

Destaques Principais
Diferença Central: Gemma 3 27B é um modelo multimodal versátil e eficiente, capaz de processar tanto imagens quanto texto. Llama 3.3 70B é um modelo apenas texto, maior e otimizado para raciocínio complexo e tarefas de seguir instruções.
Desempenho: Llama 3.3 70B geralmente lidera em benchmarks focados em texto para codificação, seguir instruções e conhecimento geral. Gemma 3 27B mostra forte desempenho em matemática e oferece a vantagem única de compreensão visual.
Acessibilidade de Hardware: Gemma 3 27B é projetado para eficiência e é considerado um dos modelos mais capazes que podem ser executados em uma única GPU de ponta, tornando-o mais acessível para implantação local. O tamanho maior do Llama 3.3 70B exige hardware mais substancial, frequentemente necessitando de configurações com múltiplas GPUs.
Melhor Para: Escolha Gemma 3 27B para aplicações que exigem multimodalidade, amplo suporte a idiomas e implantação eficiente em hardware limitado. Opte por Llama 3.3 70B para aplicações empresariais com foco intenso em texto, onde o desempenho de ponta é crítico.
O Gemma 3 27B do Google e o Llama 3.3 70B da Meta são modelos de IA de código aberto de alto nível. Este guia rápido compara seus pontos fortes para que você escolha o certo para seu projeto rapidamente.
Introdução Básica: Gemma 3 27B vs. Llama 3.3 70B
Vamos começar com uma visão fundamental do que diferencia esses dois modelos.
| Característica | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Desenvolvedor | Meta | |
| Data de Lançamento | 12 de março de 2025 | 6 de dezembro de 2024 |
| Parâmetros | 27 Bilhões | 70 Bilhões |
| Modalidade | Multimodal (Entrada de Imagem e Texto) | Apenas Texto |
| Arquitetura | Atenção Local-Global Intercalada | Transformer Otimizado com GQA |
| Dados de Treinamento | 14 Trilhões de Tokens | Mais de 15 Trilhões de Tokens |
| Janela de Contexto | 128.000 Tokens | 128.000 Tokens |
| Multilíngue | Suporta mais de 140 idiomas | Suporte oficial para 8 idiomas |
| Extensões | Saídas Estruturadas, Chamada de Função com Langchain | Chamada de Função |
A característica marcante do Gemma 3 é sua multimodalidade, permitindo interpretar informações visuais junto com texto. O Llama 3.3 70B, embora apenas texto, tem mais que o dobro do número de parâmetros, o que geralmente se traduz em geração de texto e raciocínio mais nuançados e poderosos.
Desempenho: Uma História de Duas Especializações
| Benchmark | Gemma 3 27B | Llama 3․3 70B |
|---|---|---|
| MMLU-Pro (Raciocínio e Conhecimento) | 67 | 71 |
| MATH-500 (Raciocínio Quantitativo) | 88 | 77 |
| LiveCodeBench (Codificação) | 14 | 29 |
| HumanEval (Codificação) | 89 | 86 |
| GPQA Diamond (Raciocínio Científico) | 42.4 | 49 |
| MGSM | 74.3 | 91.1 |
| Vision QA (MMMU) | 64.9 | apenas texto |
Conclusões rápidas:
- Linguagem pura e codificação: Llama 3 vence por ampla margem.
- Tarefas visuais e OCR: apenas o Gemma 3 as suporta.
- Raciocínio e conhecimento: ambos são competitivos; Llama 3 leva vantagem em matemática e código, Gemma 3 se mantém na amplitude multilíngue.
Se você quiser verificar a capacidade do Gemma 3 em Modelos VL, confira este artigo: Gemma 3 27B vs Qwen2.5-VL: Melhor para Perguntas e Respostas de Fotos com IA?
Eficiência de Recursos: Custo e Hardware
É aqui que os dois modelos mais divergem, impactando a acessibilidade e a estratégia de implantação.
1. Preço da API (pague conforme o uso público)
| Provedor | Gemma 3 27B | Llama 3․3 70B |
|---|---|---|
| Novita AI | $0,119 / M tokens de entrada e $0,20 / M tokens de saída | $0,13 / M tokens de entrada e $0,39 / M tokens de saída |
| Deepinfra | $0,09 / M tokens de entrada e $0,17 / M tokens de saída | $0,23 / M tokens de entrada e $0,40 / M tokens de saída |
| Parasail | $1,20 / M tokens de entrada e $1,20 / M tokens de saída | $0,10 / M tokens de entrada e $0,40 / M tokens de saída |
Ao avaliar a eficiência da API, você deve olhar além apenas do custo por token—a velocidade de saída do modelo e a latência de resposta são igualmente cruciais para aplicações do mundo real.
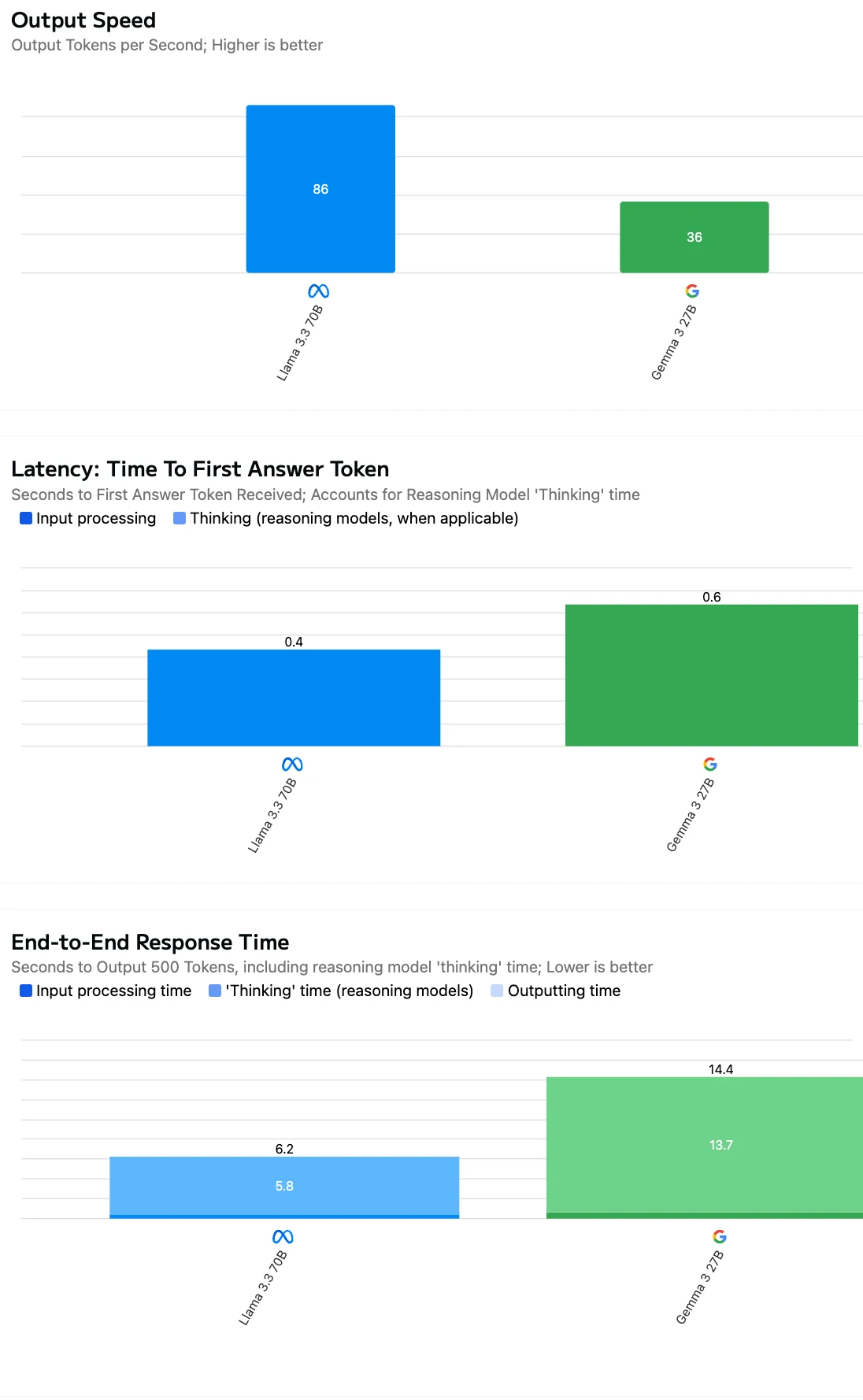
Fonte: Artificial Analysis
Ou você pode usar diretamente o playground gratuito para testar a velocidade em cada tarefa!
Experimente Gemma 3 e Llama 3 Agora!
2. Hardware para inferência local
Llama 3.3 70B:
- VRAM: 24GB (mínimo) para quantização de 4 bits; 80GB+ (A100/H100) para precisão total.
- Recomendado: 2x NVIDIA A100/H100 (80GB).
- RAM: 32–64GB+
- Armazenamento: 250GB+
- Configuração Doméstica: Desafiador, altas necessidades de energia e resfriamento.
Gemma 3 27B:
- VRAM: Cabe em 1x H100 (80GB) ou 3–4x RTX 4090 (24GB).
- RAM: ~32–64GB
- Armazenamento: 54GB (pesos); 72,7GB (com cache KV)
- Configuração Doméstica: Mais fácil, mais viável para desktops avançados.
Preços de rua aproximados (2º trimestre de 2025):
- RTX 4090 24 GB: ~$1.600
- NVIDIA H100 80 GB: ~$29.000
3. Taxas spot de GPU em nuvem
| Tipo de GPU | Sob Demanda | Endpoints Dedicados |
|---|---|---|
| A100 80 GB | $1,60/hora | - |
| H100 80 GB | $2,56/hora | $2,41/hora |
| RTX4090 | $1,05/hora (3 placas) | $0,61/hora |
Experimente GPU com Custo Eficiente Agora
A conclusão é clara: Gemma 3 27B reduz a barreira de entrada para executar um modelo poderoso localmente, enquanto Llama 3.3 70B é mais voltado para acesso via API na nuvem ou organizações com investimentos significativos em hardware local.
Aplicações: Escolhendo a Ferramenta Certa para o Trabalho
Os perfis distintos desses modelos os tornam adequados para diferentes aplicações.
| Caso de Uso | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Chatbots / Assistentes de IA | Suporta 140+ idiomas, bem adequado para aplicações globais de IA conversacional multilíngue | Excelente em seguir instruções, ideal para assistentes exigentes em inglês e multilíngues |
| Geração de Código | Tem bom desempenho em tarefas de código básicas a intermediárias; adequado para prototipagem e projetos educacionais | Alcança 88% no HumanEval; forte em geração de código complexo e depuração para ferramentas de desenvolvedor |
| Redação de Textos Longos | Lida com até 128k tokens, permitindo processamento eficiente de documentos longos, relatórios ou pesquisas | Também suporta contexto de 128k–130k tokens para tarefas de redação estendida e sumarização |
| Suporte a Imagens | Entrada multimodal nativa (texto + imagens) com codificador SigLIP, permitindo OCR, moderação de conteúdo e perguntas e respostas visuais | Sem capacidade multimodal nativa; limitado a entradas apenas de texto |
| Implantação em Dispositivo / Borda | Versões leves 4B e 9B permitem implantação local e na borda eficiente para indivíduos e PMEs | Variante 8B disponível para uso na borda; modelo 70B requer hardware de ponta |
Como Acessar o Gemma 3 27B e o Llama 3.3 70B via API da Novita?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login em sua conta e clique no botão Model Library .

Experimente Gemma 3 e Llama 3 Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entrando na página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session__FaCoze-7Vk7DBH0noVpc42JxmWIV4gCRV31Rz66AmBkUz5ZglF3sYVyGw3ZPlr08zck6KQHI51Scef6kEm8cQ==",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
A escolha entre Gemma 3 27B e Llama 3.3 70B não é sobre qual modelo é “melhor”, mas qual é melhor para você.
Gemma 3 27B representa um salto em versatilidade e eficiência de IA. Ele traz poderosas capacidades multimodais para um hardware mais acessível, capacitando uma nova onda de aplicações que podem ver e entender o mundo. É a ferramenta perfeita para inovadores que precisam de flexibilidade e desejam executar IA de ponta sem um orçamento empresarial.
Llama 3.3 70B é o campeão indiscutível do desempenho puro baseado em texto em escala. Ele oferece poder incomparável para raciocínio, seguir instruções e tarefas de codificação. Combinado com seu custo de API incrivelmente baixo, é a escolha definitiva para empresas e desenvolvedores que constroem aplicações robustas e de alto volume onde a excelência linguística é o objetivo principal.
Em última análise, sua decisão dependerá de uma simples troca: você precisa da versatilidade multimodal e eficiência de hardware do Gemma, ou do poder bruto de processamento de texto e custo-benefício da API do Llama?
Perguntas Frequentes
O Gemma 3 27B pode ser executado em um Mac?
Sim! Variantes menores do Gemma (por exemplo, 4B) suportam Apple Silicon via mlx-vlm. O modelo 27B requer aceleração de GPU (por exemplo, APIs na nuvem).
Qual modelo é mais rápido para chatbots em tempo real?
O Llama 3.3 70B se destaca em cenários de baixa latência. O processamento de visão do Gemma adiciona uma pequena sobrecarga.
O Llama 3.3 70B é realmente gratuito?
Sim—é gratuito no playground da novita ai. No entanto, a implantação local exige hardware caro, enquanto as APIs incorrem em custos baseados em tokens.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem de GPU acessível e confiável para construir e escalar.
Leitura Recomendada
- [Por que os Requisitos de VRAM do LLaMA 3.3 70B são um Desafio para Servidores Domésticos?](http://Por que os Requisitos de VRAM do LLaMA 3.3 70B são um Desafio para Servidores Domésticos?)
- Qwen 2.5 72b vs Llama 3.3 70b: Qual Modelo Atende Suas Necessidades?
- O Llama 3.3 70B é Realmente Comparável ao Llama 3.1 405B?



