

Key Highlights
QwQ 32B: Excels in handling complex tasks, edge cases, and scenarios requiring flexibility. Supports 16-bit, 8-bit, and 4-bit precision, making it efficient for real-time and cost-sensitive applications.
Gemma 3 27B: Optimized for high-precision tasks with FP16 support, but struggles with edge cases and long passwords. Performs best in high-resource environments.
[Novita AI](ttps://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) not only provides stable API services but also offers extremely cost-effective pricing. For example, Gemma 3 27B costs only $0.119 per 1M input tokens and $0.2 per 1M output tokens, while QwQ 32B costs $0.18 per 1M input tokens and $0.2 per 1M output tokens.
QwQ 32B vs Gemma 3 27B: Basic Introduction
QwQ 32B Introduction

Gemma 3 27B Introduction

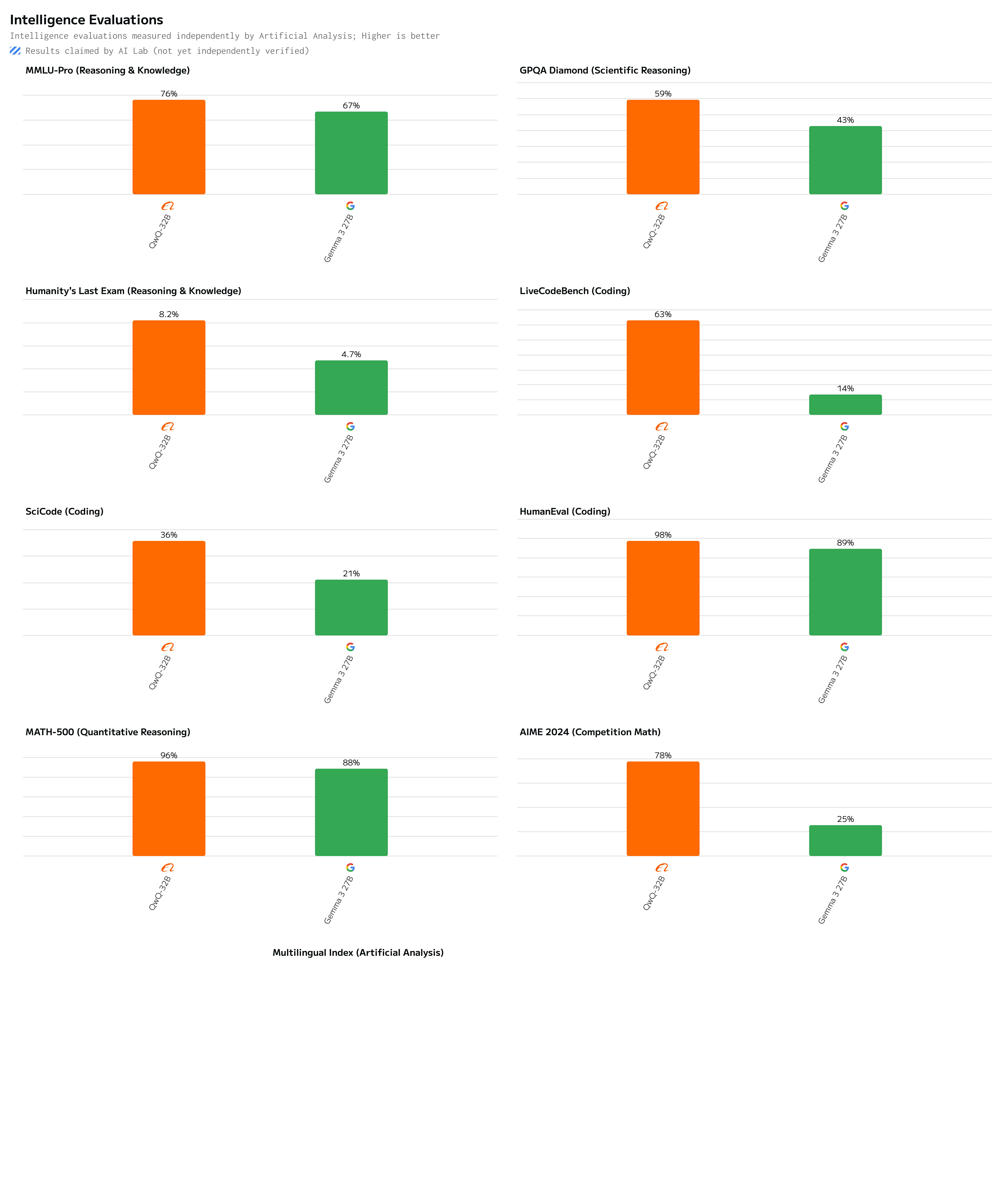
QwQ 32B vs Gemma 3 27B: Benchmark
QwQ 32B outperforms Gemma 3 27B in all tests. This indicates that QwQ 32B demonstrates stronger capabilities and better versatility across multi-domain tasks, while Gemma 3 27B may excel in certain specific areas but lags overall.
If you want to test it yourself, you can start a free trial on the Novita AI website.

[Try QwQ 32B and Gemma 3 27B Demo Now!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
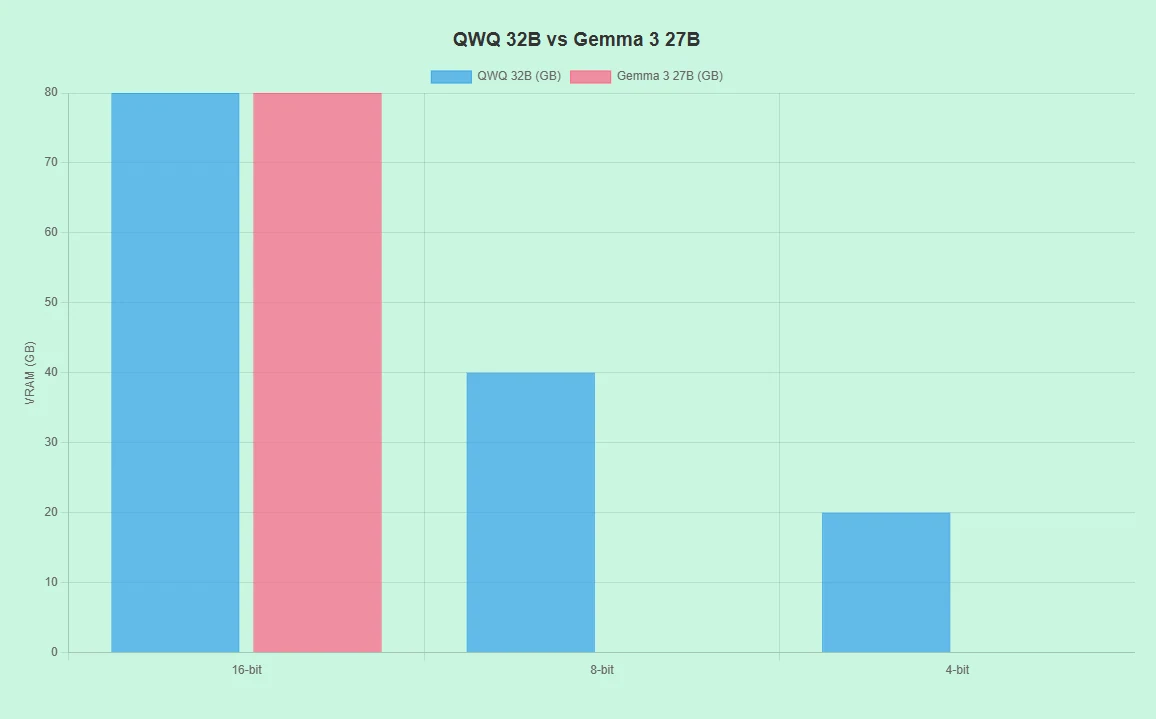
QwQ 32B vs Gemma 3 27B: Hardware Requirements
QwQ 32B vs Gemma 3 27B: Applications
QwQ 32B
Flexible Deployment:
- Supports varying hardware (e.g., RTX 4090, A100) with 16-bit, 8-bit, and 4-bit precision.
- Ideal for scalable and adaptable AI services.
Cost-Efficient Solutions:
- Low VRAM demand in 8-bit/4-bit modes reduces costs.
- Suitable for budget-friendly applications like chatbots or recommendation systems.
Real-Time and Edge Applications:
- Works for mobile/IoT devices and real-time AI tasks.
- Example: On-device AI or live customer support systems.
Custom Fine-Tuning:
- Efficient fine-tuning on mid-tier GPUs for domain-specific tasks (e.g., legal, medical models).
Gemma 3 27B
Enterprise-Scale AI:
- Designed for high-performance hardware (e.g., GPU clusters).
- Example: Large-scale generative AI like summarization or translation.
Cloud-Based AI Services:
- Competitive pricing for centralized NLP services.
- Example: Cloud-hosted APIs for businesses.
Resource-Intensive Training:
- Best for training complex models on powerful hardware.
QwQ 32B vs Gemma 3 27B: Tasks
Prompt:
A password is considered strong if the below conditions are all met:
- It has at least 6 characters and at most 20 characters.
- It contains at least one lowercase letter, at least one uppercase letter, and at least one digit.
- It does not contain three repeating characters in a row (i.e., "Baaabb0" is weak, but "Baaba0" is strong).
Given a string password, return the minimum number of steps required to make password strong. if password is already strong, return 0.
In one step, you can:
- Insert one character to password,
- Delete one character from password, or
- Replace one character of password with another character.
Example 1:
Input: password = "a"
Output: 5
Example 2:
Input: password = "aA1"
Output: 3
Example 3:
Input: password = "1337C0d3"
Output: 0
Constraints:
1 <= password.length <= 50
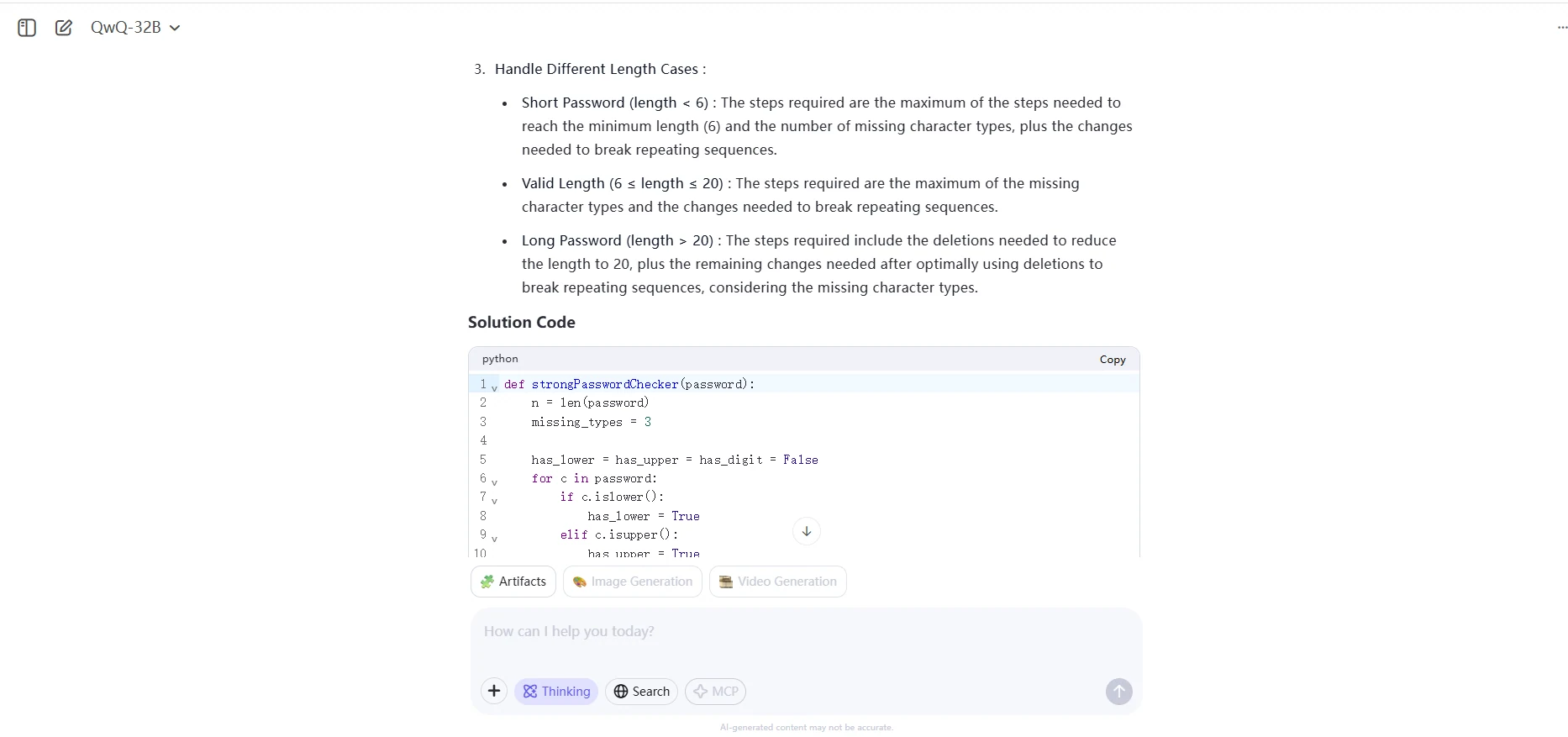
password consists of letters, digits, dot '.' or exclamation mark '!'.QwQ 32B
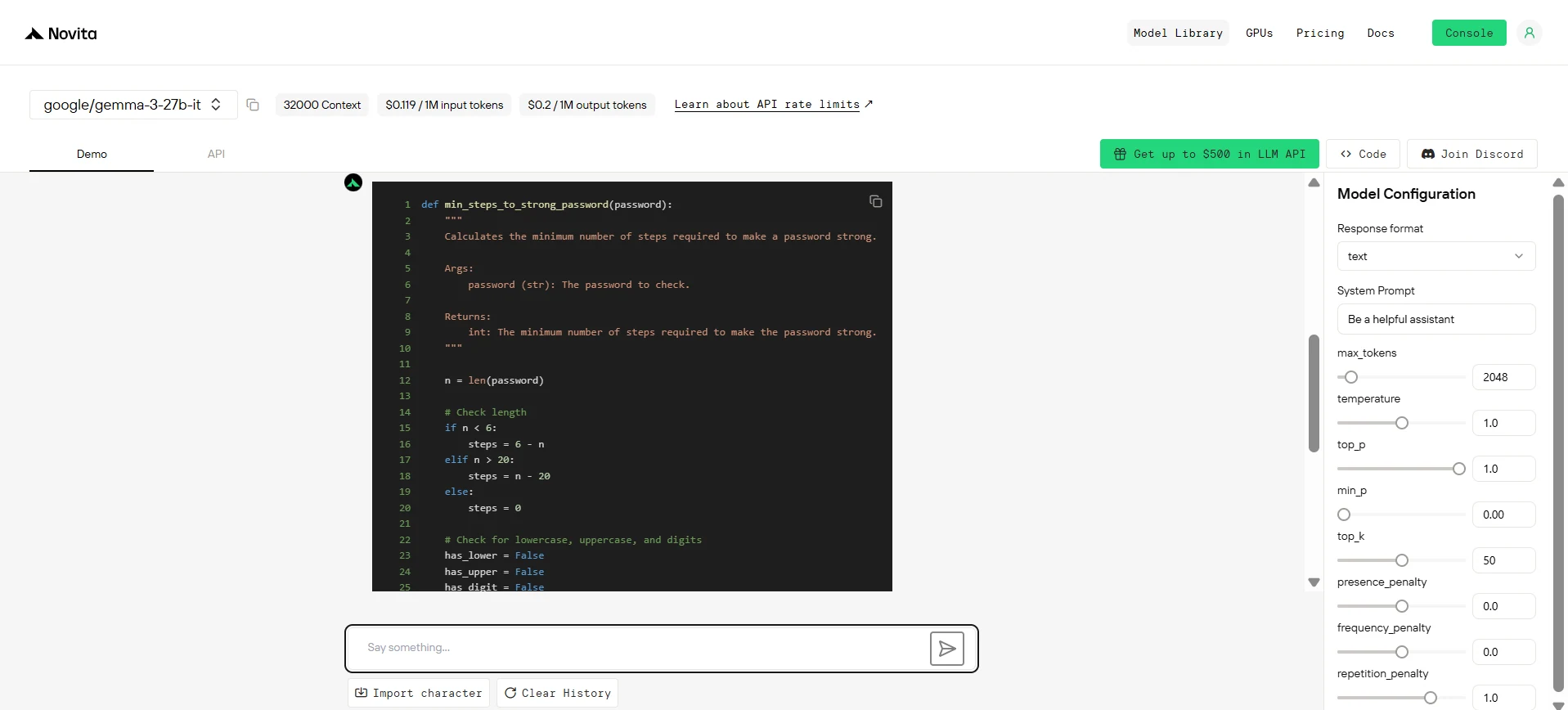
Gemma 3 27B
How to Access QwQ 32B and Gemma 3 27B via Novita API?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
[Try QwQ 32B and Gemma 3 27B Demo Now!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
For flexible, cost-efficient AI with scalable hardware needs, QwQ 32B is the ideal choice. For high-precision, resource-intensive tasks, Gemma 3 27B is the better option. Both models are available via Novita AI’s APIs, offering unmatched accessibility and performance. Start your free trial today and experience the capabilities of these powerful models.
Frequently Asked Questions
Which model is better for startups?
QwQ 32B is better due to its flexibility, lower hardware requirements, and cost-effectiveness.
Can I use these models on edge devices?
QwQ 32B supports lower precision modes (8-bit, 4-bit), making it suitable for edge and real-time applications. Gemma 3 4B supported Apple silicon via mlx-vlm
Is there a free trial available for QwQ 32B and Gemma 3 27B?
Yes, you can start a free trial on the [Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) website to explore both QwQ 32B and Gemma 3 27B.
[Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



