

重點摘要
**核心差異 :Gemma 3 27B 是一款多功能且高效的 ** 多模態 ** 模型,能夠同時處理影像與文字。Llama 3.3 70B 則是規模較大的 ** 純文字 強悍模型,專為複雜推理與指令遵循任務而設計。
效能表現:Llama 3.3 70B 在程式碼撰寫、指令遵循和一般知識等純文字標竿測試中整體領先。Gemma 3 27B 在數學方面表現強勁,並具備獨特的視覺理解優勢。
硬體門檻:Gemma 3 27B 專為效率而設計,號稱是能在單張高階 GPU 上運行的最強大模型之一,因此更適合本地端部署。Llama 3.3 70B 規模更大,需要更強大的硬體,通常需要多 GPU 配置。
**最佳適用場景 **:若應用需要多模態能力、廣泛語言支援,以及在有限硬體上高效部署,請選擇 Gemma 3 27B。若您正在打造企業級、以純文字為主且要求頂尖效能的應用,則應選擇 Llama 3.3 70B。
Google 的 Gemma 3 27B 與 Meta 的 Llama 3.3 70B 都是頂尖的開源 AI 模型。本快速指南將比較它們的優勢,協助您快速為專案挑選合適的模型。
基本介紹:Gemma 3 27B vs. Llama 3.3 70B
首先從基本層面了解這兩款模型的差異。
| 功能特性 | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| 開發者 | Meta | |
| 發布日期 | 2025 年 3 月 12 日 | 2024 年 12 月 6 日 |
| 參數規模 | 270 億 | 700 億 |
| **模態 ** | ** 多模態 **(影像和文字輸入) | ** 純文字** |
| 架構 | 交錯局部-全局注意力 | 經最佳化的 Transformer 搭配 GQA |
| 訓練資料 | 14 兆個 token | 超過 15 兆個 token |
| 上下文視窗 | 128,000 個 token | 128,000 個 token |
| 多語言支援 | 支援超過 140 種語言 | 官方支援 8 種語言 |
| 擴充功能 | 結構化輸出、與 Langchain 的函式呼叫 | 函式呼叫 |
Gemma 3 最突出的特色是多模態能力,能同時解讀視覺資訊與文字。Llama 3.3 70B 雖然僅支援純文字,但參數規模超過兩倍,這通常意味著更細膩、更強大的文字生成與推理能力。
效能表現:各有所長的專精領域
| 標竿測試 | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| MMLU-Pro(推理與知識) | 67 | 71 |
| MATH-500(量化推理) | 88 | 77 |
| LiveCodeBench(程式碼撰寫) | 14 | 29 |
| HumanEval(程式碼撰寫) | 89 | 86 |
| GPQA Diamond(科學推理) | 42.4 | 49 |
| MGSM | 74.3 | 91.1 |
| 視覺問答(MMMU) | 64.9 | 僅限文字 |
快速重點整理:
- 純語言與程式碼:Llama 3 大幅領先。
- 視覺任務與 OCR:僅 Gemma 3 支援。
- 推理與知識:兩者皆有競爭力;Llama 3 在數學和程式碼方面略勝一籌,而 Gemma 3 在多語言廣度上表現不俗。
若想了解 Gemma 3 在視覺語言模型上的能力,請參考此文:Gemma 3 27B vs Qwen2.5-VL:最適合 AI 圖片問答的模型?
資源效率:成本與硬體需求
這是兩款模型差異最顯著的面向,直接影響可近性與部署策略。
1. API 定價(公開隨用隨付制)
| 供應商 | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Novita AI | 輸入 $0.119 / 百萬 token,輸出 $0.20 / 百萬 token | 輸入 $0.13 / 百萬 token,輸出 $0.39 / 百萬 token |
| Deepinfra | 輸入 $0.09 / 百萬 token,輸出 $0.17 / 百萬 token | 輸入 $0.23 / 百萬 token,輸出 $0.40 / 百萬 token |
| Parasail | 輸入 $1.20 / 百萬 token,輸出 $1.20 / 百萬 token | 輸入 $0.10 / 百萬 token,輸出 $0.40 / 百萬 token |
評估 API 效率時,不應只看每 token 成本——模型輸出速度與回應延遲對實際應用同樣至關重要。
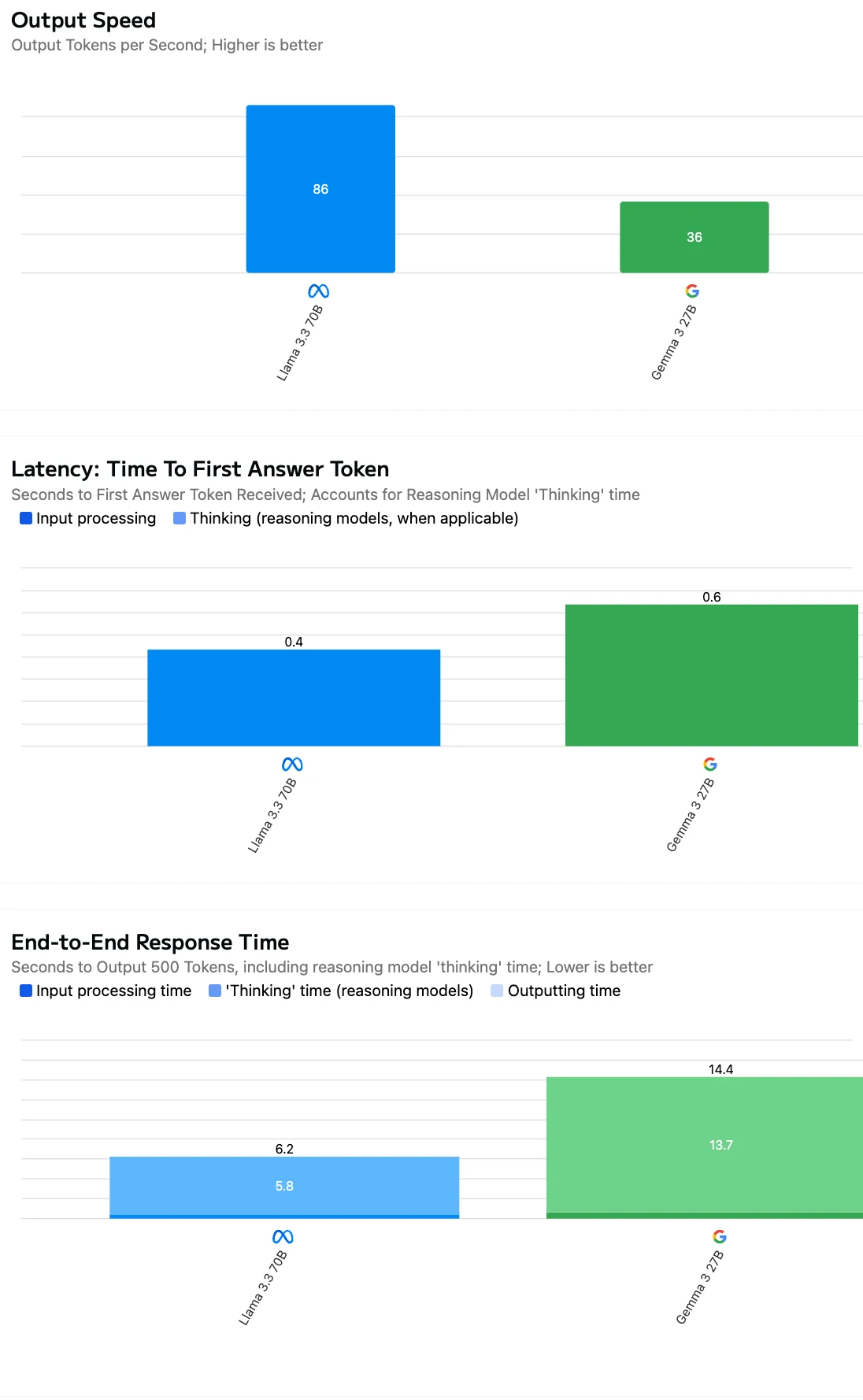
資料來源:Artificial Analysis
或者您可以直接使用免費遊樂場,測試每項任務的速度!
2. 本地推理硬體需求
Llama 3.3 70B:
- VRAM: 24GB(最低)用於 4 位元量化;80GB 以上(A100/H100)用於完整精度。
- 建議配置: 2 張 NVIDIA A100/H100(80GB)。
- RAM: 32–64GB+
- 儲存空間: 250GB+
- 家用設置: 難度高,需要高功耗與散熱能力。
Gemma 3 27B:
- VRAM: 可裝載於 1 張 H100(80GB)或 3–4 張 RTX 4090(24GB)。
- RAM: ~32–64GB
- 儲存空間: 54GB(權重);72.7GB(含 KV 快取)
- 家用設置: 較容易,進階桌上型電腦可行。
約略市價(2025 年第二季):
- RTX 4090 24 GB:約 $1,600
- NVIDIA H100 80 GB:約 $29,000
3. GPU 雲端即時費率
| GPU 類型 | 隨需使用 | 專用端點 |
|---|---|---|
| A100 80 GB | $1.60/hr | - |
| H100 80 GB | $2.56/hr | $2.41/hr |
| RTX4090 | $1.05/hr(3 張) | $0.61/hr |
結論很明確:Gemma 3 27B 降低了在本地運行強大模型的門檻,而 Llama 3.3 70B 則更適合雲端 API 存取,或擁有大量本地硬體投資的組織。
應用場景:為工作選擇正確工具
這兩款模型的獨特定位使它們適用於不同的應用。
| **使用情境 ** | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| 聊天機器人 / AI 助手 | 支援 140+ 種語言,非常適合全球多語言對話式 AI 應用 | 擅長指令遵循,適合要求嚴格的英語及多語言助手 |
| 程式碼生成 | 在基礎到中階程式碼任務上表現良好;適合原型設計與教育專案 | HumanEval 達到 88%;對於開發者工具中的複雜程式碼生成與除錯表現強勁 |
| 長篇草稿 | 可處理多達 128k 個 token,能有效處理長文檔、報告或研究 | 同樣支援 128k–130k token 上下文,適用於長篇撰寫與摘要任務 |
| 圖片支援 | 原生多模態輸入(文字+圖片),搭配 SigLIP 編碼器,支援 OCR、內容審核與視覺問答 | 無原生多模態能力;僅限文字輸入 |
| 裝置端 / 邊緣部署 | 4B 與 9B 輕量版本能有效支援個人與中小企業的本地及邊緣部署 | 8B 變體可用於邊緣場景;70B 模型需要高階硬體 |
如何透過 Novita API 存取 Gemma 3 27B 和 Llama 3.3 70B?
步驟 1:登入並進入模型庫
登入您的帳戶,然後點選 模型庫 按鈕。

步驟 2:選擇您的模型
瀏覽可用選項,選擇符合您需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的功能。
步驟 4:取得您的 API 金鑰
為了驗證 API,我們將提供您一個新的 API 金鑰。進入「設定」頁面,您可以依照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言專用的套件管理器安裝 API。

安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session__FaCoze-7Vk7DBH0noVpc42JxmWIV4gCRV31Rz66AmBkUz5ZglF3sYVyGw3ZPlr08zck6KQHI51Scef6kEm8cQ==",
)
model = "google/gemma-3-27b-it"
stream = True # 或 False
max_tokens = 16000
system_content = ""請當一位有幫助的助手""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
在 Gemma 3 27B 與 Llama 3.3 70B 之間做選擇,關乎的不是哪個模型「更好」,而是哪個 更適合您。
Gemma 3 27B 代表了 AI 多功能性與效率的一大躍進。它以更低的硬體門檻帶來了強大的多模態能力,讓新一代能「看見」並理解世界的應用得以實現。對於需要靈活性,且希望在非企業級預算下運行頂尖 AI 的創新者而言,它是完美的工具。
Llama 3.3 70B 是大規模純文字效能的無可爭議冠軍。它在推理、指令遵循與程式碼撰寫任務上提供無與倫比的威力。加上其極低的 API 成本,它是那些打造以語言卓越為首要目標的穩健、高流量應用之企業與開發者的決定性選擇。
最終,您的決定將取決於一個簡單的取捨:您需要的是 Gemma 的多模態多功能性與硬體效率,還是 Llama 的純文字處理威力與 API 成本效益?
常見問題
Gemma 3 27B 能在 Mac 上運行嗎?
可以!較小的 Gemma 變體(如 4B)可透過 mlx-vlm 支援 Apple Silicon。27B 模型需要 GPU 加速(例如雲端 API)。
哪個模型對即時聊天機器人更快?
Llama 3.3 70B 在低延遲場景表現優異。Gemma 的視覺處理會增加少量額外負擔。
Llama 3.3 70B 真的是免費的嗎?
是的——在 novita ai 遊樂場 上免費使用。不過,本地部署需要昂貴的硬體,而 API 則會產生按 token 計費的成本。
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的簡便方式,同時也提供經濟實惠且可靠的 GPU 雲端用於建置與擴展。**
推薦閱讀
- [為什麼 LLaMA 3.3 70B 的 VRAM 需求對家用伺服器是一大挑戰?](http://Why LLaMA 3.3 70B VRAM Requirements Are a Challenge for Home Servers?)
- Qwen 2.5 72b 與 Llama 3.3 70b:哪個模型適合您的需求?
- Llama 3.3 70B 真的能與 Llama 3.1 405B 匹敵嗎?



