

주요 요점
QwQ 32B: 복잡한 작업, 엣지 케이스 및 유연성이 필요한 시나리오를 처리하는 데 탁월합니다. 16비트, 8비트, 4비트 정밀도를 지원하여 실시간 및 비용에 민감한 애플리케이션에 효율적입니다.
Gemma 3 27B: FP16 지원 으로 높은 정밀도 작업에 최적화되어 있지만, 엣지 케이스와 긴 비밀번호 처리에 어려움을 겪습니다. 고자원 환경에서 가장 잘 작동합니다.
[Novita AI](ttps://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)는 안정적인 API 서비스를 제공할 뿐만 아니라 매우 비용 효율적인 가격을 제공합니다. 예를 들어, Gemma 3 27B는 입력 토큰 100만 개당 $0.119, 출력 토큰 100만 개당 $0.2이며, QwQ 32B는 입력 토큰 100만 개당 $0.18, 출력 토큰 100만 개당 $0.2입니다.
QwQ 32B 대 Gemma 3 27B: 기본 소개
QwQ 32B 소개

Gemma 3 27B 소개

QwQ 32B 대 Gemma 3 27B: 벤치마크
QwQ 32B는 모든 테스트에서 Gemma 3 27B를 능가합니다. 이는 QwQ 32B가 다중 도메인 작업에서 더 강력한 능력과 더 나은 다재다능함을 보여주는 반면, Gemma 3 27B는 특정 영역에서 뛰어날 수 있지만 전반적으로 뒤처짐을 나타냅니다.
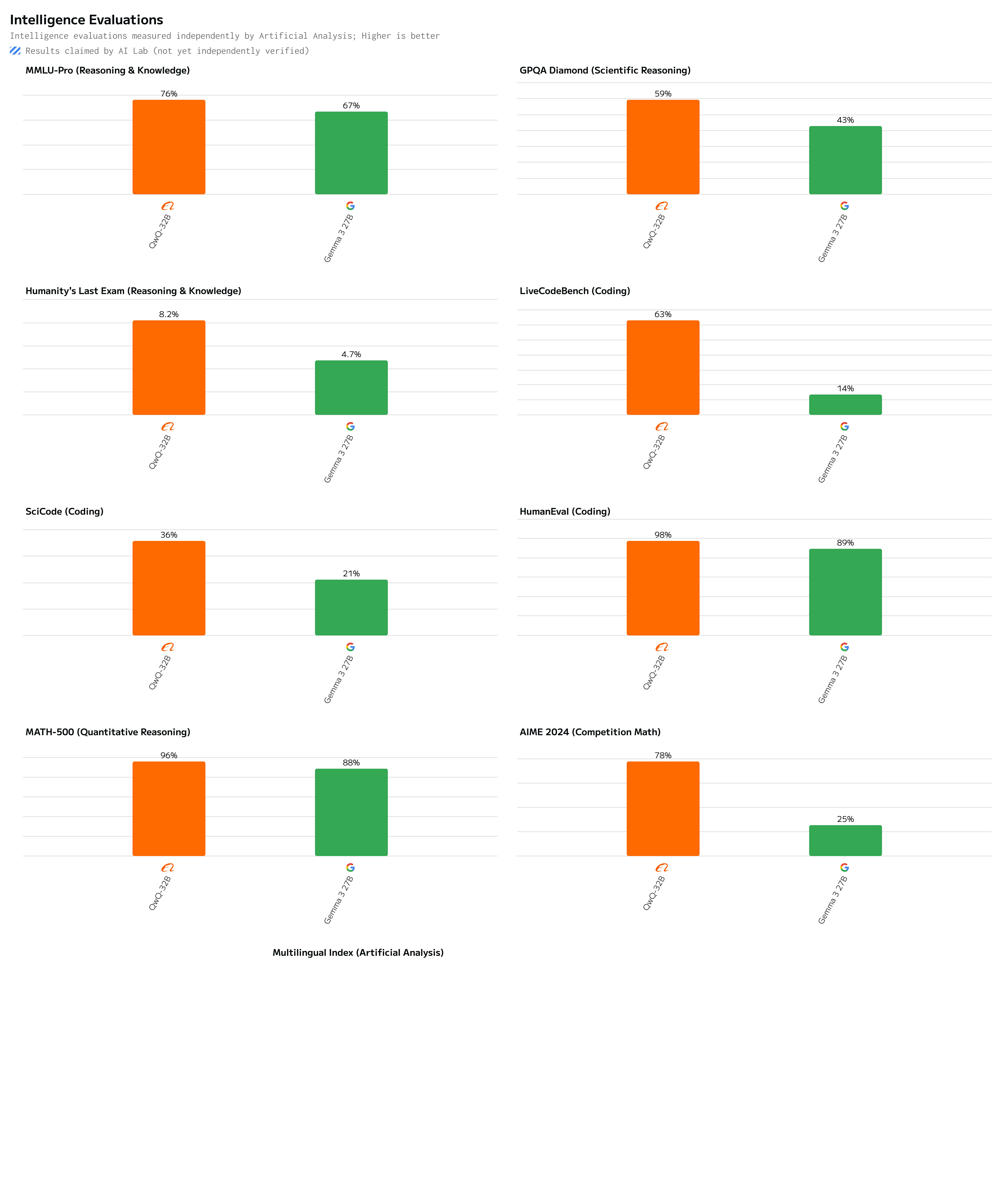
직접 테스트하고 싶다면 Novita AI 웹사이트에서 무료 체험을 시작할 수 있습니다.

[지금 QwQ 32B 및 Gemma 3 27B 데모 사용해보기!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
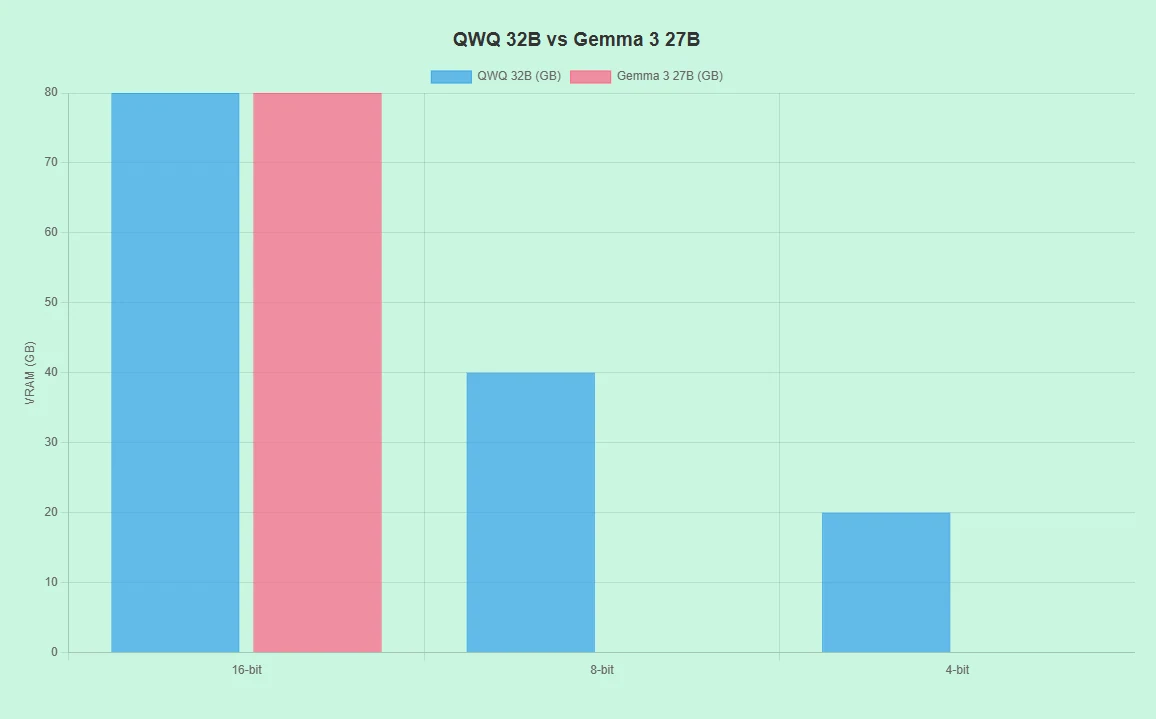
QwQ 32B 대 Gemma 3 27B: 하드웨어 요구 사항
QwQ 32B 대 Gemma 3 27B: 애플리케이션
QwQ 32B
유연한 배포:
- 다양한 하드웨어(예: RTX 4090, A100)를 16비트, 8비트, 4비트 정밀도로 지원합니다.
- 확장 가능하고 적응력이 뛰어난 AI 서비스에 이상적입니다.
비용 효율적인 솔루션:
- 8비트/4비트 모드에서 낮은 VRAM 요구로 비용 절감.
- 챗봇이나 추천 시스템 같은 예산 친화적인 애플리케이션에 적합합니다.
실시간 및 엣지 애플리케이션:
- 모바일/IoT 기기 및 실시간 AI 작업에 사용 가능.
- 예: 온디바이스 AI 또는 실시간 고객 지원 시스템.
맞춤형 파인튜닝:
- 중간급 GPU에서 도메인별 작업(예: 법률, 의료 모델)에 대한 효율적인 파인튜닝.
Gemma 3 27B
엔터프라이즈 규모 AI:
- 고성능 하드웨어(예: GPU 클러스터)용으로 설계되었습니다.
- 예: 요약 또는 번역과 같은 대규모 생성 AI.
클라우드 기반 AI 서비스:
- 중앙 집중식 NLP 서비스를 위한 경쟁력 있는 가격.
- 예: 기업용 클라우드 호스팅 API.
리소스 집약적 학습:
- 강력한 하드웨어에서 복잡한 모델을 학습하는 데 최적.
QwQ 32B 대 Gemma 3 27B: 작업
Prompt:
A password is considered strong if the below conditions are all met:
- It has at least 6 characters and at most 20 characters.
- It contains at least one lowercase letter, at least one uppercase letter, and at least one digit.
- It does not contain three repeating characters in a row (i.e., "Baaabb0" is weak, but "Baaba0" is strong).
Given a string password, return the minimum number of steps required to make password strong. if password is already strong, return 0.
In one step, you can:
- Insert one character to password,
- Delete one character from password, or
- Replace one character of password with another character.
Example 1:
Input: password = "a"
Output: 5
Example 2:
Input: password = "aA1"
Output: 3
Example 3:
Input: password = "1337C0d3"
Output: 0
Constraints:
1 <= password.length <= 50
password consists of letters, digits, dot '.' or exclamation mark '!'.
QwQ 32B
Gemma 3 27B
Novita API를 통해 QwQ 32B 및 Gemma 3 27B에 액세스하는 방법
1단계: 로그인 및 모델 라이브러리 액세스
계정에 로그인하고 모델 라이브러리 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.
3단계: 무료 체험 시작
선택한 모델의 기능을 살펴보기 위해 무료 체험을 시작하세요.
[지금 QwQ 32B 및 Gemma 3 27B 데모 사용해보기!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공합니다. “설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.

설치 후 필요한 라이브러리를 개발 환경에 가져오세요. API 키로 API를 초기화하여 Novita AI LLM과 상호 작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
확장 가능한 하드웨어 요구 사항을 가진 유연하고 비용 효율적인 AI의 경우 QwQ 32B 가 이상적인 선택입니다. 높은 정밀도와 리소스 집약적인 작업에는 Gemma 3 27B 가 더 나은 옵션입니다. 두 모델 모두 Novita AI의 API를 통해 사용 가능하며, 비교할 수 없는 접근성과 성능을 제공합니다. 지금 무료 체험을 시작하고 이 강력한 모델들의 기능을 경험해 보세요.
자주 묻는 질문
스타트업에는 어떤 모델이 더 적합한가요?
QwQ 32B 는 유연성, 낮은 하드웨어 요구 사항 및 비용 효율성으로 인해 더 적합합니다.
이 모델들을 엣지 디바이스에서 사용할 수 있나요?
QwQ 32B 는 낮은 정밀도 모드(8비트, 4비트)를 지원하여 엣지 및 실시간 애플리케이션에 적합합니다. Gemma 3 4B는 mlx-vlm을 통해 Apple silicon을 지원합니다.
QwQ 32B 및 Gemma 3 27B 에 대한 무료 체험이 있나요?**
예, [Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) 웹사이트에서 무료 체험을 시작하여 QwQ 32B 와 Gemma 3 27B 를 모두 탐색할 수 있습니다.
[Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) 는 개발자에게 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 방법을 제공하면서도, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.



