

Kernunterschiede
Hauptunterschied: Gemma 3 27B ist ein vielseitiges und effizientes multimodales Modell, das sowohl Bilder als auch Text verarbeiten kann. Llama 3.3 70B ist ein größeres, reines Textmodell, das für komplexe Denkaufgaben und das Befolgen von Anweisungen optimiert ist.
Leistung: Llama 3.3 70B führt bei textzentrierten Benchmarks für Code, Anweisungsbefolgung und Allgemeinwissen in der Regel die Spitze an. Gemma 3 27B zeigt starke Leistungen in Mathematik und bietet den einzigartigen Vorteil des visuellen Verständnisses.
Hardware-Zugänglichkeit: Gemma 3 27B ist auf Effizienz ausgelegt und gilt als eines der leistungsfähigsten Modelle, das auf einer einzelnen High-End-GPU läuft – ideal für lokale Bereitstellungen. Llama 3.3 70B erfordert aufgrund seiner Größe deutlich leistungsstärkere Hardware, oft mit mehreren GPUs.
Am besten geeignet für: Wählen Sie Gemma 3 27B für Anwendungen, die Multimodalität, breite Sprachunterstützung und effiziente Bereitstellung auf begrenzter Hardware erfordern. Entscheiden Sie sich für Llama 3.3 70B für unternehmenskritische, textlastige Anwendungen, bei denen Spitzenleistungen entscheidend sind.
Die Open-Source-KI-Modelle Google Gemma 3 27B und Meta Llama 3.3 70B gehören zu den führenden ihrer Art. Dieser Schnellvergleich zeigt Ihnen die Stärken beider Modelle, damit Sie schnell das richtige für Ihr Projekt auswählen können.
Grundlegende Einführung: Gemma 3 27B vs. Llama 3.3 70B
Werfen wir zunächst einen grundlegenden Blick darauf, was diese beiden Modelle unterscheidet.
| Merkmal | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Entwickler | Meta | |
| Veröffentlichungsdatum | 12. März 2025 | 6. Dezember 2024 |
| Parameter | 27 Milliarden | 70 Milliarden |
| Modalität | Multimodal (Bild- & Texteingabe) | Nur Text |
| Architektur | Verschachtelte lokale-globale Aufmerksamkeit | Optimierter Transformer mit GQA |
| Trainingsdaten | 14 Billionen Tokens | Über 15 Billionen Tokens |
| Kontextfenster | 128.000 Tokens | 128.000 Tokens |
| Mehrsprachigkeit | Unterstützt über 140 Sprachen | Offizielle Unterstützung für 8 Sprachen |
| Erweiterungen | Strukturierte Ausgaben, Funktionsaufruf mit Langchain | Funktionsaufruf |
Das herausragende Merkmal von Gemma 3 ist seine Multimodalität, die es ihm ermöglicht, visuelle Informationen zusammen mit Text zu interpretieren. Llama 3.3 70B ist zwar rein textbasiert, aber mit seiner mehr als doppelt so großen Parameterzahl oft leistungsfähiger und nuancierter bei Textgenerierung und Denkaufgaben.
Leistung: Eine Geschichte zweier Spezialisierungen
| Benchmark | Gemma 3 27B | Llama 3․3 70B |
|---|---|---|
| MMLU-Pro (Denken & Wissen) | 67 | 71 |
| MATH-500 (Quantitatives Denken) | 88 | 77 |
| LiveCodeBench (Code) | 14 | 29 |
| HumanEval (Code) | 89 | 86 |
| GPQA Diamond (Wissenschaftliches Denken) | 42,4 | 49 |
| MGSM | 74,3 | 91,1 |
| Vision QA (MMMU) | 64,9 | nur Text |
Kurze Zusammenfassung:
- Reine Sprache & Code: Llama 3 gewinnt deutlich.
- Bildaufgaben & OCR: nur Gemma 3 unterstützt sie.
- Denken & Wissen: beide sind wettbewerbsfähig; Llama 3 liegt bei Mathe und Code vorn, Gemma 3 punktet mit seiner breiten Mehrsprachigkeit.
Wenn Sie die Fähigkeiten von Gemma 3 bei VL-Modellen überprüfen möchten, lesen Sie diesen Artikel: Gemma 3 27B vs Qwen2.5-VL: Beste KI-Foto-Q&A?
Ressourceneffizienz: Kosten und Hardware
Hier unterscheiden sich die beiden Modelle am deutlichsten, was die Zugänglichkeit und die Bereitstellungsstrategie beeinflusst.
1. API-Preise (öffentliches Pay-as-you-go)
| Anbieter | Gemma 3 27B | Llama 3․3 70B |
|---|---|---|
| Novita AI | $0,119 / Mio. Eingabe- & $0,20 / Mio. Ausgabetokens | $0,13 / Mio. Eingabe- & $0,39 / Mio. Ausgabetokens |
| Deepinfra | $0,09 / Mio. Eingabe- & $0,17 / Mio. Ausgabetokens | $0,23 / Mio. Eingabe- & $0,40 / Mio. Ausgabetokens |
| Parasail | $1,20 / Mio. Eingabe- & $1,20 / Mio. Ausgabetokens | $0,10 / Mio. Eingabe- & $0,40 / Mio. Ausgabetokens |
Bei der Bewertung der API-Effizienz sollten Sie nicht nur die Kosten pro Token betrachten – auch die Ausgabegeschwindigkeit und die Antwortlatenz des Modells sind für reale Anwendungen entscheidend.
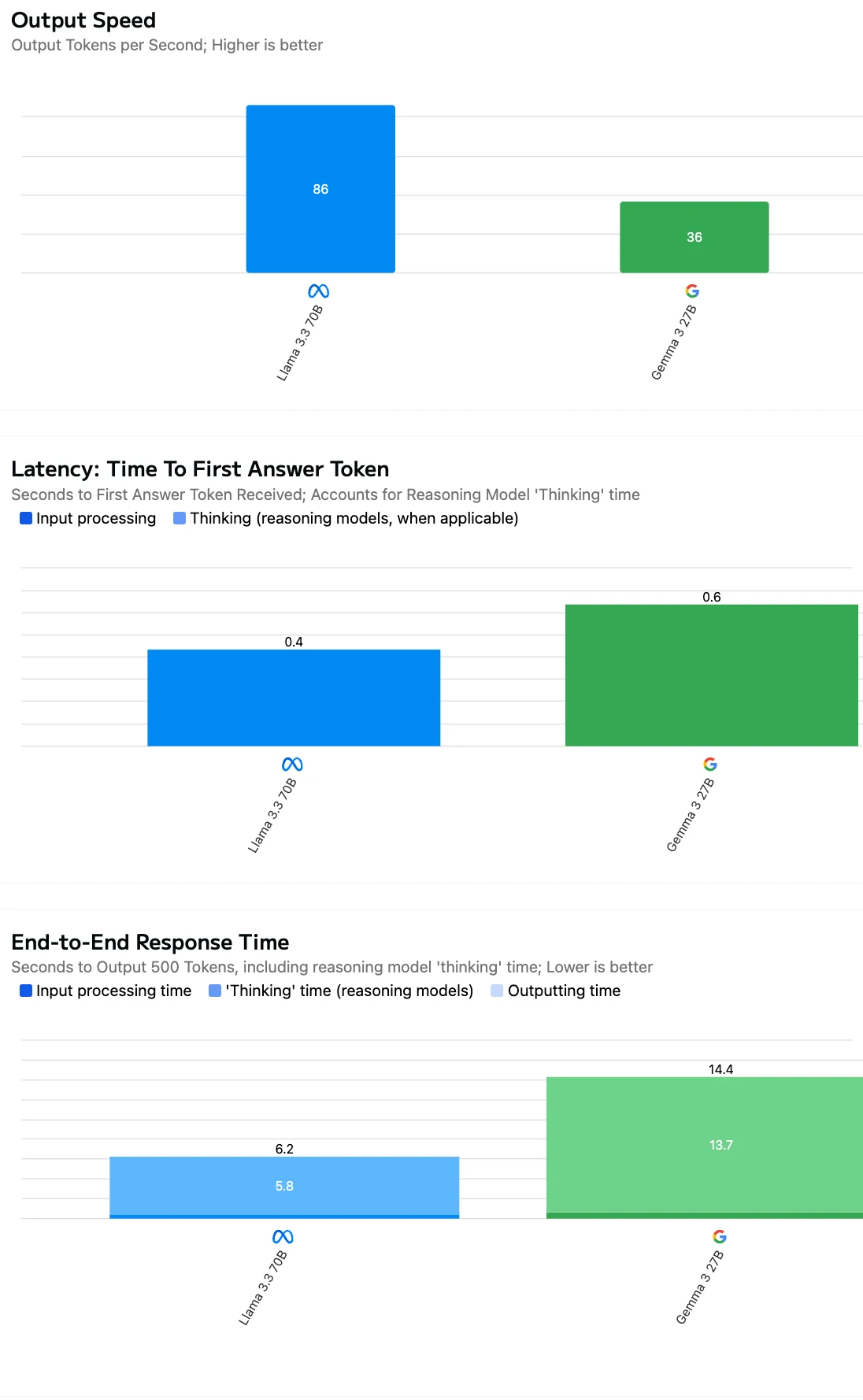
Quelle: Artificial Analysis
Oder Sie nutzen direkt die kostenlose Spielwiese, um die Geschwindigkeit für jede Aufgabe zu testen!
Jetzt Gemma 3 und Llama 3 testen!
2. Hardware für lokale Inferenz
Llama 3.3 70B:
- VRAM: 24 GB (Minimum) für 4-Bit-Quantisierung; 80 GB+ (A100/H100) für volle Präzision.
- Empfohlen: 2x NVIDIA A100/H100 (80 GB).
- RAM: 32–64 GB+
- Speicher: 250 GB+
- Heim-Setup: Anspruchsvoll, hoher Strom- und Kühlbedarf.
Gemma 3 27B:
- VRAM: Passt auf 1x H100 (80 GB) oder 3–4x RTX 4090 (24 GB).
- RAM: ~32–64 GB
- Speicher: 54 GB (Gewichte); 72,7 GB (mit KV-Cache)
- Heim-Setup: Einfacher, für fortgeschrittene Desktop-Rechner machbar.
Ungefähre Straßenpreise (Q2 2025):
- RTX 4090 24 GB: ~1.600 $
- NVIDIA H100 80 GB: ~29.000 $
3. GPU-Cloud-Spot-Preise
| GPU-Typ | On-demand | Dedizierte Endpunkte |
|---|---|---|
| A100 80 GB | 1,60 $/Std. | – |
| H100 80 GB | 2,56 $/Std. | 2,41 $/Std. |
| RTX4090 | 1,05 $/Std. (3 Karten) | 0,61 $/Std. |
Jetzt kostengünstige GPU testen
Das Fazit ist klar: Gemma 3 27B senkt die Einstiegshürde für den Betrieb eines leistungsstarken Modells lokal, während Llama 3.3 70B eher für den Cloud-API-Zugriff oder Organisationen mit erheblichen lokalen Hardware-Investitionen gedacht ist.
Anwendungen: Das richtige Werkzeug für die Aufgabe wählen
Die unterschiedlichen Profile dieser Modelle machen sie für verschiedene Anwendungen geeignet.
| Anwendungsfall | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Chatbots / KI-Assistenten | Unterstützt über 140 Sprachen, ideal für globale, mehrsprachige Konversations-KI-Anwendungen | Hervorragend im Befolgen von Anweisungen, ideal für anspruchsvolle englische und mehrsprachige Assistenten |
| Codegenerierung | Gute Leistung bei grundlegenden bis mittelschweren Code-Aufgaben; geeignet für Prototyping und Bildungsprojekte | Erreicht 88 % bei HumanEval; stark bei komplexer Code-Generierung und Fehlersuche für Entwickler-Tools |
| Verfassen langer Texte | Verarbeitet bis zu 128k Tokens, effiziente Verarbeitung langer Dokumente, Berichte oder Forschung | Unterstützt ebenfalls 128k–130k Token-Kontext für längere Texterstellung und Zusammenfassungen |
| Bildunterstützung | Natives multimodales Input (Text + Bilder) mit SigLIP-Encoder, ermöglicht OCR, Inhaltsmoderation und visuelle Q&A | Keine native multimodale Fähigkeit; nur Texteingabe |
| On-Device / Edge-Bereitstellung | Leichte Varianten mit 4B und 9B ermöglichen effiziente lokale und Edge-Bereitstellung für Einzelpersonen und KMU | 8B-Variante für Edge verfügbar; 70B-Modell erfordert High-End-Hardware |
So greifen Sie über die Novita-API auf Gemma 3 27B und Llama 3.3 70B zu
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek .

Jetzt Gemma 3 und Llama 3 testen!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Möglichkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session__FaCoze-7Vk7DBH0noVpc42JxmWIV4gCRV31Rz66AmBkUz5ZglF3sYVyGw3ZPlr08zck6KQHI51Scef6kEm8cQ==",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 16000
system_content = ""Sei ein hilfreicher Assistent""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Die Wahl zwischen Gemma 3 27B und Llama 3.3 70B dreht sich nicht darum, welches Modell „besser“ ist, sondern welches für Sie besser ist.
Gemma 3 27B stellt einen Sprung in der KI-Vielseitigkeit und -Effizienz dar. Es bringt leistungsstarke multimodale Fähigkeiten auf eine zugänglichere Hardware-Plattform und ermöglicht eine neue Welle von Anwendungen, die die Welt sehen und verstehen können. Es ist das perfekte Werkzeug für Innovatoren, die Flexibilität benötigen und modernste KI ohne ein unternehmensgroßes Budget betreiben möchten.
Llama 3.3 70B ist der unangefochtene Champion der reinen Text-Performance im großen Maßstab. Es bietet unübertroffene Leistung bei Denkaufgaben, Anweisungsbefolgung und Codierung. In Kombination mit seinen extrem niedrigen API-Kosten ist es die definitive Wahl für Unternehmen und Entwickler, die robuste, hochvolumige Anwendungen entwickeln, bei denen sprachliche Exzellenz das Hauptziel ist.
Letztendlich hängt Ihre Entscheidung von einem einfachen Kompromiss ab: Benötigen Sie die multimodale Vielseitigkeit und Hardware-Effizienz von Gemma oder die rohe Textverarbeitungsleistung und API-Kosteneffizienz von Llama?
Häufig gestellte Fragen
Kann Gemma 3 27B auf einem Mac laufen?
Ja! Kleinere Gemma-Varianten (z. B. 4B) unterstützen Apple Silicon via mlx-vlm. Das 27B-Modell benötigt GPU-Beschleunigung (z. B. Cloud-APIs).
Welches Modell ist schneller für Echtzeit-Chatbots?
Llama 3.3 70B zeichnet sich durch geringe Latenz aus. Gemmas Bildverarbeitung fügt einen kleinen Overhead hinzu.
Ist Llama 3.3 70B wirklich kostenlos?
Ja – es ist kostenlos auf der Novita AI Spielwiese . Die lokale Bereitstellung erfordert jedoch teure Hardware, während APIs tokenbasierte Kosten verursachen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Empfohlene Lektüre
- [Warum die VRAM-Anforderungen von LLaMA 3.3 70B eine Herausforderung für Heimserver darstellen](http://Warum die VRAM-Anforderungen von LLaMA 3.3 70B eine Herausforderung für Heimserver darstellen)
- Qwen 2.5 72b vs Llama 3.3 70b: Welches Modell passt zu Ihren Anforderungen?
- Ist Llama 3.3 70B wirklich mit Llama 3.1 405B vergleichbar?



