

Key Highlights
DeepSeek R1: With 671B parameters and a Mixture of Experts (MoE) architecture, DeepSeek R1 excels in advanced reasoning and specialized tasks like mathematics, coding, and general knowledge. It supports a 128K token context window but requires significant computational resources.
QWQ 32B: Compact and efficient with 32.5B parameters, QwQ-32B is optimized for broader applications. It supports a 32K token context window and features a high-performance transformer architecture (RoPE, SwiGLU, RMSNorm). It offers faster outputs, lower hardware demands, and cost-effective solutions for education, software development, and research.
If you’re looking to evaluate the DeepSeek R1 and QWQ 32B on your own use-cases — Upon registration, Novita AI provides a $0.5 credit to get you started!
This article offers a practical, informative, and technical comparison of two leading reasoning models: DeepSeek R1 and QwQ-32B. While both models are designed to advance AI reasoning capabilities, they differ significantly in architecture, training methods, and hardware requirements. Notably, QwQ-32B was launched shortly after DeepSeek’s open-source week, suggesting it may have drawn inspiration from DeepSeek’s innovations. This article explores these distinctions to help users determine which model best fits their specific needs.
Basic Introduction of Model
To begin our comparison, we first understand the fundamental characteristics of each model.
DeepSeek R1
- Release Date: January 21, 2025
- Model Scale:
- Key Features:
- Model Size: 671B parameters (37B active/token)
- Tokenizer: Enhanced tokenizer with self-reflection tags
- Supported Languages: Multilingual with cultural adaptation
- Multimodal: Text-only
- Context Window: 128K tokens
- Storage Formats: Q8/Q5 quantization support
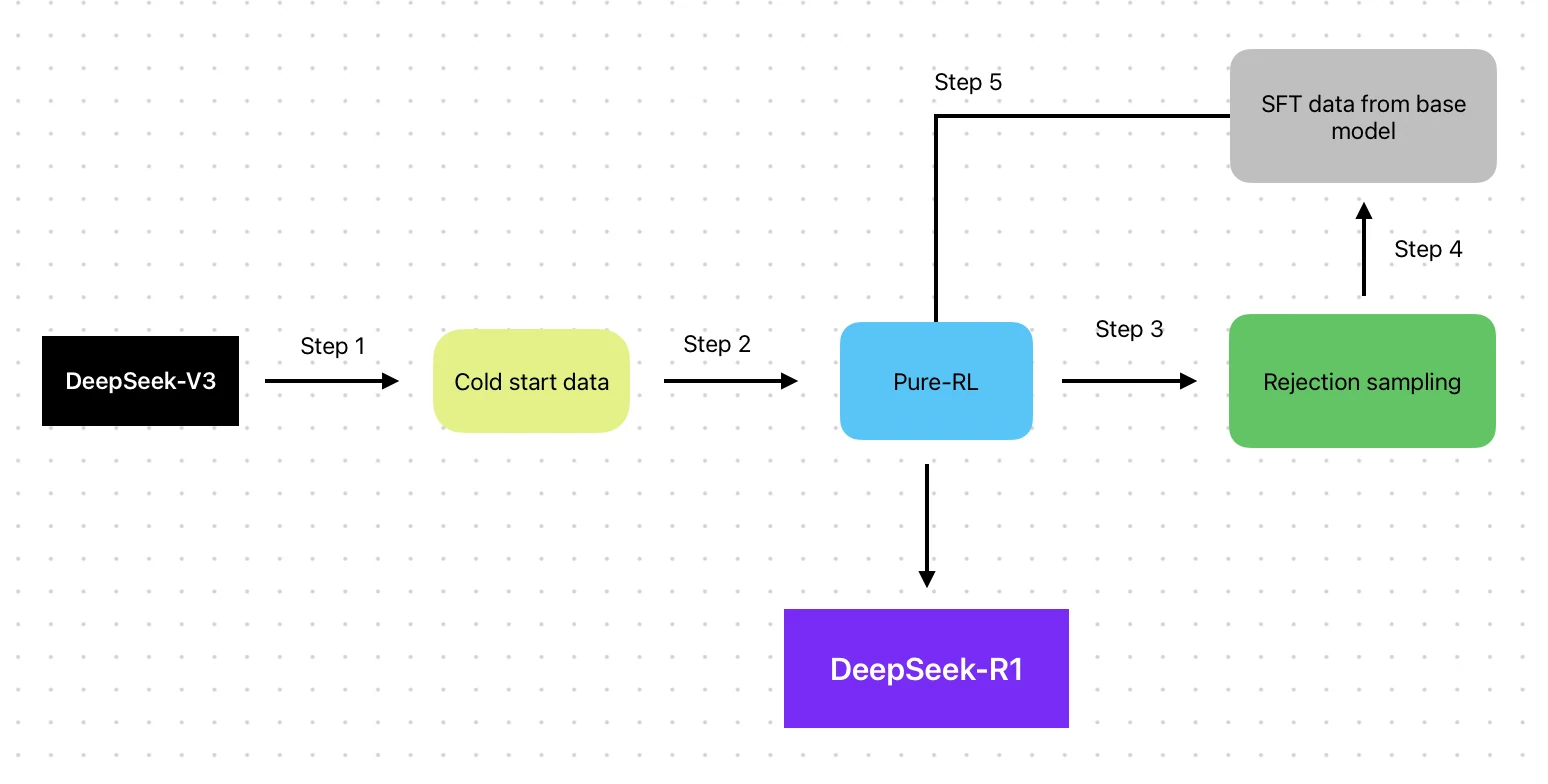
- Architecture: Mixture of Experts (MoE) + RL-enhanced training pipeline
- Training Method: Built on V3 base with RL pipeline (SFT → RL → SFT → RL)
- Training Data: V3 base + RL optimization data
QWQ 32B
- Release Date: March 5, 2025
- Model Scale:
- Key Features:
- Model Size: A total of 32.5 billion parameters, with 31.0 billion non-embedding parameters.
- Supported Languages: Covers over 29 languages for global accessibility and application.
- Multimodal: Text-only
- Context Window: Supports up to 32,768 tokens.
- Architecture:QwQ-32B uses a transformer architecture with 64 layers, 40 attention heads for queries, and 8 for key-values. Built on transformers with RoPE (Rotary Positional Embeddings), QwQ-32B integrates the SwiGLU activation function, employs RMSNorm for normalization, and includes bias in attention QKV computations.
QwQ-32B focuses on RL-only optimization for efficiency and independence.
DeepSeek R1 integrates both SFT and RL in a balanced, iterative process but retains partial SFT reliance.
Speed Comparison
If you want to test it yourself, you can start a free trial on the Novita AI website.
Try DeepSeek R1 and QWQ 32B Demo Now!
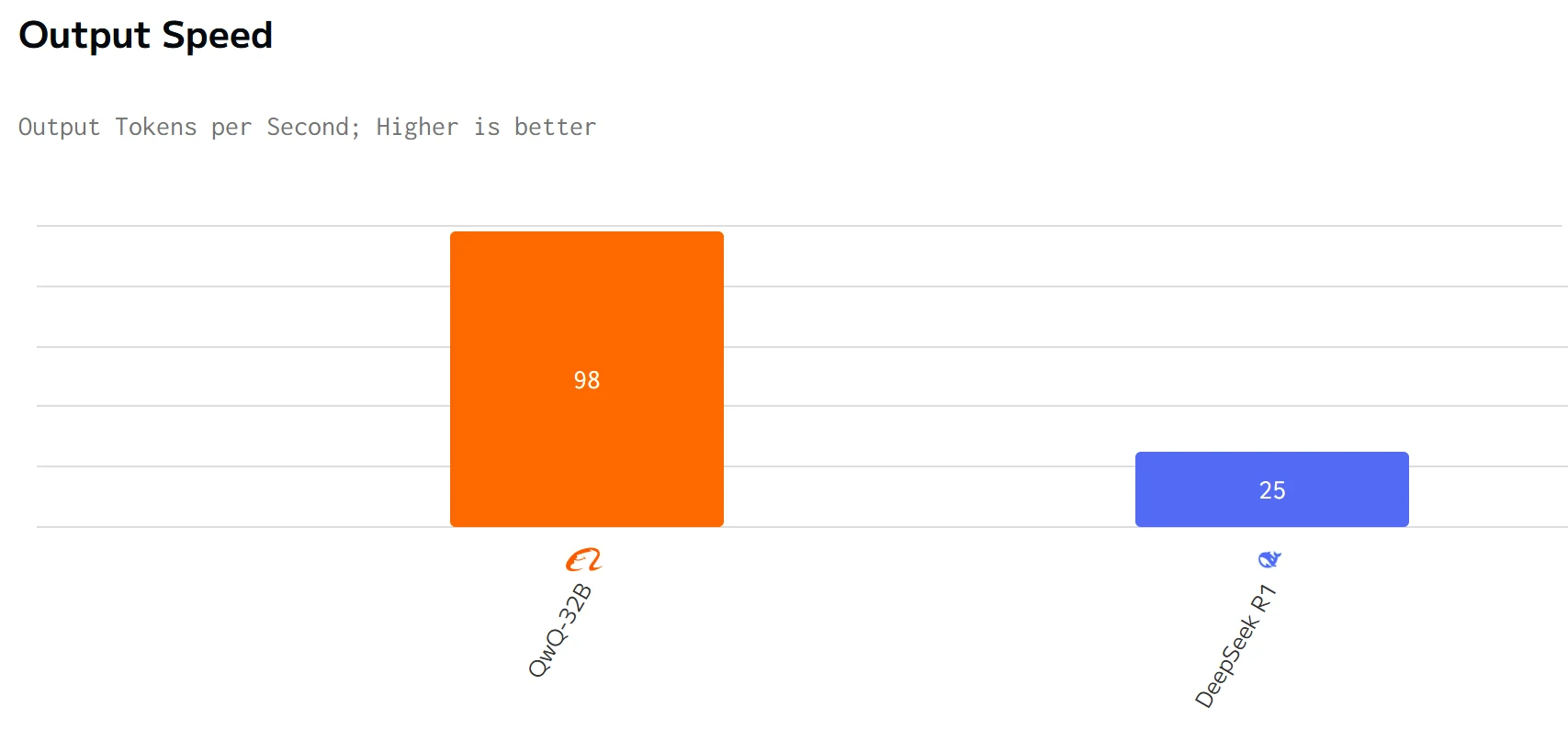
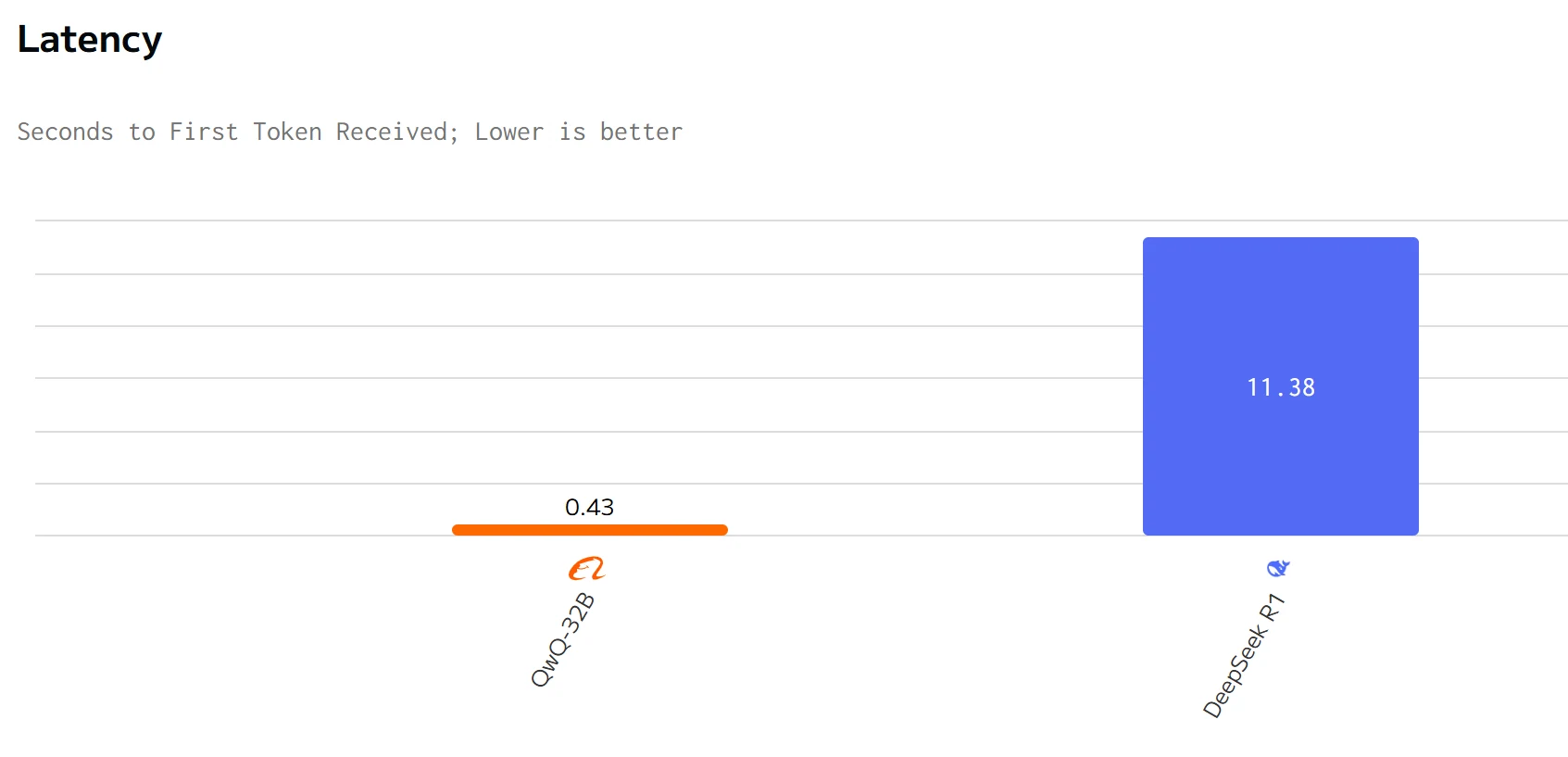
Speed Comparison
Cost Comparison
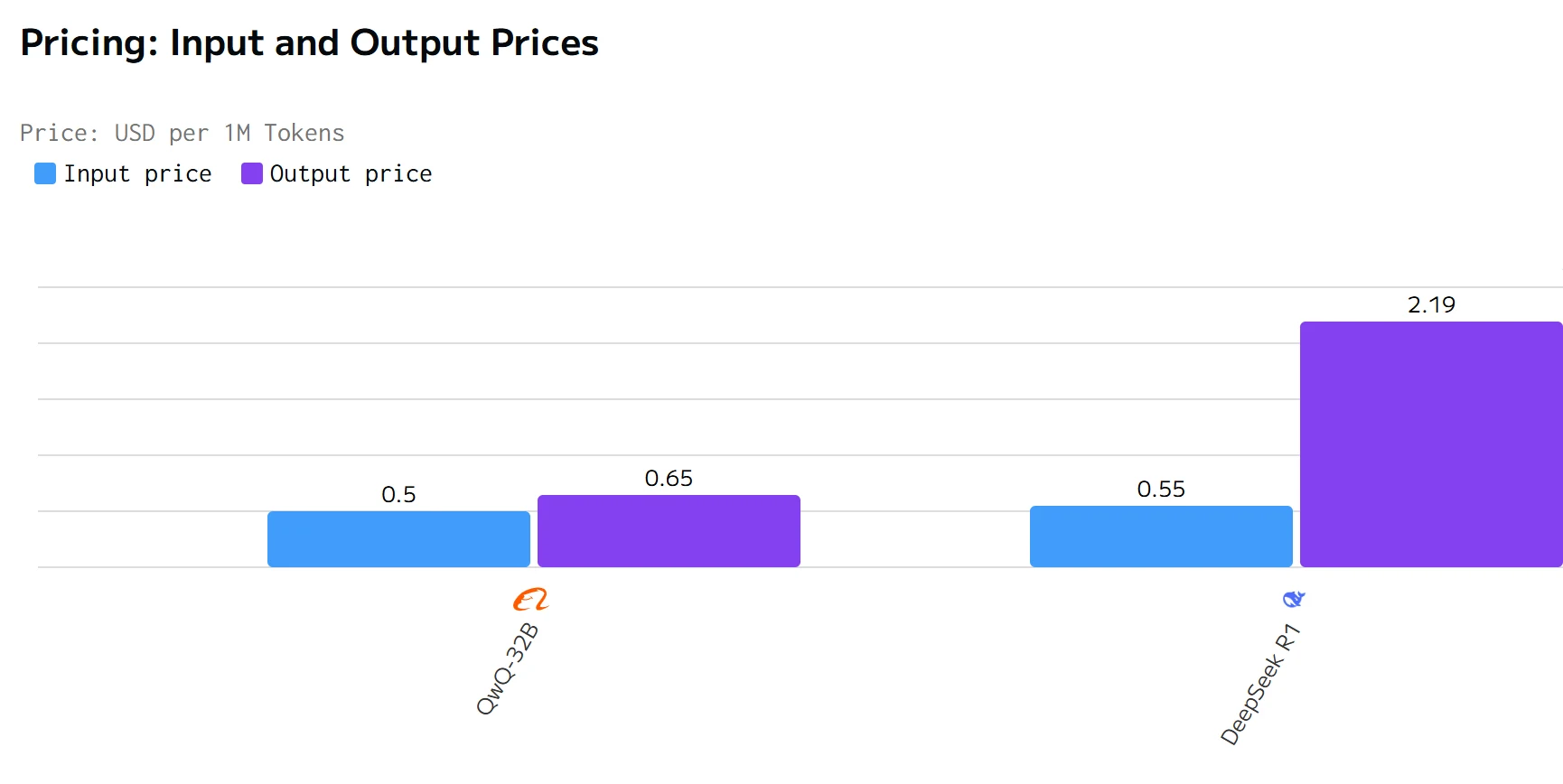
QWQ 32B surpasses DeepSeek R1 in output speed and latency. The input and output prices of DeepSeek R1 are significantly higher than those of QWQ 32B.
It is worth noting that Novita AI launches a Turbo version with 3x throughput and a limited-time 20% discount!

Benchmark Comparison
Now that we’ve established the basic characteristics of each model, let’s delve into their performance across various benchmarks. This comparison will help illustrate their strengths in different areas.
| Benchmark | DeepSeek-R1 (%) | QWQ 32B (%) |
|---|---|---|
| LiveCodeBench (Coding) | 62 | 22 |
| GPQA Diamond | 71 | 59 |
| MATH-500 | 96 | 91 |
| MMLU-Pro | 84 | 76 |
These results suggest that DeepSeek R1’s machine-driven iterative reinforcement learning approach may be particularly effective for developing stronger capabilities in specialized technical domains requiring precise reasoning and structured problem-solving skills.
If you want to see more comparisons, you can check out these articles:
- Deepseek v3 vs Llama 3.3 70b: Language Tasks vs Code & Math
- DeepSeek R1 vs OpenAI o1: Distinct Architectures of GRPO and PPO
- QwQ 32B: A Compact AI Rival to DeepSeek R1
Hardware Requiremments
| Model | Parameter Size | GPU Configuration |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090 (24GB VRAM) with model sharding |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100 (80GB VRAM) or 2 x RTX 4090 (24GB VRAM) with tensor parallelism |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (80GB VRAM) or 1 x NVIDIA H100 (80GB VRAM) or 4 x RTX 4090 (24GB VRAM) with tensor parallelism |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (80GB VRAM) or 2 x NVIDIA H100 (80GB VRAM) or 8 x RTX 4090 (24GB VRAM) with heavy parallelism |
| DeepSeek-R1:671B | 671B (37 billion active parameters) | 16 x NVIDIA A100 (80GB VRAM) or 8 x NVIDIA H100 (80GB VRAM), requires a distributed GPU cluster with InfiniBand |
| QwQ-32B (4-bit precision) | 32B | 1 x NVIDIA RTX 3090/4090 (24GB VRAM), compatible with 4-bit quantization |
| 1 x NVIDIA RTX 6000 (48GB VRAM), compatible with 4-bit quantization | ||
| 1 x NVIDIA H100 (80GB VRAM) or 2 x NVIDIA A100 (80GB VRAM) |
Applications and Use Cases
DeepSeek R1
- Mathematics: Capable of solving advanced mathematical problems, including symbolic reasoning, equation solving, and optimization tasks, making it well-suited for STEM-related applications.
- Coding: Excels in generating complex code, understanding intricate logic, and debugging large-scale software projects, making it a valuable tool for developers and engineers.
- General Knowledge: Demonstrates strong reasoning across a wide range of topics, making it ideal for tasks requiring deep understanding and accurate synthesis of diverse knowledge domains.
QWQ 32B
- Education: Provides highly personalized tutoring in mathematics and programming, offering step-by-step explanations and adaptive learning based on the user’s progress and needs.
- Software Development: Assists developers by generating accurate and efficient code snippets, debugging errors, and offering recommendations for optimizing and improving code performance.
- Research: Supports researchers with advanced data analysis, summarizing academic literature, and offering insights into complex datasets, making it a powerful assistant for research tasks.
Accessibility and Deployment through Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Try DeepSeek R1 and QWQ 32B Demo Now!
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Upon registration, Novita AI provides a $0.5 credit to get you started!
If the free credits is used up, you can pay to continue using it.
Both DeepSeek R1 and QwQ-32B are advanced reasoning models, each with unique strengths.
- DeepSeek R1: With its large parameter size and MoE (Mixture of Experts) architecture, it is designed to handle highly complex reasoning tasks. However, this capability comes with the need for substantial computational resources.
- QwQ-32B: In contrast, QwQ-32B provides a more compact and hardware-efficient solution, delivering competitive performance while being accessible on less demanding hardware setups.
The decision between the two models ultimately depends on the specific application requirements, the available hardware, and budget considerations.
Frequently Asked Questions
What makes QwQ-32B unique?
QwQ-32B stands out for its use of reinforcement learning without supervised fine-tuning, achieving exceptional performance in reasoning tasks, particularly in mathematics and coding.
What is the key difference between QwQ-32B and Qwen2.5?
QwQ-32B builds on Qwen2.5, adding reinforcement learning optimization specifically for reasoning tasks, without using traditional supervised fine-tuning approaches.
How to access QWQ 32B via API?
Novita AI providing the affordable and reliable QWQ 32B API for you.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



