولد قوي مع مفتاح تبديل “وضع الاستدلال”؛ جودة لغة عالية. | قد يتعادلان |
| سهولة الوصول | متاح عبر API أو عرض تجريبي. | متاح عبر API أو عرض تجريبي و مساعد سطح المكتب يدعم الصور وملفات PDF والفيديوهات وما إلى ذلك. | يفوز GLM |
كيف يختلف Qwen3-VL-235B-A22B و GLM 4.5V من حيث البنية المعمارية؟
يبرز Qwen3-VL كخيار “الوزن الثقيل”، حيث يعطي الأولوية للحجم وسعة المعلومات: معاملاته الإجمالية البالغة 235 مليار، ونافذة السياق البالغة 256K رمز (قابلة للتوسيع إلى 1M رمز)، والأنواع المتخصصة للاستدلال، مما يجعله مثاليًا للمهام واسعة النطاق.
على النقيض، يركز GLM 4.5V على المرونة والكفاءة دون التضحية بالأداء. تصميمه الأكثر إحكاما بمعاملات 106 مليار، ونافذة السياق البالغة 128K رمز، والنموذج الموحد مع “وضع التفكير” القابل للتبديل، يحقق توازنًا بين السرعة والعمق.
| بُعد المقارنة | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|
| حجم النموذج وبنية MoE | إجمالي المعاملات: 235 مليار المعاملات النشطة لكل مدخل: 22 مليار |
إجمالي المعاملات: 106 مليار المعاملات النشطة لكل مدخل: 12 مليار |
| سعة نافذة السياق | أصلي: 256 ألف رمز قابل للتوسيع إلى: 1 مليون رمز |
أصلي: 128 ألف رمز |
| أوضاع الاستدلال والتعليمات | مفتاح تبديل وضع التفكير، يسمح للمستخدمين بالتوازن بين الاستجابات السريعة والاستدلال العميق. | مفتاح تبديل وضع التفكير، يسمح للمستخدمين بالتوازن بين الاستجابات السريعة والاستدلال العميق. |
| المعالجة البصرية | مرمز قائم على ViT + فك تشفير النصوص التحسينات: Interleaved-MRoPE (استدلال الفيديو)، ميزات رؤية مدمجة |
مرمز قائم على ViT + فك تشفير النصوص التحسين: محول نظيف لدمج الرؤية واللغة |
| السرعة | زمن الاستجابة من 1.8 إلى 2 ثانية | زمن الاستجابة من 0.3 إلى 1.5 ثانية |
| متطلبات الأجهزة | 8 وحدات معالجة رسومية من NVIDIA H200. | وحدة معالجة رسومية واحدة سعتها 80 جيجابايت (مثل NVIDIA A100/H100 80GB) بدقة 16 بت |
إذًا، أي نموذج يؤدي أداءً أفضل: Qwen3-VL-235B-A22B أم GLM 4.5V؟
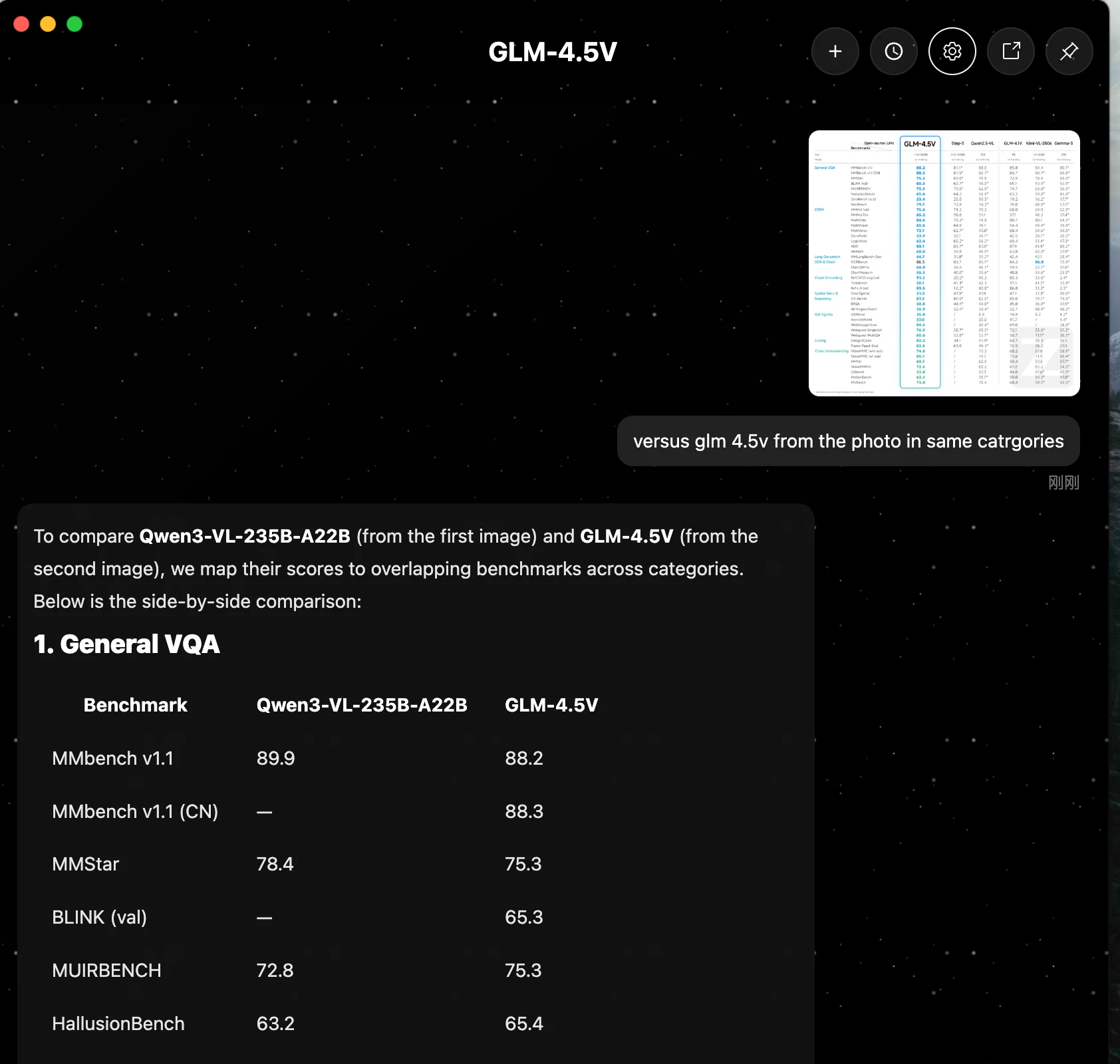
يتفوق Qwen3-VL-235B-A22B بشكل عام في الاستدلال الأساسي، ومعالجة المستندات، وتوليد الكود. يؤدي GLM 4.5V أداءً متقاربًا في عدة مهام ولكنه لا يتفوق على Qwen في أي من مقاييس الأداء المعروضة.
| الفئة | مقياس الأداء | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|---|
| 1. أسئلة وأجوبة بصرية عامة | MMbench v1.1 | 89.9 | 88.2 |
| MMStar | 78.4 | 75.3 | |
| MUIRBENCH | 72.8 | 75.3 | |
| HallusionBench | 63.2 | 65.4 | |
| 2. العلوم والتكنولوجيا والهندسة والرياضيات والألغاز | MMMU (val) | 78.7 | 75.4 |
| MMMU Pro | 68.1 | 65.2 | |
| MathVista | 84.9 | 84.6 | |
| MathVision | 66.5 | 65.6 | |
| MathVerse | 72.5 | 72.1 | |
| AI2D | 89.7 | 88.1 | |
| 3. المستندات الطويلة والتعرف الضوئي على الحروف/الرسوم البيانية | MMLongBench-Doc | 57.0 | 44.7 |
| OCRBench | 920.0* | 86.5 | |
| 4. البرمجة | Design2Code | 92.0 | 82.2 |
| 5. فهم الفيديو | VideoMME (w/o sub) | 79.2 | 74.6 |
يمكنك أيضًا استخدام مفتاح API من Novita AI للوصول إلى مساعد سطح المكتب لـ GLM مجانًا—لا يلزم أي دفعة، على عكس الموقع الرسمي!
تم تصميم سطح المكتب لنماذج GLM متعددة الوسائط (GLM-4.5V، متوافق مع GLM-4.1V)، ويدعم المحادثات التفاعلية مع النصوص والصور والفيديوهات وملفات PDF وملفات PPT والمزيد. يتصل بواجهة برمجة تطبيقات GLM متعددة الوسائط لتمكين الخدمات الذكية عبر سيناريوهات مختلفة.
الإعدادات:
اسم النموذج: zai-org/glm-4.5v
عنوان URL لواجهة برمجة التطبيقات: https://api.novita.ai/openai
نقطة النهاية: /v1/chat/completions
مفتاح API: من Novita AI
احصل على مفتاح API وجرب مساعد سطح المكتب لـ GLM مجانًا الآن!
كيفية الوصول إلى Qwen3-VL-235B-A22B و GLM 4.5V بطريقة رخيصة وسريعة؟
تقدم Novita AI واجهات برمجة تطبيقات (APIs) لـ Qwen3-VL بنافذة سياق 131 ألف رمز بسعر 0.98 دولار لكل مدخل و 3.95 دولار لكل مخرج. كما تقدم واجهات برمجة تطبيقات لـ GLM-4.6V بنافذة سياق 208 ألف رمز بسعر 0.60 دولار لكل مدخل و 2.20 دولار لكل مخرج، مع دعم المخرجات المنظمة واستدعاء الوظائف.
1. واجهة الويب (الأسهل للمبتدئين)
2. الوصول عبر واجهة برمجة التطبيقات (للمطورين)
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات
قم بتثبيت واجهة برمجة التطبيقات باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، استورد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات باستخدام مفتاح API الخاص بك لبدء التفاعل مع نماذج اللغات الكبيرة من Novita AI. هذا مثال على استخدام واجهة برمجة تطبيقات إكمال المحادثات لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. النشر المحلي (للمستخدمين المتقدمين)
المتطلبات:
- Qwen3-VL-235B-A22B: 8 وحدات معالجة رسومية من NVIDIA H200.
- GLM 4.5V: وحدة معالجة رسومية واحدة سعتها 80 جيجابايت (مثل NVIDIA A100/H100 80GB) بدقة 16 بت
خطوات التثبيت:
- تنزيل أوزان النموذج من HuggingFace أو ModelScope
- اختر إطار الاستدلال: مدعوم من vLLM أو SGLang
- اتبع دليل النشر في مستودع GitHub الرسمي
4. التكامل
استخدام واجهة سطر الأوامر (CLI) مثل Trae و Claude Code و Qwen Code
إذا كنت تريد استخدام النماذج الرائدة من Novita AI (مثل Qwen3-Coder و Kimi K2 و DeepSeek R1) لمساعدات البرمجة بالذكاء الاصطناعي في بيئتك المحلية أو بيئة التطوير المتكاملة (IDE)، فإن العملية بسيطة: احصل على مفتاح API الخاص بك، قم بتثبيت الأداة، قم بتكوين متغيرات البيئة، وابدأ البرمجة.
للحصول على أوامر الإعداد التفصيلية والأمثلة، راجع الدروس الرسمية:
- Trae : دليل خطوة بخطوة للوصول إلى نماذج الذكاء الاصطناعي في بيئة التطوير المتكاملة الخاصة بك
- Claude Code:كيفية استخدام Kimi-K2 في Claude Code على ويندوز وماك ولينكس
- Qwen Code:كيفية استخدام واجهة برمجة تطبيقات متوافقة مع OpenAI في Qwen Code (إعداد في 60 ثانية!)
سير عمل متعدد الوكلاء باستخدام حزمة تطوير وكلاء OpenAI
قم ببناء أنظمة متعددة الوكلاء متقدمة من خلال دمج Novita AI مع حزمة تطوير وكلاء OpenAI:
- التوصيل والتشغيل: استخدم نماذج اللغات الكبيرة من Novita AI في أي سير عمل لوكلاء OpenAI.
- يدعم التسليمات، والتوجيه، واستخدام الأدوات: صمم وكلاء يمكنهم تفويض المهام، أو فرزها، أو تشغيل الوظائف، وكلها مدعومة بنماذج Novita AI.
- التكامل مع بايثون: ببساطة اضبط نقطة نهاية حزمة التطوير إلى
https://api.novita.ai/v3/openaiواستخدم مفتاح API الخاص بك.
توصيل واجهة برمجة التطبيقات على منصات طرف ثالث
واجهة برمجة تطبيقات متوافقة مع OpenAI: استمتع بالهجرة والتكامل بدون متاعب مع أدوات مثل Cline و Cursor، المصممة لمعيار واجهة برمجة تطبيقات OpenAI.
Hugging Face: استخدم النماذج في Spaces، أو خطوط الأنابيب، أو مع مكتبة Transformers عبر نقاط نهاية Novita AI.
أطر الوكلاء والتنسيق: اربط Novita AI بسهولة بالمنصات الشريكة مثل Continue، و AnythingLLM،LangChain، و Dify و Langflow عبر الموصلات الرسمية وأدلة التكامل خطوة بخطوة.
يُظهر Qwen3-VL-235B-A22B نقاط قوة واضحة في الاستدلال المتقدم، والبرمجة المرئية، والتعرف الضوئي على الحروف متعدد اللغات، ومعالجة السياق الطويل—مما يجعله الخيار الأمثل لسير العمل المتطلبة والمهام متعددة الوسائط.
أما GLM 4.5V، فهو على الرغم من تأخره قليلاً في الأداء الخام، أخف وزنًا و يقدم مساعد سطح المكتب، وسرعة استدلال أسرع، وقدرة أكبر على الاستخدام بدون تكوين—خاصة للمطورين والشركات الناشئة. لمعظم حالات الاستخدام، يعتبر Qwen3-VL-235B-A22B مثالياً للعمق والتعقيد، بينما يتفوق GLM 4.5V في سهولة الاستخدام والمرونة.
الأسئلة الشائعة
هل يمكن استخدام GLM 4.5V بدون اتصال بالإنترنت أو خارج المتصفح؟
نعم، يدعم GLM 4.5V مساعد سطح المكتب المجاني (عبر Novita AI) الذي يسمح للمستخدمين بالتفاعل مع النصوص والصور والفيديوهات وملفات PDF محليًا—وهو شيء لا يقدمه Qwen3-VL-235B-A22B بشكل أصلي.
ما هي الطريقة الأرخص والأسرع لتجربة Qwen3-VL-235B-A22B و GLM 4.5V؟
واجهة برمجة تطبيقات Qwen3-VL: سياق 131 ألف رمز، 0.98 دولار لكل مدخل، 3.95 دولار لكل مخرج
واجهة برمجة تطبيقات GLM-4.6V: سياق 208 ألف رمز، 0.60 دولار لكل مدخل، 2.20 دولار لكل مخرج، مع مخرجات منظمة واستدعاء الوظائف
أي نموذج يحقق أداءً أفضل في تقييمات المقاييس—Qwen3-VL-235B-A22B أم GLM 4.5V؟
يحقق Qwen3-VL-235B-A22B درجات أعلى باستمرار من GLM 4.5V في فئات مثل الاستدلال في العلوم والتكنولوجيا والهندسة والرياضيات (مثل MMMU)، وتحليل المستندات الطويلة (MMLongBench-Doc)، والتعرف الضوئي على الحروف (OCRBench)، والبرمجة (Design2Code). يؤدي GLM 4.5V أداءً جيدًا ولكنه لا يتفوق على Qwen في أي من المقاييس المدرجة.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة وحدات معالجة رسومية (GPU) بأسعار معقولة وموثوقة للبناء والتوسع.



