

Ключевые моменты
QwQ 32B: Отлично справляется со сложными задачами, граничными случаями и сценариями, требующими гибкости. Поддерживает 16-битную, 8-битную и 4-битную точность, что делает её эффективной для приложений реального времени и чувствительных к затратам.
Gemma 3 27B: Оптимизирована для высокоточных задач с поддержкой FP16, но испытывает трудности с граничными случаями и длинными паролями. Лучше всего работает в средах с большими ресурсами.
[Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) предоставляет не только стабильные API-сервисы, но и чрезвычайно выгодные цены. Например, Gemma 3 27B стоит всего $0.119 за 1 млн входных токенов и $0.2 за 1 млн выходных токенов, а QwQ 32B стоит $0.18 за 1 млн входных токенов и $0.2 за 1 млн выходных токенов.
QwQ 32B против Gemma 3 27B: Основное введение
Знакомство с QwQ 32B

Знакомство с Gemma 3 27B

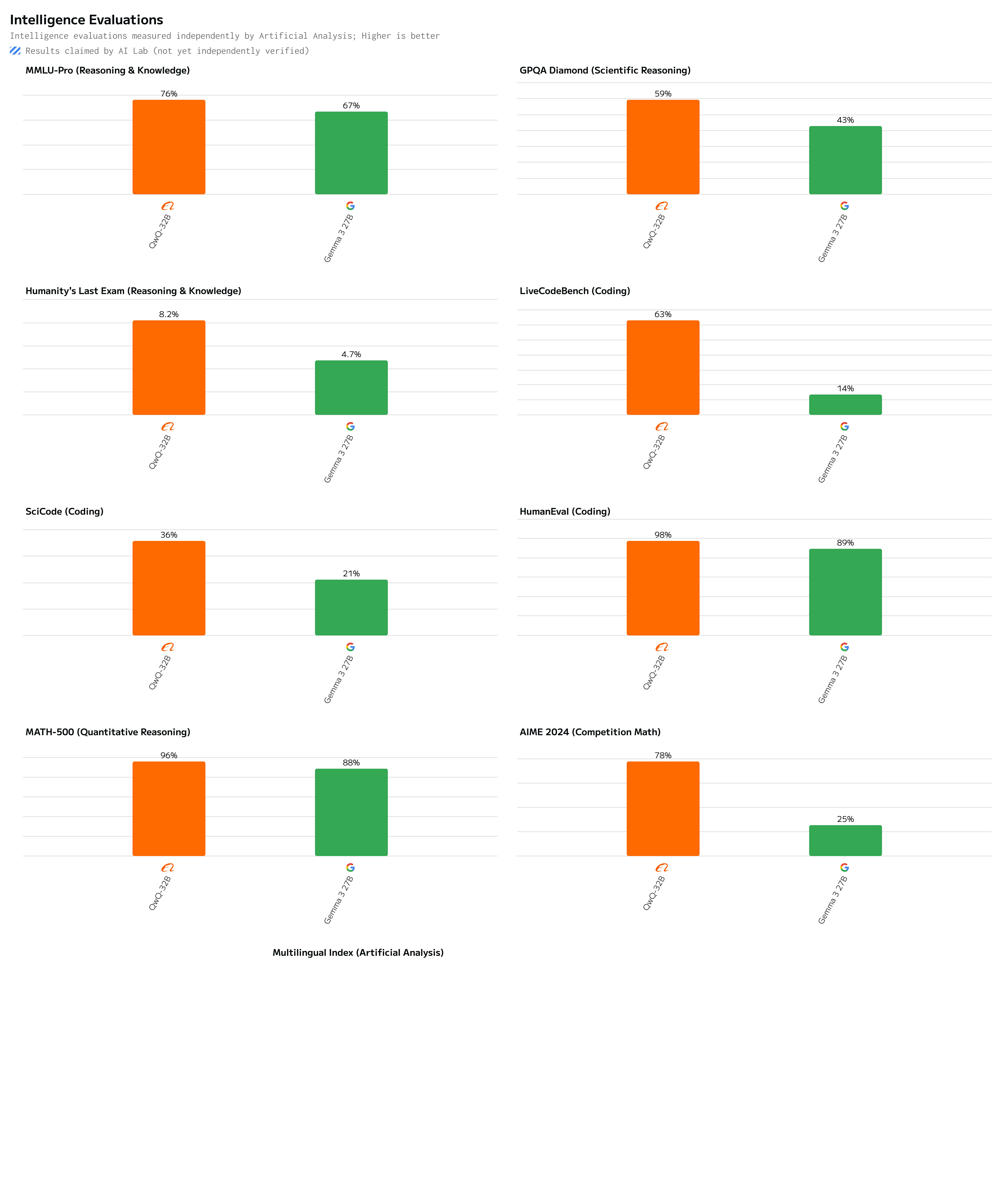
QwQ 32B против Gemma 3 27B: Бенчмарки
QwQ 32B превосходит Gemma 3 27B во всех тестах. Это указывает на то, что QwQ 32B демонстрирует более высокие возможности и лучшую универсальность в задачах из разных доменов, в то время как Gemma 3 27B может преуспевать в определённых областях, но в целом отстаёт.
Если хотите проверить это сами, начните бесплатную пробную версию на сайте Novita AI.

[Попробуйте демо QwQ 32B и Gemma 3 27B прямо сейчас!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
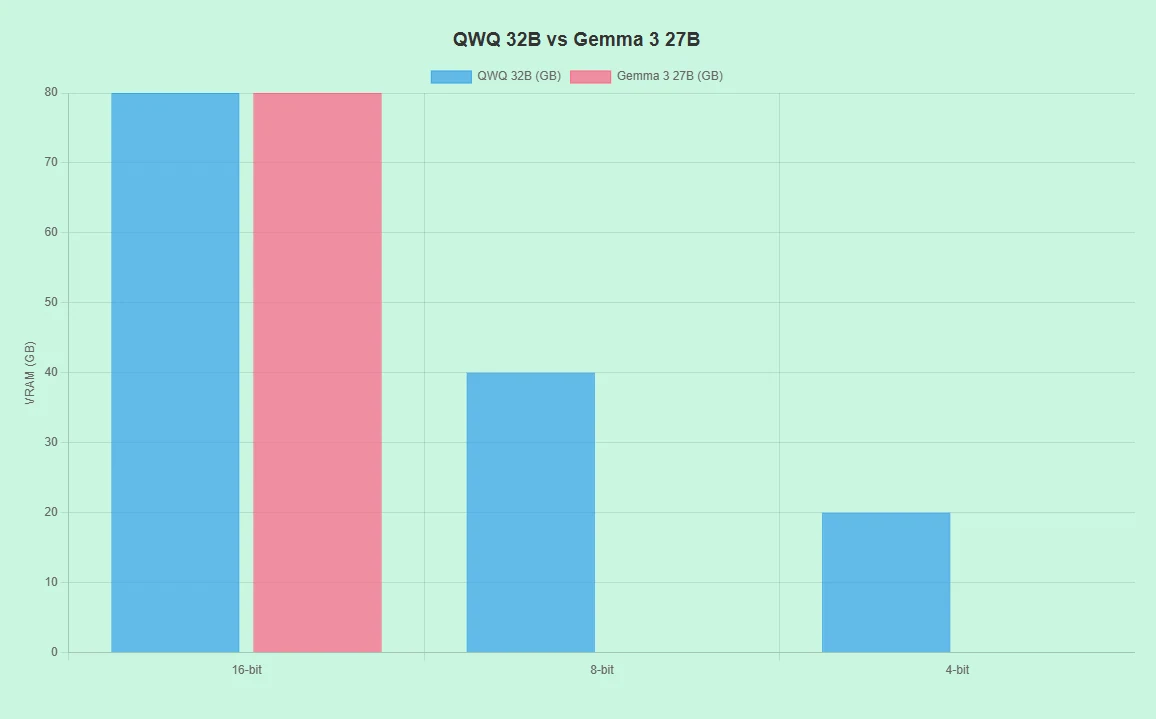
QwQ 32B против Gemma 3 27B: Требования к оборудованию
QwQ 32B против Gemma 3 27B: Применение
QwQ 32B
Гибкое развёртывание:
- Поддерживает различное оборудование (например, RTX 4090, A100) с 16-битной, 8-битной и 4-битной точностью.
- Идеально подходит для масштабируемых и адаптируемых AI-сервисов.
Экономичные решения:
- Низкие требования к VRAM в 8-битном/4-битном режимах снижают затраты.
- Подходит для бюджетных приложений, таких как чат-боты или системы рекомендаций.
Приложения реального времени и на периферии:
- Работает на мобильных/IoT-устройствах и для задач AI в реальном времени.
- Пример: AI на устройстве или системы живой поддержки клиентов.
Пользовательская тонкая настройка:
- Эффективная тонкая настройка на среднеуровневых GPU для узкоспециализированных задач (например, юридические, медицинские модели).
Gemma 3 27B
Корпоративный AI:
- Разработана для высокопроизводительного оборудования (например, кластеры GPU).
- Пример: Крупномасштабный генеративный AI, такой как суммаризация или перевод.
Облачные AI-сервисы:
- Конкурентоспособные цены для централизованных NLP-сервисов.
- Пример: Облачные API для бизнеса.
Ресурсоёмкое обучение:
- Лучше всего подходит для обучения сложных моделей на мощном оборудовании.
QwQ 32B против Gemma 3 27B: Задачи
Prompt:
Пароль считается надёжным, если выполнены все следующие условия:
- Он содержит не менее 6 и не более 20 символов.
- Он содержит хотя бы одну строчную букву, хотя бы одну заглавную букву и хотя бы одну цифру.
- Он не содержит трёх повторяющихся символов подряд (например, "Baaabb0" — слабый, а "Baaba0" — сильный).
Дана строка password, верните минимальное количество шагов, необходимых для того, чтобы сделать пароль сильным. Если пароль уже сильный, верните 0.
За один шаг можно:
- Вставить один символ в пароль,
- Удалить один символ из пароля или
- Заменить один символ пароля на другой.
Пример 1:
Input: password = "a"
Output: 5
Пример 2:
Input: password = "aA1"
Output: 3
Пример 3:
Input: password = "1337C0d3"
Output: 0
Ограничения:
1 <= password.length <= 50
password состоит из букв, цифр, точки '.' или восклицательного знака '!'.
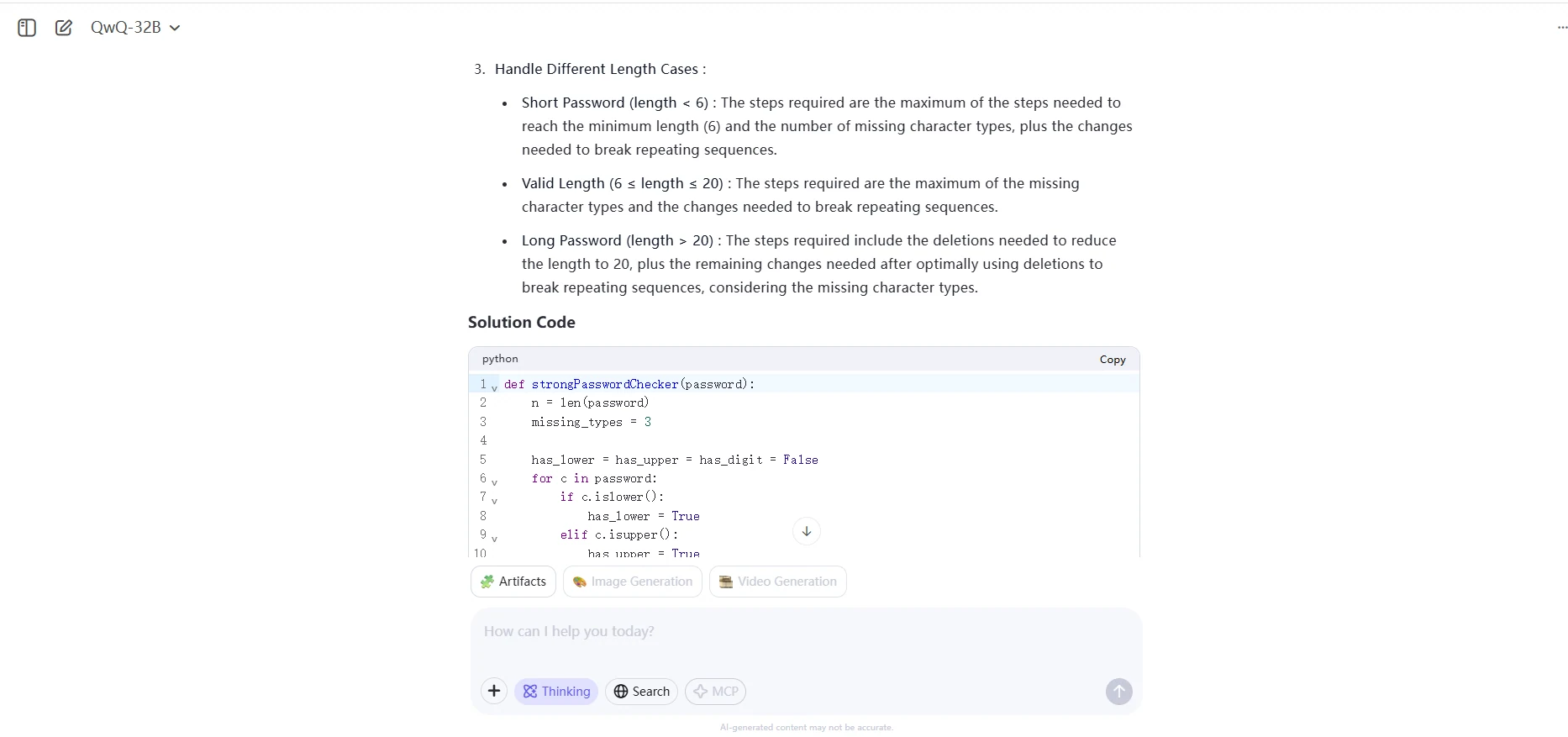
QwQ 32B
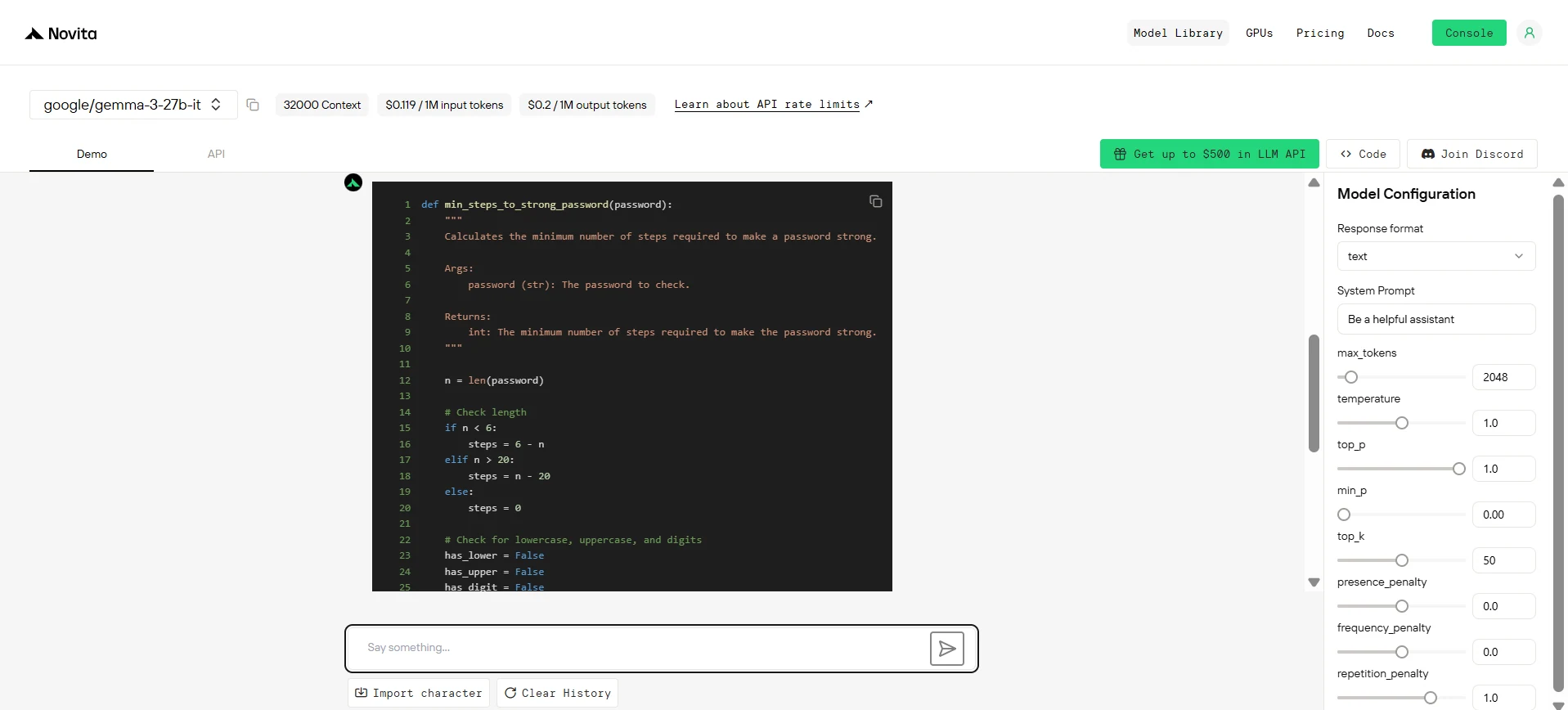
Gemma 3 27B
Как получить доступ к QwQ 32B и Gemma 3 27B через Novita API?
Шаг 1: Войдите и перейдите в библиотеку моделей
Войдите в свою учётную запись и нажмите на кнопку Model Library.

Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших нужд.
Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.
[Попробуйте демо QwQ 32B и Gemma 3 27B прямо сейчас!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
Шаг 4: Получите API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдите на страницу Settings и скопируйте API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования API завершений чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Для гибкого, экономичного AI с масштабируемыми требованиями к оборудованию QwQ 32B — идеальный выбор. Для высокоточных ресурсоёмких задач Gemma 3 27B — лучший вариант. Обе модели доступны через API Novita AI, что обеспечивает непревзойдённую доступность и производительность. Начните бесплатную пробную версию сегодня и ощутите возможности этих мощных моделей.
Часто задаваемые вопросы
Какая модель лучше для стартапов?
QwQ 32B лучше благодаря своей гибкости, меньшим требованиям к оборудованию и экономической эффективности.
Могу ли я использовать эти модели на периферийных устройствах?
QwQ 32B поддерживает режимы с пониженной точностью (8-битный, 4-битный), что делает её подходящей для периферийных и real-time приложений. Gemma 3 4B поддерживает Apple Silicon через mlx-vlm.
Есть ли бесплатная пробная версия для QwQ 32B и Gemma 3 27B?
Да, вы можете начать бесплатную пробную версию на сайте [Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b), чтобы изучить обе модели QwQ 32B и Gemma 3 27B.
[Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предлагает доступные и надёжные GPU-облака для создания и масштабирования.



