

Key Highlights
Gemma 3 27B is a state-of-the-art multimodal AI model, released by Google, with 27 billion parameters and support for over 140 languages.
Function Calling via tools like LangChain enables seamless integration with external systems, expanding its capabilities for executing specialized tasks such as calculations, data analysis, and workflow automation.
Combined with Gemma 3 27B’s multimodal capabilities, Function Calling significantly enhances task automation, allowing for advanced cooperation between text, image processing, and external tools. Open-source availability encourages broad adoption and innovation across industries.
Gemma 3 27B represents a breakthrough in multimodal AI, offering unparalleled capabilities in understanding and generating text and images. With a massive 27 billion parameters and support for over 140 languages, it seamlessly handles complex tasks across industries.
What is Gemma 3 27B?
Release Date
March 12, 2025
Model Size
27 billion parameters
Open Source
Yes (released by Google)
Language Support
Over 140 languages
Training Data
14 trillion tokens
Strengths
Math, coding, instruction following
Multimodal Capability
Yes (processes images and text, outputs text)
Context Window
128K tokens
Gemma 3 27B Multimodal Capability Test
Prompt: Tell me how many times the elo score increased from gemma 2 27b to gemma 3 27b?
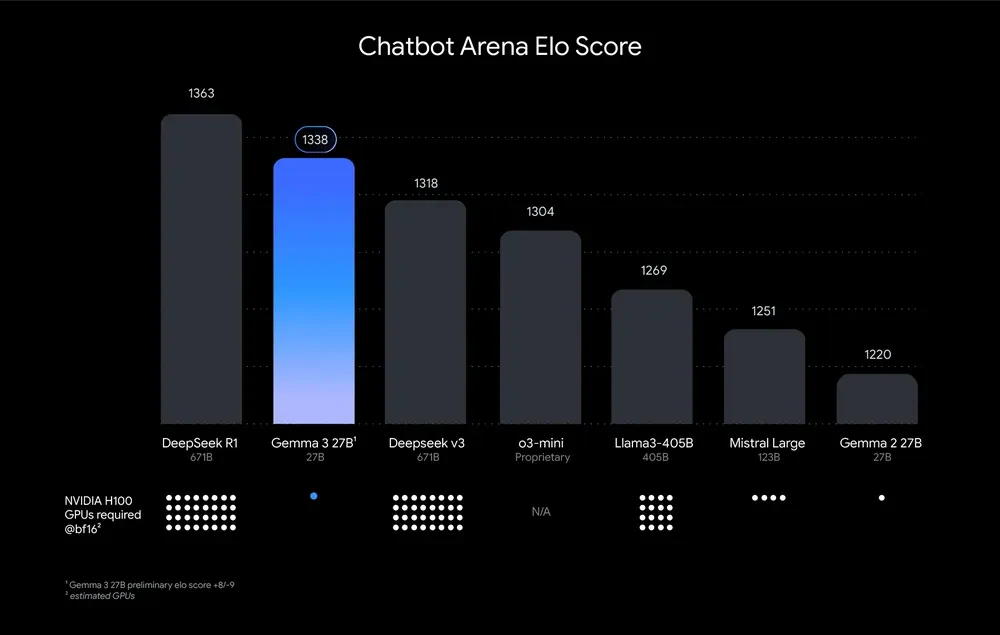
From Google
Output: Accurately identified the numbers but did not calculate the multiples as instructed by the prompt; instead, only calculated the difference.
Based on the image, here’s the calculation:
- Gemma 2 27B Elo score: 1220
- Gemma 3 27B Elo score: 1338
Increase: 1338 - 1220 = 118
The Elo score increased by 118 points from Gemma 2 27B to Gemma 3 27B.
Gemma 3 27B Benchmark
| Benchmark | Gemma 3 27B | DeepSeek R1 | LLaMA 3.3 70B |
|---|---|---|---|
| LMSys Elo Score | 1339 | ~1360 | ~1260 |
| MMLU-Pro | 67.5 | 84.0 | 66.4 |
| LiveCodeBench | 29.7 | 65.9 | ~29 |
| GPQA Diamond | 42.4 | 71.5 | 50.5 |
| MATH | 69.0 | 97.3 | 77.0 |
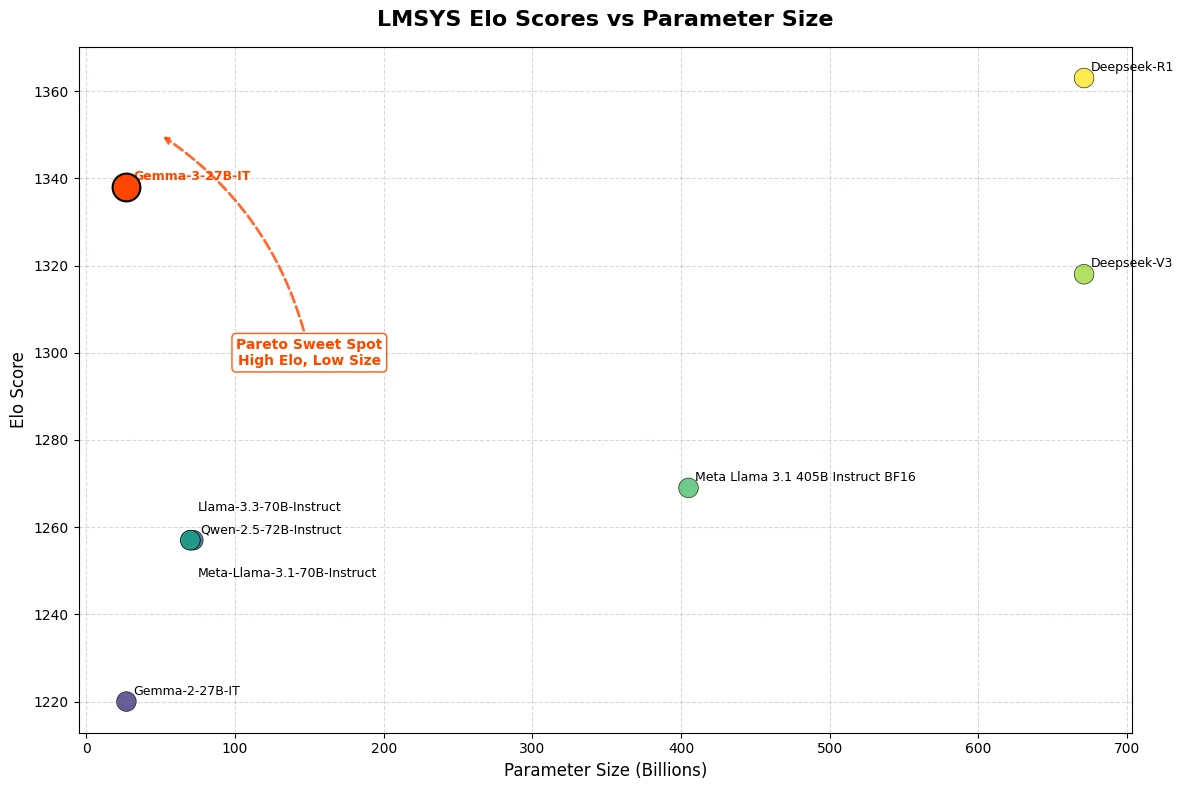
From Hugging Face
What problems can be solved by combining Multimodal Models with Function Calling?
Problem 1
Handling large files with limited resources
Although LLMs can directly process images or videos, handling large files (e.g., long videos or high-resolution images) can consume significant resources and may exceed the model’s context window.
Function Calling Role: Distribute complex or resource-heavy tasks to external systems, allowing the LLM to focus on coordinating and integrating results.
Problem 2
Expanding capabilities for specific functionalities
LLMs are primarily focused on understanding and generating content, but in certain scenarios, users may need more specific functionalities (e.g., chart generation, image editing, video trimming) that go beyond the LLM’s built-in capabilities.
Function Calling Role: Expand the LLM’s capabilities by enabling it to generate or execute specialized outputs through external tools.
Problem 3
Achieving deeper analysis with professional tools
While LLMs can analyze multimodal inputs like text, images, and videos, they may lack the depth to perform professional-grade tasks, such as medical image analysis or high-precision video editing.
Function Calling Role: Delegate tasks to professional tools or APIs, ensuring higher accuracy and deeper analysis than the LLM alone can provide.
How to Use Llama 3.3 70B Function Calling via Novita AI
Step1: Get API Key and Install it!
Entering the “Key Management“ page, you can copy the API key as indicated in the image.

Step2: Use Langchain to Implement the Function Calling
We’ll create a simple math application that can perform addition and multiplication operations.
💡 While this guide uses LangChain for convenience, implementing function calling doesn’t require any specific framework. The key is in designing the right prompts to make the model understand and correctly invoke functions. LangChain is used here simply to streamline the implementation.
Prerequisites
First, install the required packages:
pip install langchain-openai python-dotenvSetting Up the Environment
Create a .env file in your project root and add your Novita AI API key:
NOVITA_API_KEY=your_api_key_hereStep 3: Implementation Steps
1. Define the Tools
First, let’s create two simple mathematical tools using LangChain’s @tool decorator:
from langchain_core.tools import tool
@tool
def multiply(x: float, y: float) -> float:
"""Multiply two numbers together."""
return x * y
@tool
def add(x: int, y: int) -> int:
"""Add two numbers."""
return x + y
tools = [multiply, add]2. Create the Tool Execution Function
Next, implement a function to execute the tools:
from typing import Any, Dict, Optional, TypedDict
from langchain_core.runnables import RunnableConfig
class ToolCallRequest(TypedDict):
name: str
arguments: Dict[str, Any]
def invoke_tool(
tool_call_request: ToolCallRequest,
config: Optional[RunnableConfig] = None
):
"""Execute the specified tool with given arguments."""
tool_name_to_tool = {tool.name: tool for tool in tools}
name = tool_call_request["name"]
requested_tool = tool_name_to_tool[name]
return requested_tool.invoke(tool_call_request["arguments"], config=config)3. Set Up the LangChain Pipeline
Create a chain that uses Novita AI’s LLM to select and prepare tool calls:
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import render_text_description
def create_chain():
"""Create a chain that uses the specified LLM model to select and prepare tool calls."""
model = ChatOpenAI(
model="google/gemma-3-27b-it",
api_key=os.getenv("NOVITA_API_KEY"),
base_url="https://api.novita.ai/v3/openai",
)
rendered_tools = render_text_description(tools)
system_prompt = f"""\
You are an assistant that has access to the following set of tools.
Here are the names and descriptions for each tool:
{rendered_tools}
Given the user input, return the name and input of the tool to use.
Return your response as a JSON blob with 'name' and 'arguments' keys.
The `arguments` should be a dictionary, with keys corresponding
to the argument names and the values corresponding to the requested values.
"""
prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("user", "{input}")]
)
return prompt | model | JsonOutputParser()4. Create the Main Processing Function
Implement the main function that processes mathematical queries:
def process_math_query(query: str):
"""Process a mathematical query by using an LLM to select the appropriate tool and execute it."""
chain = create_chain()
message = chain.invoke({"input": query})
result = invoke_tool(message, config=None)
return message, result5. Usage Example
Here’s how to use the implementation:
if __name__ == "__main__":
message, result = process_math_query(
"meta-llama/llama-3.3-70b-instruct",
"what's 3 plus 1132"
)
print(result) # Output: 1135Gemma 3 27B redefines multimodal AI with industry-leading performance in math, coding, and instruction-based tasks. Its multimodal integration and extensive training data make it a versatile tool for developers and researchers.
Frequently Asked Questions
What is Gemma 3 27B?
Gemma 3 27B is a multimodal AI model with 27 billion parameters, capable of processing text and images and supporting over 140 languages.
How does Gemma 3 27B compare to its predecessor?
Gemma 3 27B shows significant improvements, including an Elo score increase of 118 points and enhanced performance in coding, math, and multimodal tasks.
Is Gemma 3 27B open source?
Yes, Gemma 3 27B is open-source, encouraging community-driven innovation.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



