

小規模企業が文書解析、カスタマーサポート、ビジュアル自動化、コーディング支援などのタスクにAIを導入しようとする際、Qwen3-VL-235B-A22B と GLM 4.5V のような強力なオープンソースモデルの選択は圧倒されることがあります。パフォーマンス、コスト、アクセシビリティ、導入の難易度の本当の違いは何でしょうか?
この記事では、アーキテクチャ、アプリケーション機能、パフォーマンスベンチマーク、価格、アクセス方法の比較を詳しく解説し、どのモデルがあなたのビジネスに最適かを明確に判断できるようにします。インテリジェントなワークフローを構築する場合、ローカルにデプロイする場合、APIを呼び出す場合など、このガイドは情報に基づいた自信のある選択をサポートします。
Qwen3-VL-235B-A22B と GLM 4.5V はあなたの小規模ビジネスに本当に何ができるのか?
どのモデルがあなたのワークフローに最適か確認してみませんか?
Qwen3-VL-235B-A22B と GLM 4.5V は両方とも Novita AI から無料のオンラインデモを提供しています!
| 応用分野 | Qwen3-VL-235B-A22B | GLM 4.5V | 勝者 |
|---|---|---|---|
| GUI操作 | PC/モバイルUIを操作し、インターフェース要素を理解し、ツールを呼び出す。 | 画面読み取りと基本的なデスクトップ操作をサポート。 | 互角 |
| ビジュアルからコードへの生成 | ✅ スクリーンショットや動画をHTML、CSS、JS、Draw.io図に変換。 | ❌ ビジュアルからコードへの変換機能は非公開。 | Qwenの勝利 |
| 3D・空間推論 | ✅ 高度: 物体の位置、遮蔽、視点を認識; 3Dグラウンディングを可能に。 | ⚠️ 画像間の空間レイアウトを処理するが、3Dグラウンディングや具現化AIはなし。 | Qwenの勝利 |
| 動画理解 | ✅ 256K~1Mトークンのコンテキストで何時間もの動画を処理; きめ細かい時間分析。 | ⚠️ イベントセグメンテーションをサポートするが、66Kトークンウィンドウにより制限される可能性あり。 | Qwenの勝利 |
| ビジュアル認識範囲 | ✅ 「何でも認識する」ように訓練: 有名人、アニメ、希少種、ランドマーク、標識、古代文字。 | ⚠️ シーン分析は強力だが、ニッチ/希少エンティティ認識の主張はなし。 | Qwenの勝利 |
| OCR/テキスト抽出 | ✅ 32言語、ぼやけや傾きに対して堅牢、希少/古代文字と構造化レイアウトをサポート。 | ⚠️ 長文書の抽出は良好だが、言語と希少テキストの幅に欠ける。 | Qwenの勝利 |
| テキスト理解 | ✅ 純粋LLMに匹敵; 理解力の低下なしに流暢な視覚-テキスト融合。 | ✅ 「推論モード」切り替え可能な強力なジェネレーター; 高い言語品質。 | 互角 |
| アクセスの容易さ | APIまたはデモで利用可能。 | APIまたはデモ、および画像、PDF、動画などをサポートするデスクトップアシスタントで利用可能。 | GLMの勝利 |
Qwen3-VL-235B-A22B と GLM 4.5V はアーキテクチャでどう違うのか?
Qwen3-VL は「ヘビー級」の選択肢として際立っており、スケールと情報容量を優先しています。総パラメータ数235B、256K(1Mに拡張可能)トークンのコンテキストウィンドウ、特殊な推論バリアントにより、大規模タスクに最適です。
対照的に、GLM 4.5V はパフォーマンスを犠牲にすることなく柔軟性と効率性を重視しています。よりコンパクトな106Bパラメータ設計、128Kトークンのコンテキストウィンドウ、切り替え可能な「Thinking Mode」を備えた統一モデルにより、速度と深さのバランスを実現しています。
| 比較次元 | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|
| モデルサイズとMoEアーキテクチャ | 総パラメータ: 235B 入力あたりの活性パラメータ: 22B |
総パラメータ: 106B 入力あたりの活性パラメータ: 12B |
| コンテキストウィンドウ容量 | ネイティブ: 256Kトークン 拡張可能: 1Mトークン |
ネイティブ: 128Kトークン |
| 推論と指示モード | Thinking Mode スイッチにより、ユーザーは迅速な応答と深い推論のバランスを調整できます。 | Thinking Mode スイッチにより、ユーザーは迅速な応答と深い推論のバランスを調整できます。 |
| ビジュアル処理 | ViTベースのエンコーダ + テキストデコーダ 拡張: Interleaved-MRoPE(動画推論)、融合視覚特徴 |
ViTベースのエンコーダ + テキストデコーダ 拡張: 視覚言語融合のためのクリーンなアダプタ |
| 速度 | レイテンシ: 1.8~2秒 | レイテンシ: 0.3~1.5秒 |
| ハードウェア要件 | NVIDIA H200 GPU 8基。 | 16ビット精度で単一の80GB GPU(例: NVIDIA A100/H100 80GB 1基) |
では、どちらのモデルが優れているのか? Qwen3-VL-235B-A22B か GLM 4.5V か?
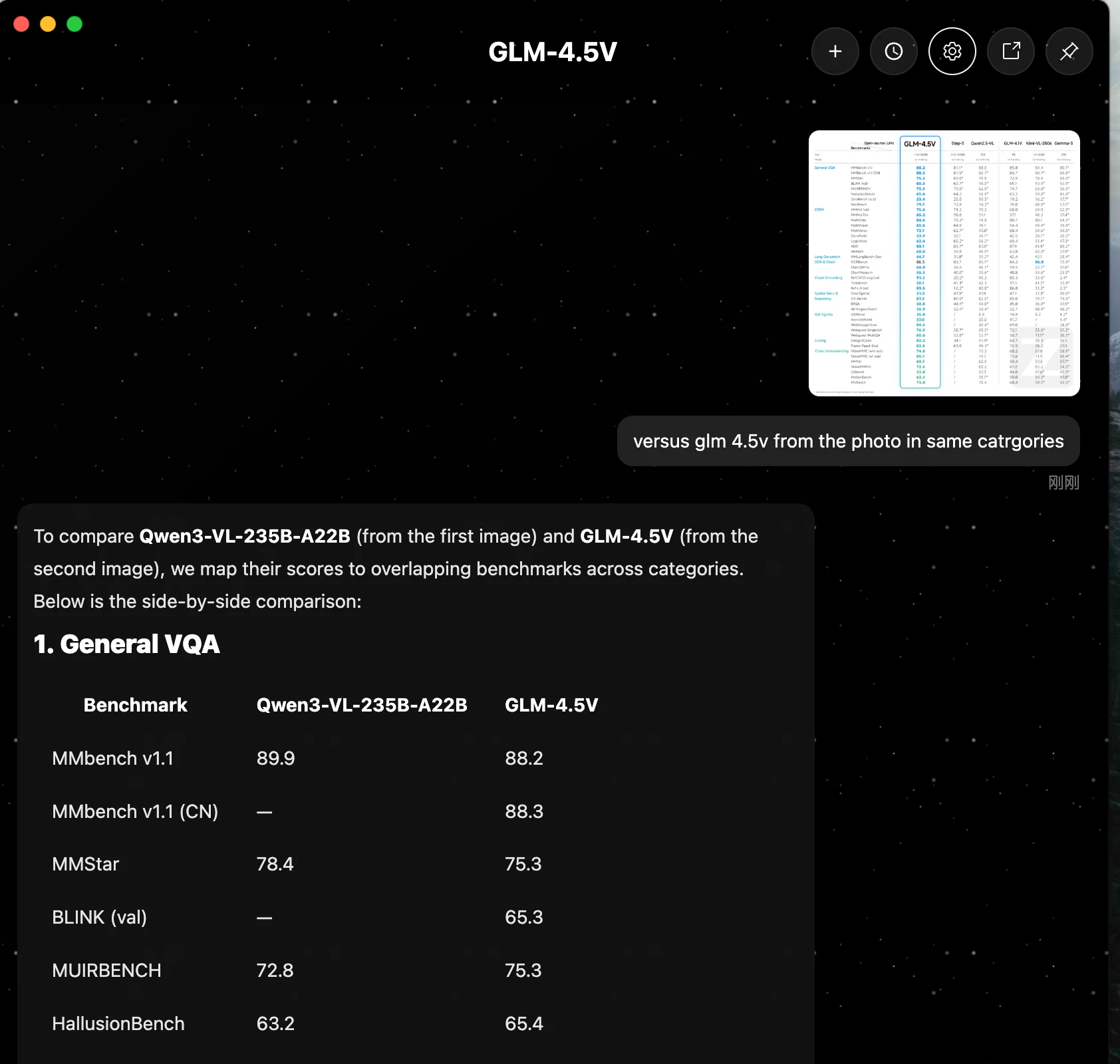
Qwen3-VL-235B-A22B は、コア推論、文書処理、コード生成において概ねリードしています。GLM 4.5V はいくつかのタスクで接近したパフォーマンスを示しますが、示されたベンチマークのいずれにおいてもQwenを上回っていません。
| カテゴリ | ベンチマーク | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|---|
| 1. 一般VQA | MMbench v1.1 | 89.9 | 88.2 |
| MMStar | 78.4 | 75.3 | |
| MUIRBENCH | 72.8 | 75.3 | |
| HallusionBench | 63.2 | 65.4 | |
| 2. STEM・パズル | MMMU (val) | 78.7 | 75.4 |
| MMMU Pro | 68.1 | 65.2 | |
| MathVista | 84.9 | 84.6 | |
| MathVision | 66.5 | 65.6 | |
| MathVerse | 72.5 | 72.1 | |
| AI2D | 89.7 | 88.1 | |
| 3. 長文書・OCR/チャート | MMLongBench-Doc | 57.0 | 44.7 |
| OCRBench | 920.0* | 86.5 | |
| 4. コーディング | Design2Code | 92.0 | 82.2 |
| 5. 動画理解 | VideoMME (w/o sub) | 79.2 | 74.6 |
Novita AIのAPIキーを使用すると、GLMのデスクトップアシスタントを無料で利用できます。公式サイトとは異なり、支払い不要です!
デスクトップはGLMシリーズのマルチモーダルモデル(GLM-4.5V、GLM-4.1V互換)向けに設計されており、テキスト、画像、動画、PDF、PPTなどとの対話的な会話をサポートします。GLMマルチモーダルAPIに接続して、さまざまなシナリオでインテリジェントサービスを実現します。
設定: モデル名: zai-org/glm-4.5v API URL: https://api.novita.ai/openai エンドポイント: /v1/chat/completions APIキー: Novita AIから取得
APIキーを取得して無料のGLMデスクトップアシスタントを今すぐ試す!
Qwen3-VL-235B-A22B と GLM 4.5V に安く素早くアクセスする方法
Novita AIは、131KコンテキストウィンドウのQwen3-VL APIを入力$0.98、出力$3.95で提供しています。また、GLM-4.6V APIは208Kコンテキストウィンドウで入力$0.60、出力$2.20、構造化出力と関数呼び出しをサポートしています。
1. Webインターフェース(初心者に最適)
2. APIアクセス(開発者向け)
ステップ1: ログインしてモデルライブラリにアクセス

ステップ2: モデルを選択

ステップ3: 無料トライアルを開始
ステップ4: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動すると、画像に示されているようにAPIキーをコピーできます。

ステップ5: APIをインストール
お使いのプログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーでAPIを初期化して、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. ローカルデプロイメント(上級者向け)
要件:
- Qwen3-VL-235B-A22B: NVIDIA H200 GPU 8基。
- GLM 4.5V: 16ビット精度で単一の80GB GPU(例: NVIDIA A100/H100 80GB 1基)
インストール手順:
- モデル重みをダウンロード: HuggingFace または ModelScope から
- 推論フレームワークを選択: vLLM または SGLang をサポート
- 公式GitHubリポジトリのデプロイガイドに従う
4. 統合
CLI(Trae、Claude Code、Qwen Codeなど)の使用
Novita AIのトップモデル(Qwen3-Coder、Kimi K2、DeepSeek R1など)をローカル環境やIDEでAIコーディング支援に使用したい場合、プロセスは簡単です。APIキーを取得し、ツールをインストールし、環境変数を設定し、コーディングを開始するだけです。
詳細な設定コマンドと例については、公式チュートリアルをご確認ください:
- Trae : IDEでAIモデルにアクセスするためのステップバイステップガイド
- Claude Code: Windows、Mac、LinuxでClaude CodeでKimi-K2を使用する方法
- Qwen Code: Qwen CodeでOpenAI互換APIを使用する方法(60秒セットアップ!)
OpenAI Agents SDK を使用したマルチエージェントワークフロー
Novita AIをOpenAI Agents SDKと統合して、高度なマルチエージェントシステムを構築します:
- プラグアンドプレイ: 任意のOpenAI AgentsワークフローでNovita AIのLLMを使用。
- ハンドオフ、ルーティング、ツール使用をサポート: 委任、トリアージ、関数実行が可能なエージェントを設計でき、すべてNovita AIのモデルを搭載。
- Python統合: SDKエンドポイントを
https://api.novita.ai/v3/openaiに設定し、APIキーを使用するだけ。
サードパーティプラットフォームでのAPI接続
OpenAI互換API: ClineやCursorなどのツールとのシームレスな移行と統合を、OpenAI API標準向けに設計。
Hugging Face: Spaces、パイプライン、またはTransformersライブラリで、Novita AIエンドポイントを介してモデルを使用。
エージェント&オーケストレーションフレームワーク: 公式コネクタとステップバイステップの統合ガイドを通じて、Continue、AnythingLLM、LangChain、Dify、LangflowなどのパートナープラットフォームとNovita AIを簡単に接続。
Qwen3-VL-235B-A22B は、高度な推論、ビジュアルコーディング、多言語OCR、長文脈処理において明確な強みを示しており、要求の厳しいワークフローやマルチモーダルタスクに最適な選択肢です。
GLM 4.5V は生のパフォーマンスではやや劣るものの、より軽量で、デスクトップアシスタント、高速な推論速度、そして特に開発者やスタートアップにとって幅広いプラグアンドプレイの使いやすさを提供します。ほとんどのユースケースでは、Qwen3-VL-235B-A22B は深さと複雑さに最適であり、GLM 4.5V は使いやすさと柔軟性に優れています。
よくある質問(FAQ)
GLM 4.5Vはオフラインやブラウザ外でも使用できますか?
はい、GLM 4.5Vは無料のデスクトップアシスタント(Novita AI経由)をサポートしており、ユーザーはテキスト、画像、動画、PDFとローカルで対話できます。これはQwen3-VL-235B-A22Bがネイティブに提供していない機能です。
Qwen3-VL-235B-A22BとGLM 4.5Vを試す最も安くて速い方法は?
Qwen3-VL API: 131Kコンテキスト、入力$0.98、出力$3.95 GLM-4.6V API: 208Kコンテキスト、入力$0.60、出力$2.20、構造化出力と関数呼び出し対応
ベンチマーク評価ではどちらのモデルが優れているのか? Qwen3-VL-235B-A22B または GLM 4.5V?
Qwen3-VL-235B-A22B は、STEM推論(例: MMMU)、長文書分析(MMLongBench-Doc)、OCR(OCRBench)、コーディング(Design2Code)などのカテゴリで一貫してGLM 4.5Vより高いスコアを示しています。GLM 4.5Vは良好なパフォーマンスを示しますが、リストされたベンチマークのいずれにおいてもQwenを上回っていません。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできる方法を提供するとともに、構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。



