

关键亮点
核心差异 :Gemma 3 27B 是一款功能强大且高效的 多模态 模型,能够同时处理图像和文本。Llama 3.3 70B 则是一款规模更大、 纯文本的强模型,专为复杂推理和指令跟随任务优化。
性能:Llama 3.3 70B 在编码、指令遵循和通用知识等文本中心的基准测试中通常领先。Gemma 3 27B 在数学方面表现出色,并具备独特的视觉理解优势。
硬件可及性:Gemma 3 27B 专为效率而设计,被誉为一款可在单个高端 GPU 上运行的最强大模型之一,因此更易于本地部署。Llama 3.3 70B 更大的规模需要更强大的硬件,通常需要多 GPU 设置。
**最佳适用场景 **:选择 Gemma 3 27B 用于需要多模态、广泛语言支持以及在受限硬件上高效部署的应用。选择 Llama 3.3 70B 用于企业级的、以文本为中心的应用,这些应用要求顶尖性能。
Google 的 Gemma 3 27B 和 Meta 的 Llama 3.3 70B 都是顶尖的开源 AI 模型。本快速指南将对比它们的优势,帮助您为项目快速做出最佳选择。
基本介绍:Gemma 3 27B vs. Llama 3.3 70B
我们先从基础入手,看看这两款模型的关键差异。
| 功能特性 | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| 开发者 | Meta | |
| 发布日期 | 2025 年 3 月 12 日 | 2024 年 12 月 6 日 |
| 参数量 | 270 亿 | 700 亿 |
| **模态 ** | ** 多模态 **(图像和文本输入) | ** 纯文本** |
| 架构 | 交错局部-全局注意力 | 优化 Transformer 并带 GQA |
| 训练数据 | 14 万亿 Token | 超过 15 万亿 Token |
| 上下文窗口 | 128,000 Token | 128,000 Token |
| 多语言 | 支持超过 140 种语言 | 官方支持 8 种语言 |
| 扩展能力 | 结构化输出、通过 Langchain 进行函数调用 | 函数调用 |
Gemma 3 的突出特点是其多模态能力,允许它同时理解图像和文本信息。而 Llama 3.3 70B 虽然只支持文本,但参数量是前者的两倍多,这通常意味着更强大和细腻的文本生成与推理能力。
性能:两种专长
| 基准测试 | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| MMLU-Pro(推理与知识) | 67 | 71 |
| MATH-500(定量推理) | 88 | 77 |
| LiveCodeBench(编码) | 14 | 29 |
| HumanEval(编码) | 89 | 86 |
| GPQA Diamond(科学推理) | 42.4 | 49 |
| MGSM(多语言数学) | 74.3 | 91.1 |
| 视觉问答(MMMU) | 64.9 | 仅文本 |
快速总结:
- 纯语言和编码:Llama 3 以较大优势获胜。
- 视觉任务和 OCR:只有 Gemma 3 支持。
- 推理与知识:两者都有竞争力;Llama 3 在数学和代码方面略微领先,Gemma 3 则在多语言广度上保持优势。
如果您想了解 Gemma 3 在 VL 模型方面的能力,可以参阅这篇文章:Gemma 3 27B vs Qwen2.5-VL:最佳 AI 图片问答模型?
资源效率:成本与硬件
这是两款模型分化最明显的领域,直接影响可访问性和部署策略。
1. API 定价(公共按量付费)
| 供应商 | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Novita AI | 输入 $0.119 / M Token,输出 $0.20 / M Token | 输入 $0.13 / M Token,输出 $0.39 / M Token |
| Deepinfra | 输入 $0.09 / M Token,输出 $0.17 / M Token | 输入 $0.23 / M Token,输出 $0.40 / M Token |
| Parasail | 输入 $1.20 / M Token,输出 $1.20 / M Token | 输入 $0.10 / M Token,输出 $0.40 / M Token |
在评估 API 效率时,不仅要看每个 Token 的成本,模型输出速度和响应延迟对于实际应用同样至关重要。
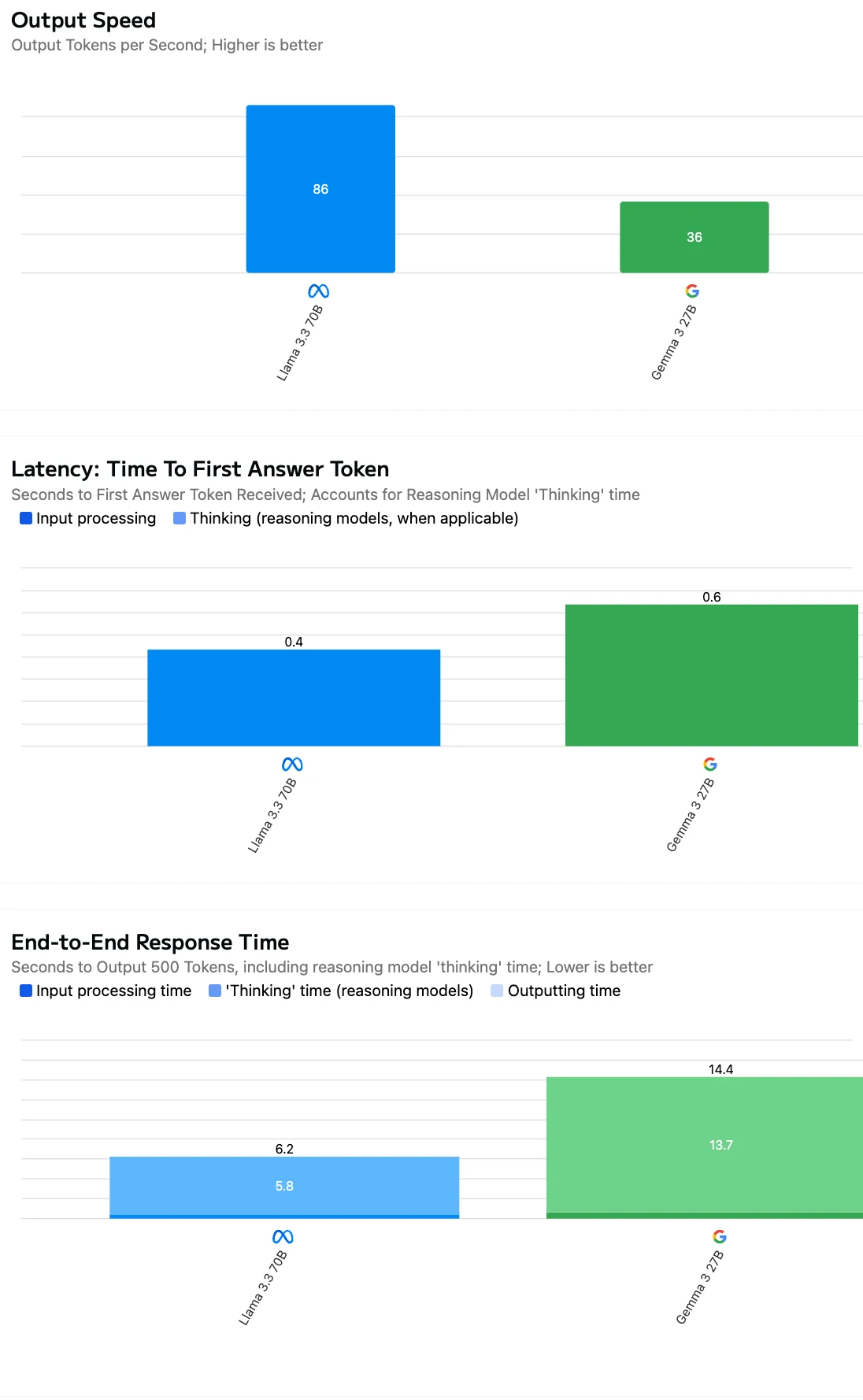
或者您可以直接使用免费的 Playground 来测试各项任务的速度!
2. 本地推理硬件
Llama 3.3 70B:
- 显存: 24GB(最低)用于 4-bit 量化;80GB+(A100/H100)用于全精度。
- 推荐配置: 2x NVIDIA A100/H100(80GB)。
- 内存: 32–64GB+
- 存储: 250GB+
- 家用设置: 困难,高功耗和高散热需求。
Gemma 3 27B:
- 显存: 可容纳于 1x H100(80GB)或 3–4x RTX 4090(24GB)。
- 内存: ~32–64GB
- 存储: 54GB(权重);72.7GB(含 KV 缓存)
- 家用设置: 更容易,对高端桌面更可行。
2025 年 Q2 大致市场价格:
- RTX 4090 24GB:约 $1,600
- NVIDIA H100 80GB:约 $29,000
3. 云端 GPU 现货价格
| GPU 类型 | 按需 | 专用端点 |
|---|---|---|
| A100 80GB | $1.60/小时 | - |
| H100 80GB | $2.56/小时 | $2.41/小时 |
| RTX4090 | $1.05/小时(3 张卡) | $0.61/小时 |
结论很明确:Gemma 3 27B 降低了在本地运行强大模型的门槛,而 Llama 3.3 70B 则更适合云 API 访问或具备大量本地硬件投资的组织。
应用:为任务选择合适的工具
两款模型截然不同的特性使它们适用于不同的应用场景。
| **应用场景 ** | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| 聊天机器人 / AI 助手 | 支持 140+ 种语言,非常适合全球多语言对话式 AI 应用 | 擅长指令遵循,非常适合要求较高的英文和多语言助手 |
| 代码生成 | 在基础到中级代码任务中表现良好;适用于原型设计和教育项目 | 在 HumanEval 上达到 88%;在复杂代码生成和调试方面表现出色,适合开发者工具 |
| 长文起草 | 支持高达 128k Token,能够高效处理长文档、报告或研究 | 也支持 128k–130k Token 上下文,适用于长文起草和摘要任务 |
| 图像支持 | 原生多模态输入(文本 + 图像)并配备 SigLIP 编码器,支持 OCR、内容审核和视觉问答 | 没有原生多模态能力;仅限于文本输入 |
| 设备端 / 边缘部署 | 4B 和 9B 轻量级版本可实现高效的本地和边缘部署,适合个人和小型企业 | 8B 变种可用于边缘场景;70B 模型需要高端硬件 |
如何通过 Novita API 访问 Gemma 3 27B 和 Llama 3.3 70B?
步骤 1:登录并访问模型库
登录您的账户,点击 模型库 按钮。

步骤 2:选择模型
浏览可用选项,选择适合您需求的模型。
步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤 4:获取 API 密钥
为对 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入 “设置” 页面,您可以根据图中所示复制 API 密钥。

步骤 5:安装 API
使用您编程语言的特定包管理器安装 API。

安装完成后,将必要的库导入您的开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session__FaCoze-7Vk7DBH0noVpc42JxmWIV4gCRV31Rz66AmBkUz5ZglF3sYVyGw3ZPlr08zck6KQHI51Scef6kEm8cQ==",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
在 Gemma 3 27B 和 Llama 3.3 70B 之间做选择,并非判断哪款模型“更好”,而是哪款模型 更适合您。
Gemma 3 27B 代表了 AI 多功能性和效率的飞跃。它将强大的多模态能力带到了更易获取的硬件占地上,赋能了一批能够观察和理解世界的新应用。对于那些需要灵活性、希望在没有企业级预算的情况下运行最先进 AI 的创新者来说,它是理想的工具。
Llama 3.3 70B 是纯文本性能在大规模场景下无可争议的冠军。它在推理、指令遵循和编码任务上提供了无与伦比的能力。结合其极低的 API 成本,它是那些构建稳健、高并发应用、以语言卓越为首要目标的开发者和企业的最终选择。
最终,您的决定将取决于一个简单的取舍:您需要的是 Gemma 的多模态灵活性和硬件效率,还是 Llama 的纯文本处理能力和 API 性价比?
常见问题
Gemma 3 27B 能在 Mac 上运行吗?
可以!更小的 Gemma 变体(如 4B)通过 mlx-vlm 支持 Apple Silicon。27B 模型需要 GPU 加速(例如云 API)。
对于实时聊天机器人,哪款模型更快?
Llama 3.3 70B 在低延迟场景下表现出色。Gemma 的视觉处理会引入少量额外开销。
Llama 3.3 70B 真的免费吗?
是的——它在 Novita AI Playground 上免费。但本地部署需要昂贵的硬件,而 API 则会按 Token 计费。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。*
推荐阅读
- [为什么 LLaMA 3.3 70B 的 VRAM 要求对家庭服务器是一个挑战?](http://Why LLaMA 3.3 70B VRAM Requirements Are a Challenge for Home Servers?)
- Qwen 2.5 72b vs Llama 3.3 70b:哪款模型适合您的需求?
- Llama 3.3 70B 真的能与 Llama 3.1 405B 媲美吗?



