

أبرز النقاط
الفرق الأساسي: Gemma 3 27B هو نموذج متعدد الوسائط متعدد الاستخدامات وفعّال، قادر على معالجة كل من الصور والنص. Llama 3.3 70B هو عملاق نصي فقط محسّن للمهام المعقدة في الاستدلال واتباع التعليمات.
الأداء: يتصدر Llama 3.3 70B بشكل عام في المعايير النصية للبرمجة، واتباع التعليمات، والمعرفة العامة. يُظهر Gemma 3 27B أداءً قويًا في الرياضيات ويقدم ميزة فريدة تتمثل في فهم الصور.
التوفر على الأجهزة: صُمم Gemma 3 27B ليكون فعّالاً، ويُوصف بأنه أحد أقوى النماذج التي يمكن تشغيلها على بطاقة رسوميات واحدة عالية الأداء، مما يجعله أكثر قابلية للنشر المحلي. الحجم الأكبر لـ Llama 3.3 70B يتطلب أجهزة أكثر قوة، غالبًا ما تحتاج إلى إعدادات متعددة لوحدات معالجة الرسوميات.
الأفضل لـ: اختر Gemma 3 27B للتطبيقات التي تتطلب تعدد الوسائط، ودعمًا واسعًا للغات، ونشرًا فعّالاً على أجهزة محدودة. اختر Llama 3.3 70B للتطبيقات النصية الثقيلة على مستوى المؤسسات حيث يكون الأداء الأعلى أمرًا بالغ الأهمية.
يُعد كل من Gemma 3 27B من Google و Llama 3.3 70B من Meta من أفضل نماذج AI مفتوحة المصدر. يقدم هذا الدليل السريع مقارنة بين نقاط قوتهما لتتمكن من اختيار النموذج المناسب لمشروعك بسرعة.
مقدمة أساسية: Gemma 3 27B مقابل Llama 3.3 70B
لنبدأ بنظرة تأسيسية على ما يميز هذين النموذجين.
| الميزة | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| المطور | Meta | |
| تاريخ الإصدار | 12 مارس 2025 | 6 ديسمبر 2024 |
| المعلمات | 27 مليار | 70 مليار |
| الطريقة | متعدد الوسائط (إدخال صورة ونص) | نصي فقط |
| الهندسة المعمارية | انتباه محلي-عالمي متناوب | محول محسّن مع GQA |
| بيانات التدريب | 14 تريليون رمز | أكثر من 15 تريليون رمز |
| نافذة السياق | 128,000 رمز | 128,000 رمز |
| تعدد اللغات | يدعم أكثر من 140 لغة | دعم رسمي لـ 8 لغات |
| التوسعة | مخرجات منظمة، استدعاء الدوال مع Langchain | استدعاء الدوال |
الميزة البارزة في Gemma 3 هي تعدد الوسائط، مما يسمح له بتفسير المعلومات البصرية إلى جانب النص. Llama 3.3 70B، رغم أنه نصي فقط، إلا أن حجمه أكبر من الضعف من حيث عدد المعلمات، مما يُترجم غالبًا إلى قدرات أكثر دقة وقوة في توليد النصوص والاستدلال.
الأداء: قصة تخصصين
| المعيار | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| MMLU-Pro (الاستدلال والمعرفة) | 67 | 71 |
| MATH-500 (الاستدلال الكمي) | 88 | 77 |
| LiveCodeBench (البرمجة) | 14 | 29 |
| HumanEval (البرمجة) | 89 | 86 |
| GPQA Diamond (الاستدلال العلمي) | 42.4 | 49 |
| MGSM | 74.3 | 91.1 |
| اختبار الرؤية (MMMU) | 64.9 | نصي فقط |
استنتاجات سريعة:
- اللغة البحتة والبرمجة: Llama 3 يفوز بفارق كبير.
- مهام الرؤية وOCR: فقط Gemma 3 يدعمها.
- الاستدلال والمعرفة: كلاهما تنافسي؛ Llama 3 يتقدم قليلاً في الرياضيات والبرمجة، بينما يحافظ Gemma 3 على قوته في التنوع اللغوي.
إذا كنت تريد التحقق من قدرة Gemma 3 في نماذج الرؤية واللغة، يمكنك قراءة هذا المقال: Gemma 3 27B مقابل Qwen2.5-VL: الأفضل لأسئلة وأجوبة الصور بالذكاء الاصطناعي؟
كفاءة الموارد: التكلفة والأجهزة
هذا هو المجال الذي يختلف فيه النموذجان بشكل كبير، مما يؤثر على إمكانية الوصول واستراتيجية النشر.
1. تسعير API (الدفع حسب الاستخدام العام)
| المزود | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Novita AI | $0.119 / مليون رمز إدخال و $0.20 / مليون رمز إخراج | $0.13 / مليون رمز إدخال و $0.39 / مليون رمز إخراج |
| Deepinfra | $0.09 / مليون رمز إدخال و $0.17 / مليون رمز إخراج | $0.23 / مليون رمز إدخال و $0.40 / مليون رمز إخراج |
| Parasail | $1.20 / مليون رمز إدخال و $1.20 / مليون رمز إخراج | $0.10 / مليون رمز إدخال و $0.40 / مليون رمز إخراج |
عند تقييم كفاءة API، يجب أن تنظر إلى ما هو أبعد من مجرد التكلفة لكل رمز - سرعة إخراج النموذج وزمن الاستجابة مهمان بنفس القدر للتطبيقات الواقعية.
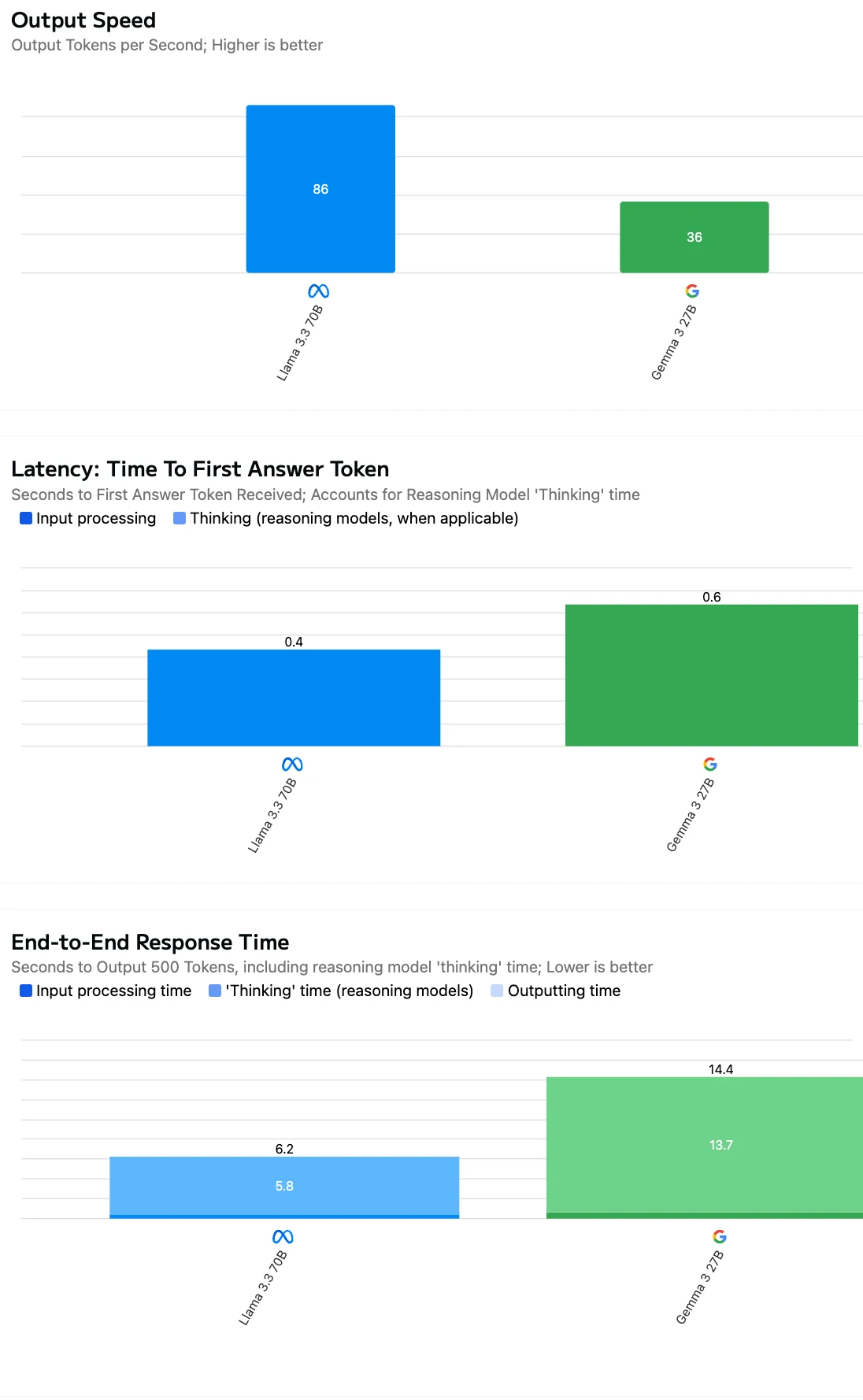
أو يمكنك استخدام الملعب المجاني مباشرة لاختبار السرعة من كل مهمة!
2. أجهزة الاستدلال المحلي
Llama 3.3 70B:
- VRAM: 24 جيجابايت (الحد الأدنى) للتمييز الرباعي؛ 80 جيجابايت+ (A100/H100) للدقة الكاملة.
- موصى به: 2x NVIDIA A100/H100 (80 جيجابايت).
- RAM: 32–64 جيجابايت+
- التخزين: 250 جيجابايت+
- الإعداد المنزلي: صعب، احتياجات طاقة وتبريد عالية.
Gemma 3 27B:
- VRAM: يتسع على 1x H100 (80 جيجابايت) أو 3–4x RTX 4090 (24 جيجابايت).
- RAM: ~32–64 جيجابايت
- التخزين: 54 جيجابايت (الأوزان)؛ 72.7 جيجابايت (مع ذاكرة التخزين المؤقت KV)
- الإعداد المنزلي: أسهل، أكثر جدوى لأجهزة الكمبيوتر المتقدمة.
أسعار السوق التقريبية (الربع الثاني 2025):
- RTX 4090 24 جيجابايت: ~1,600 دولار
- NVIDIA H100 80 جيجابايت: ~29,000 دولار
3. أسعار البقع السحابية لوحدات معالجة الرسوميات
| نوع GPU | حسب الطلب | نقاط نهاية مخصصة |
|---|---|---|
| A100 80 جيجابايت | $1.60/ساعة | - |
| H100 80 جيجابايت | $2.56/ساعة | $2.41/ساعة |
| RTX4090 | $1.05/ساعة (3 بطاقات) | $0.61/ساعة |
الحكم واضح: يخفض Gemma 3 27B حاجز الدخول لتشغيل نموذج قوي محليًا، بينما يتجه Llama 3.3 70B أكثر نحو الوصول عبر API السحابي أو المؤسسات التي لديها استثمار كبير في الأجهزة المحلية.
التطبيقات: اختيار الأداة المناسبة للمهمة
الملامح المتميزة لهذه النماذج تجعلها مناسبة لتطبيقات مختلفة.
| حالة الاستخدام | Gemma 3 27B | Llama 3.3 70B |
|---|---|---|
| Chatbots / المساعدين الذكيين | يدعم أكثر من 140 لغة، ومناسب تمامًا لتطبيقات المحادثة العالمية متعددة اللغات | يتفوق في اتباع التعليمات، مثالي للمساعدين باللغة الإنجليزية والتطبيقات متعددة اللغات الصعبة |
| توليد الكود | أداء جيد في مهام البرمجة الأساسية إلى المتوسطة؛ مناسب للنماذج الأولية والمشاريع التعليمية | يحقق 88% في HumanEval؛ قوي في توليد الكود المعقد وتصحيح الأخطاء لأدوات المطورين |
| الصياغة الطويلة | يتعامل مع ما يصل إلى 128 ألف رمز، مما يتيح معالجة فعالة للمستندات الطويلة أو التقارير أو الأبحاث | يدعم أيضًا سياق 128k–130k رمز لمهام الصياغة الممتدة والتلخيص |
| دعم الصور | إدخال متعدد الوسائط أصلي (نص + صور) مع مشفر SigLIP، مما يتيح التعرف على النص في الصور، ومراقبة المحتوى، وأسئلة وأجوبة بصرية | لا توجد قدرة متعددة الوسائط أصلية؛ يقتصر على إدخال النص فقط |
| النشر على الجهاز / الحافة | الإصدارات الخفيفة 4B و 9B تتيح نشرًا محليًا وحوفيًا فعالاً للأفراد والشركات الصغيرة والمتوسطة | يتوفر إصدار 8B للاستخدام على الحافة؛ نموذج 70B يتطلب أجهزة عالية الأداء |
كيفية الوصول إلى Gemma 3 27B و Llama 3.3 70B عبر Novita API؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج .

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المختار.
الخطوة 4: احصل على مفتاح API الخاص بك
لمصادقة API، سنقدم لك مفتاح API جديد. انتقل إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.

بعد التثبيت، قم باستيراد المكتبات اللازمة في بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لإكمال المحادثة لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session__FaCoze-7Vk7DBH0noVpc42JxmWIV4gCRV31Rz66AmBkUz5ZglF3sYVyGw3ZPlr08zck6KQHI51Scef6kEm8cQ==",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
الاختيار بين Gemma 3 27B و Llama 3.3 70B لا يتعلق بأي نموذج “أفضل”، بل بأي نموذج أفضل لك.
Gemma 3 27B يمثل قفزة في تنوع وكفاءة الذكاء الاصطناعي. إنه يجلب قدرات متعددة الوسائط قوية إلى بصمة أجهزة أكثر سهولة، مما يمكّن موجة جديدة من التطبيقات التي يمكنها رؤية وفهم العالم. إنها الأداة المثالية للمبتكرين الذين يحتاجون إلى المرونة ويريدون تشغيل ذكاء اصطناعي متطور دون ميزانية بحجم المؤسسات.
Llama 3.3 70B هو البطل بلا منازع في أداء النص الخالص على نطاق واسع. إنه يقدم قوة لا تضاهى في الاستدلال، واتباع التعليمات، ومهام البرمجة. إلى جانب تكلفة API المنخفضة بشكل لا يصدق، إنه الخيار النهائي للشركات والمطورين الذين يبنون تطبيقات قوية وعالية الحجم حيث يكون التميز اللغوي هو الهدف الأساسي.
في النهاية، سيعتمد قرارك على مقايضة بسيطة: هل تحتاج إلى تنوع الوسائط المتعددة وكفاءة الأجهزة في Gemma، أم قوة معالجة النص الخام وفعالية تكلفة API في Llama؟
الأسئلة المتكررة
هل يمكن تشغيل Gemma 3 27B على Mac؟
نعم! المتغيرات الأصغر من Gemma (مثل 4B) تدعم Apple Silicon عبر mlx-vlm. نموذج 27B يتطلب تسريع GPU (مثل APIs السحابية).
أي نموذج أسرع لـ chatbots في الوقت الفعلي؟
يتفوق Llama 3.3 70B في السيناريوهات منخفضة الكمون. معالجة الرؤية في Gemma تضيف حملًا بسيطًا.
هل Llama 3.3 70B مجاني حقًا؟
نعم - إنه مجاني على ملعب novita ai. ومع ذلك، يتطلب النشر المحلي أجهزة باهظة الثمن، بينما تتحمل APIs تكاليف تعتمد على الرموز.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير GPU سحابي بأسعار معقولة وموثوق للبناء والتوسع.
قراءة موصى بها
- [لماذا تعتبر متطلبات VRAM لـ LLaMA 3.3 70B تحديًا للخوادم المنزلية؟](http://Why LLaMA 3.3 70B VRAM Requirements Are a Challenge for Home Servers؟)
- Qwen 2.5 72b مقابل Llama 3.3 70b: أي نموذج يناسب احتياجاتك؟
- هل Llama 3.3 70B حقًا قابل للمقارنة مع Llama 3.1 405B؟



