

Key Highlights
Reinforcement Learning (RL): Utilizes a two-stage RL process to refine reasoning via trial-and-error, verified by tools like code interpreters and solvers, ensuring accurate result.
Competitive Benchmarks: Achieves strong scores on reasoning and coding tasks:
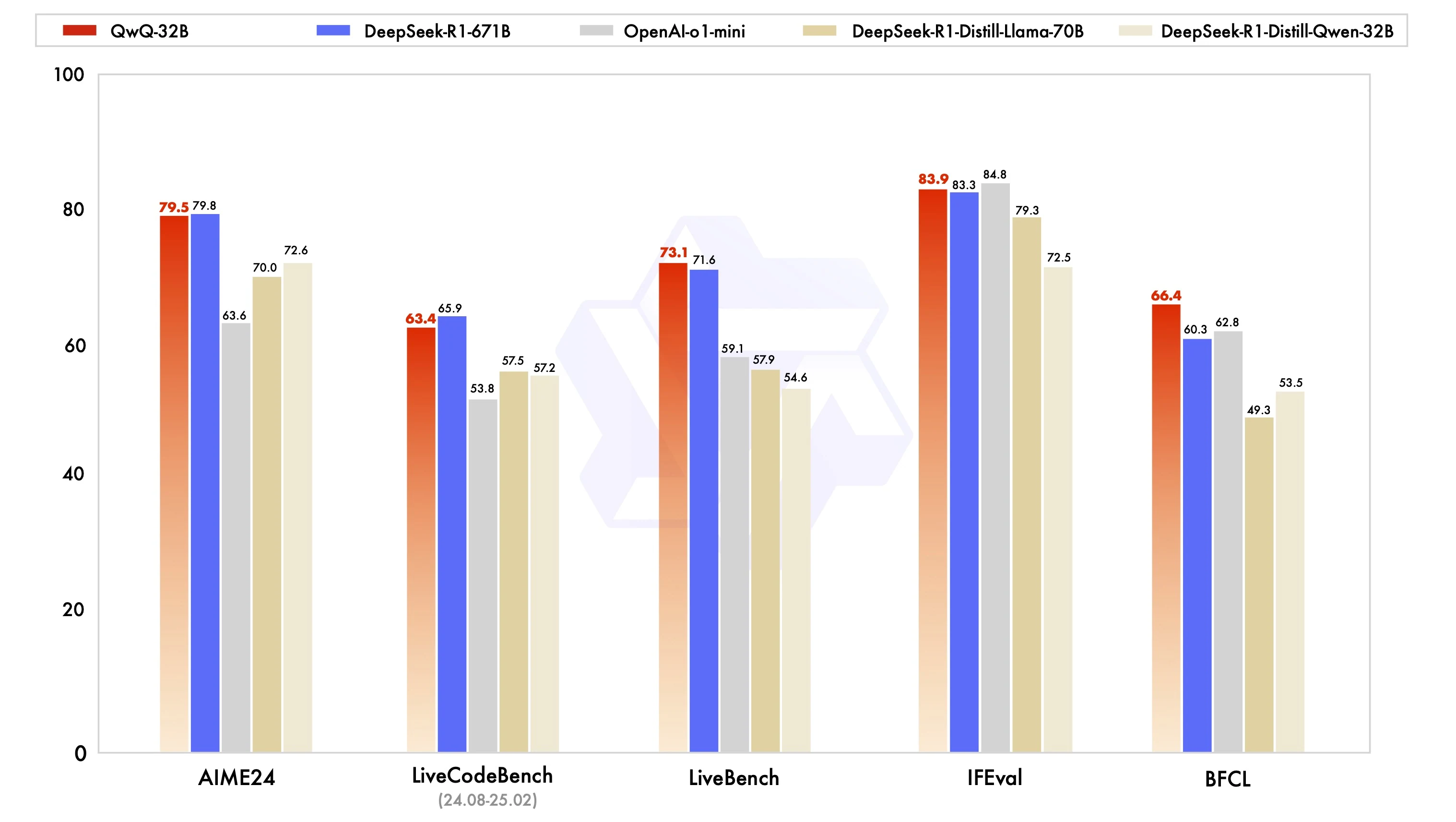
AIME24: 79.5 (close to DeepSeek R1’s 79.8).
IFEval: 83.9 (slightly above DeepSeek R1).
BFCL: 66.4 (outperforming DeepSeek R1’s 60.3).
Hardware Efficiency: Requires significantly less VRAM than DeepSeek R1; supports quantization to run on smaller hardware setups.
If you’re looking to evaluate the QWQ 32B on your own use-cases — Upon registration, Novita AI provides a $0.5 credit to get you started!
QwQ-32B, developed by Alibaba’s Qwen Team, is a 32.5-billion parameter reasoning model that delivers performance comparable to much larger models like DeepSeek-R1, while leveraging significantly fewer parameters. Its efficiency and strong reasoning capabilities make it an ideal choice for researchers, developers, and organizations seeking high performance without the heavy resource demands of traditional large language models (LLMs).
What is QwQ-32B?
Basic Introduction
- qwen/qwq-32b
- Open Source: Available under Apache 2.0 license, enabling community contributions and improvements.
- Transformers: QwQ-32B uses a transformer architecture with 64 layers, 40 attention heads for queries, and 8 for key-values. Built on transformers with RoPE (Rotary Positional Embeddings), QwQ-32B integrates the SwiGLU activation function, employs RMSNorm for normalization, and includes bias in attention QKV computations.
- Parameters: A total of 32.5 billion parameters, with 31.0 billion non-embedding parameters.
- Long Context Support: Supports up to 32,768 tokens.
- Support Languages: Covers over 29 languages for global accessibility and application.
Training Methods
Building on Qwen2.5, QwQ-32B specifically optimizes reasoning tasks through RL, showcasing potential innovation by eliminating the dependency on traditional supervised fine-tuning (SFT) methods.
Moreover, QwQ-32B utilizes reinforcement learning (RL) to refine its reasoning abilities, relying on trial and error to adapt its approach using tools and environmental feedback. By employing an “outcome-based rewards” mechanism, the model generates results independently, which are then verified for accuracy, ensuring reliable performance in structured tasks. This departure from SFT highlights its focus on efficiency and adaptability, marking a shift toward more direct RL-driven optimization.
Benchmark
From Qwen
QwQ-32B punches above its weight: It matches or exceeds the performance of larger models, such as DeepSeek-R1-671B, in several benchmarks, despite having fewer parameters. The model demonstrates strong general reasoning, coding, and inference skills but not creative contents, making it versatile across diverse tasks.
Hardware Requirements
To run QwQ-32B efficiently, consider the following hardware requirements:
- VRAM:
- Requires substantial VRAM.
- For 16-bit precision, 80GB VRAM is needed.
- For 8-bit precision, 40GB VRAM is sufficient.
- For 4-bit precision, only 20GB VRAM is required.
- GPUs:
- Compatible with RTX 3090/4090 GPUs, especially when using quantization.
- High-end GPUs like NVIDIA A100 and H100 are also suitable.
Compared to DeepSeek R1, QwQ-32B significantly reduces hardware requirements, making it more accessible for diverse systems while maintaining strong performance.
Applictions
- Education:
- Provides personalized tutoring in mathematics and programming, catering to learners of different skill levels.
- Explains complex concepts in simple terms, making it a valuable tool for students and educators alike.
- Assists in solving homework problems and generating practice exercises for effective learning.
- Software Development:
- Supports developers by generating high-quality code snippets for various programming languages.
- Assists in debugging by identifying errors and suggesting appropriate fixes.
- Offers recommendations for optimizing code efficiency and adhering to best practices.
- Research:
- Aids researchers in conducting data analysis, including statistical computations and visualization.
- Helps with literature reviews, summarizing academic papers, and extracting key insights.
- Generates initial drafts for research documents, saving valuable time for researchers.
- Problem-Solving:
- Assists in breaking down complex problems into smaller, manageable components.
- Suggests potential solutions, including step-by-step guidance for multi-faceted challenges.
- Provides logical reasoning and explanations to support decision-making processes.
By excelling in these areas, QwQ-32B serves as a versatile assistant for educational, professional, and research-related tasks
QWQ 32B vs Qwen 2.5 72B vs DeepSeek R1
| Feature | QwQ-32B | Qwen 2.5 72B | DeepSeek-R1 671B |
|---|---|---|---|
| Parameters | 32.5B | 72B | 671B |
| Architecture Base | Qwen 2.5 | Native architecture | DeepSeek-R1-Zero |
| Training Method | Reinforcement Learning (no SFT) | Not specifically stated | RL + Supervised Fine-tuning |
| Context Window | 32,768 tokens | 8,000 tokens | 32,768 tokens |
| Language Support | 29+ languages | 29+ languages | Primarily Chinese and English |
| Mathematical Ability | 79.5 (AIME 2024) | 83.1 (MATH benchmark) | 97.3 (MATH-500), 79.8 (AIME 2024) |
| Coding Ability | 63.4 (Live Code Bench) | 59.1 (HumanEval) | 49.2 (SWE-bench Verified), 65.9 (Live Code Bench) |
| Hardware Requirements | 4-bit: 20GB VRAM/8-bit: 40GB VRAM/16-bit: 80GB VRAM, preferably with multiple A100s or H100s | approximately 41.6 GB to 77.1 GB of VRAM | 8xH100 GPUs |
| Open Source License | Apache 2.0 | Not specifically stated | MIT License |
| Key Advantages | Hardware-friendly/Strong reasoning/Comparable to larger models | Fast response time/Cost-effective/Good multilingual support | Exceptional math reasoning/Self-checking outputs/Clear reasoning process |
| Output Characteristics | Strong logical reasoning, weaker creative content | General capabilities | Clear logic, well-structured |
How to Access QWQ 32B?
1. Use Online Platforms to Access QWQ 32B (e.g. Novita AI)
You can find LLM Playground page of Novita AI for a free trial! This is the test page we provide specifically for developers! Select the model from the list that you desired. Here you can choose the QWQ 32B model.
2.Access Free QWQ 32B APIs (e.g. Novita AI)
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)Upon registration, Novita AI provides a $0.5 credit to get you started!
If the free credits is used up, you can pay to continue using it.
Conclusion
QwQ-32B represents a significant advancement in AI reasoning models, delivering exceptional performance in mathematics, coding, and multi-step problem-solving, all while maintaining a relatively compact size. With its open-source availability and efficient design, it serves as a powerful tool for researchers, developers, and engineers looking to harness AI for complex and structured tasks.
What makes QwQ-32B unique?
QwQ-32B stands out for its use of reinforcement learning without supervised fine-tuning, achieving exceptional performance in reasoning tasks, particularly in mathematics and coding.
What are the hardware requirements?
For optimal performance, QwQ-32B requires significant computational resources. The quantized 4-bit version needs approximately 20GB of VRAM.
What’s the difference between QwQ-32B and Qwen2.5?
QwQ-32B builds on Qwen2.5, adding reinforcement learning optimization specifically for reasoning tasks, without using traditional supervised fine-tuning approaches.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



