

Ключевые моменты
Основное различие: Gemma 3 27B — это универсальная и эффективная мультимодальная модель, способная обрабатывать как изображения, так и текст. Llama 3.3 70B — это более крупная текстовая модель, оптимизированная для сложных рассуждений и следования инструкциям.
Производительность: Llama 3.3 70B в целом лидирует в текстовых бенчмарках (кодинг, следование инструкциям, общие знания). Gemma 3 27B показывает высокие результаты в математике и обладает уникальным преимуществом — пониманием визуальной информации.
Доступность оборудования: Gemma 3 27B спроектирована для эффективности и считается одной из самых производительных моделей, которые можно запустить на одном высококлассном GPU, что делает её более доступной для локального развёртывания. Больший размер Llama 3.3 70B требует более мощного оборудования, часто — нескольких GPU.
Для чего лучше подходит: Выбирайте Gemma 3 27B для приложений, требующих мультимодальности, широкой языковой поддержки и эффективного развёртывания на ограниченном оборудовании. Llama 3.3 70B оптимальна для корпоративных, текстовых приложений, где критична максимальная производительность.
Google Gemma 3 27B и Llama 3.3 70B от Meta — ведущие открытые AI-модели. Это краткое руководство сравнивает их сильные стороны, чтобы вы могли быстро выбрать подходящую для своего проекта.
Основное введение: Gemma 3 27B vs. Llama 3.3 70B
Начнём с базового обзора того, чем отличаются эти две модели.
| Характеристика | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Разработчик | Meta | |
| Дата выхода | 12 марта 2025 | 6 декабря 2024 |
| Параметры | 27 миллиардов | 70 миллиардов |
| Модальность | Мультимодальная (изображение и текст) | Только текст |
| Архитектура | Перемежающееся локально-глобальное внимание | Оптимизированный Transformer с GQA |
| Обучающие данные | 14 триллионов токенов | Более 15 триллионов токенов |
| Контекстное окно | 128 000 токенов | 128 000 токенов |
| Многоязычность | Поддерживает более 140 языков | Официальная поддержка 8 языков |
| Дополнительные возможности | Структурированные выводы, Function Calling с Langchain | Function Calling |
Ключевая особенность Gemma 3 — мультимодальность, позволяющая интерпретировать визуальную информацию вместе с текстом. Llama 3.3 70B, хотя и работает только с текстом, более чем вдвое превосходит Gemma 3 по количеству параметров, что часто даёт более тонкую и мощную генерацию текста и способность к рассуждению.
Производительность: две специализации
| Бенчмарк | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| MMLU-Pro (рассуждение и знания) | 67 | 71 |
| MATH-500 (количественное рассуждение) | 88 | 77 |
| LiveCodeBench (кодинг) | 14 | 29 |
| HumanEval (кодинг) | 89 | 86 |
| GPQA Diamond (научное рассуждение) | 42.4 | 49 |
| MGSM | 74.3 | 91.1 |
| Vision QA (MMMU) | 64.9 | только текст |
Краткие выводы:
- Чисто язык и кодинг: Llama 3 побеждает с большим отрывом.
- Задачи с изображениями и OCR: поддерживает только Gemma 3.
- Рассуждение и знания: обе конкурентоспособны; Llama 3 превосходит в математике и коде, Gemma 3 сильна в многоязычности.
Если хотите проверить способности Gemma 3 в моделях визуального языка, смотрите статью: Gemma 3 27B vs Qwen2.5-VL: лучшая для AI-ответов на вопросы по фото?
Эффективность ресурсов: стоимость и оборудование
Здесь модели расходятся наиболее существенно, влияя на доступность и стратегию развёртывания.
1. Цены API (публичная оплата по мере использования)
| Провайдер | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Novita AI | $0.119 / млн входных и $0.20 / млн выходных токенов | $0.13 / млн входных и $0.39 / млн выходных токенов |
| Deepinfra | $0.09 / млн входных и $0.17 / млн выходных токенов | $0.23 / млн входных и $0.40 / млн выходных токенов |
| Parasail | $1.20 / млн входных и $1.20 / млн выходных токенов | $0.10 / млн входных и $0.40 / млн выходных токенов |
Оценивая эффективность API, следует смотреть не только на стоимость токена — скорость вывода модели и задержка ответа не менее важны для реальных приложений.
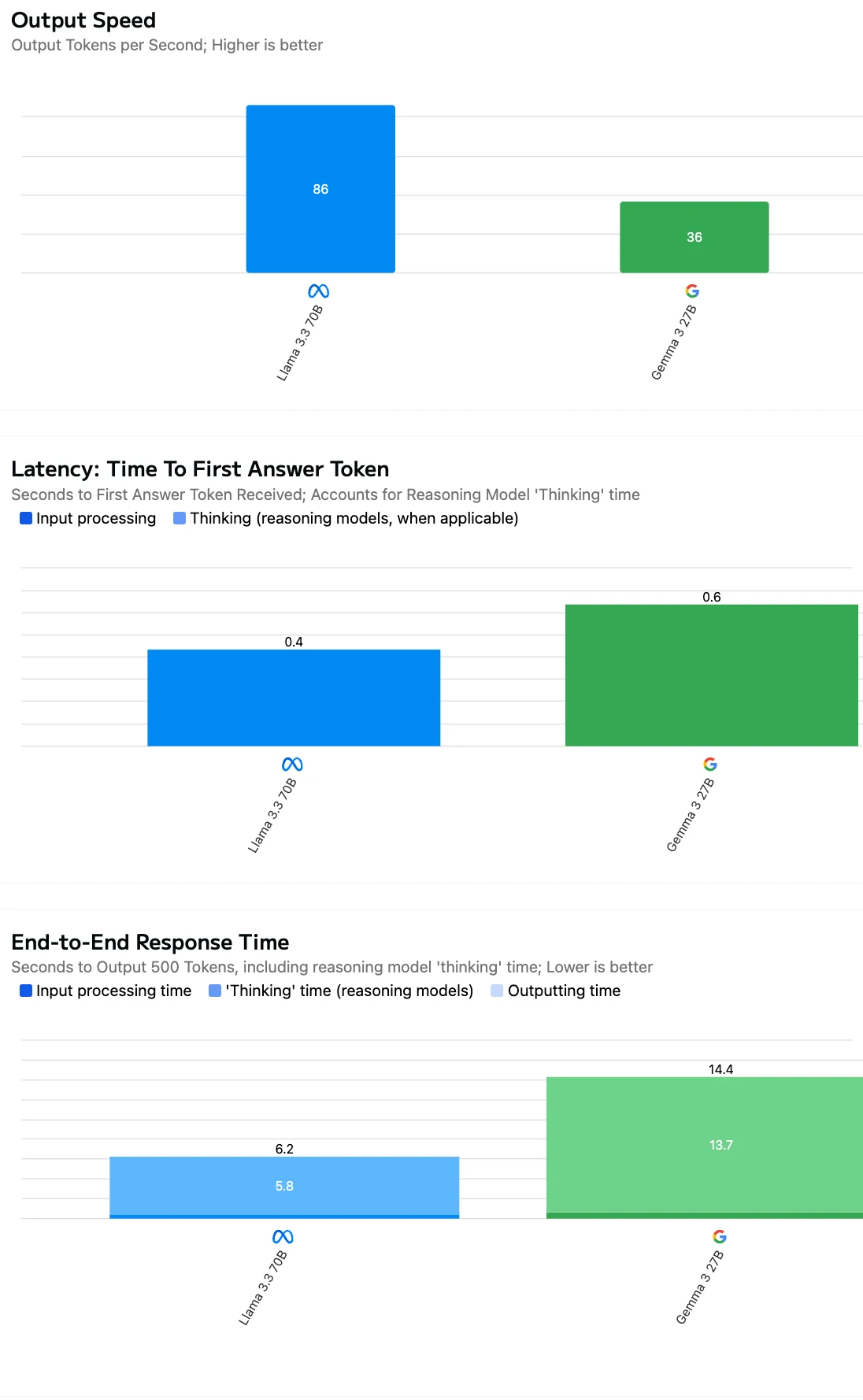
Источник: Artificial Analysis
Или вы можете напрямую использовать бесплатную песочницу, чтобы протестировать скорость для каждой задачи!
Попробовать Gemma 3 и Llama 3 прямо сейчас!
2. Оборудование для локального инференса
Llama 3.3 70B:
- VRAM: 24 ГБ (минимум) для 4-битного квантования; 80+ ГБ (A100/H100) для полной точности.
- Рекомендуется: 2x NVIDIA A100/H100 (80 ГБ).
- RAM: 32–64 ГБ+
- Хранилище: 250 ГБ+
- Домашняя установка: сложно, требует высокой мощности и охлаждения.
Gemma 3 27B:
- VRAM: помещается на 1x H100 (80 ГБ) или 3–4x RTX 4090 (24 ГБ).
- RAM: ~32–64 ГБ
- Хранилище: 54 ГБ (веса); 72.7 ГБ (с KV-кэшем)
- Домашняя установка: проще, более реалистично для продвинутых десктопов.
Примерные рыночные цены (2-й квартал 2025):
- RTX 4090 24 ГБ: ~$1 600
- NVIDIA H100 80 ГБ: ~$29 000
3. Спотовые цены GPU в облаке
| Тип GPU | По запросу | Выделенные endpoints |
|---|---|---|
| A100 80 ГБ | $1.60/ч | - |
| H100 80 ГБ | $2.56/ч | $2.41/ч |
| RTX4090 | $1.05/ч (3 карты) | $0.61/ч |
Попробовать GPU по выгодной цене
Вердикт очевиден: Gemma 3 27B снижает барьер для запуска мощной модели локально, тогда как Llama 3.3 70B больше ориентирована на облачный API или организации со значительными вложениями в локальное оборудование.
Применение: выбор подходящего инструмента для задачи
Различные профили этих моделей делают их подходящими для разных применений.
| Сценарий использования | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Чат-боты / AI-ассистенты | Поддерживает 140+ языков, отлично подходит для глобальных многоязычных приложений с AI-общением | Превосходно следует инструкциям, идеальна для требовательных англоязычных и многоязычных ассистентов |
| Генерация кода | Хорошо справляется с базовыми и средними задачами; подходит для прототипирования и учебных проектов | Достигает 88% на HumanEval; сильна в сложной генерации кода и отладке для инструментов разработчика |
| Создание длинных текстов | Поддерживает до 128k токенов, позволяет эффективно обрабатывать длинные документы, отчёты или исследования | Также поддерживает контекст 128k–130k токенов для расширенного написания и суммаризации |
| Поддержка изображений | Родной мультимодальный ввод (текст + изображения) с кодировщиком SigLIP, обеспечивающий OCR, модерацию контента и визуальные Q&A | Нет родной мультимодальности; только текстовые входы |
| Развёртывание на устройствах / Edge | Лёгкие версии 4B и 9B для эффективного локального и edge-развёртывания для частных лиц и малого бизнеса | Вариант 8B для edge; модель 70B требует мощного оборудования |
Как получить доступ к Gemma 3 27B и Llama 3.3 70B через Novita API?
Шаг 1: Войдите и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library.

Попробовать Gemma 3 и Llama 3 прямо сейчас!
Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, которая подходит вам.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Войдите на страницу «Settings» и скопируйте API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, подходящего для вашего языка программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования API chat completions для Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session__FaCoze-7Vk7DBH0noVpc42JxmWIV4gCRV31Rz66AmBkUz5ZglF3sYVyGw3ZPlr08zck6KQHI51Scef6kEm8cQ==",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Выбор между Gemma 3 27B и Llama 3.3 70B — это не вопрос, какая модель «лучше», а какая лучше для вас.
Gemma 3 27B представляет собой скачок в универсальности и эффективности AI. Она приносит мощные мультимодальные возможности в более доступное аппаратное обеспечение, открывая путь новым приложениям, которые могут видеть и понимать мир. Это идеальный инструмент для новаторов, которым нужна гибкость и возможность запускать передовой AI без корпоративного бюджета.
Llama 3.3 70B — это бесспорный чемпион чисто текстовой производительности в масштабе. Она предлагает непревзойдённую мощность для рассуждения, следования инструкциям и задач кодинга. В сочетании с невероятно низкой стоимостью API это определённый выбор для бизнеса и разработчиков, создающих надёжные высоконагруженные приложения, где лингвистическое качество является основной целью.
В конечном счёте, ваше решение будет зависеть от простого компромисса: нужна ли вам мультимодальная универсальность и эффективность оборудования Gemma, или же сырая мощность обработки текста и экономичность API Llama?
Часто задаваемые вопросы
Можно ли запустить Gemma 3 27B на Mac?
Да! Меньшие варианты Gemma (например, 4B) поддерживают Apple Silicon через mlx-vlm. Модель 27B требует ускорения GPU (например, облачные API).
Какая модель быстрее для чат-ботов в реальном времени?
Llama 3.3 70B превосходит в сценариях с низкой задержкой. Обработка изображений в Gemma добавляет небольшие накладные расходы.
Является ли Llama 3.3 70B действительно бесплатной?
Да — она бесплатна в novita ai playground. Однако локальное развёртывание требует дорогостоящего оборудования, а API взимают плату за токены.
Novita AI — это AI-облачная платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей через наш простой API, а также доступный и надёжный GPU-облако для создания и масштабирования.**
Рекомендуем к прочтению
- [Почему требования Llama 3.3 70B к VRAM являются проблемой для домашних серверов?](http://Why LLaMA 3.3 70B VRAM Requirements Are a Challenge for Home Servers?)
- Qwen 2.5 72b vs Llama 3.3 70b: какая модель подходит вашим задачам?
- Действительно ли Llama 3.3 70B сопоставима с Llama 3.1 405B?



