

النقاط البارزة
QwQ 32B: يتفوق في التعامل مع المهام المعقدة والحالات الطرفية والسيناريوهات التي تتطلب مرونة. يدعم دقة 16-bit و8-bit و4-bit، مما يجعله فعالًا للتطبيقات في الوقت الفعلي والحساسة للتكلفة.
Gemma 3 27B: محسّن للمهام عالية الدقة بدعم FP16، لكنه يواجه صعوبات مع الحالات الطرفية وكلمات المرور الطويلة. يؤدي أفضل ما لديه في البيئات عالية الموارد.
Novita AI لا توفر فقط خدمات API مستقرة ولكنها تقدم أيضًا أسعارًا فعالة للغاية من حيث التكلفة. على سبيل المثال، تكلفة Gemma 3 27B هي 0.119 دولار فقط لكل 1 مليون رمز إدخال و 0.2 دولار لكل 1 مليون رمز إخراج، بينما تكلفة QwQ 32B هي 0.18 دولار لكل 1 مليون رمز إدخال و 0.2 دولار لكل 1 مليون رمز إخراج.
QwQ 32B مقابل Gemma 3 27B: مقدمة أساسية
مقدمة عن QwQ 32B

مقدمة عن Gemma 3 27B

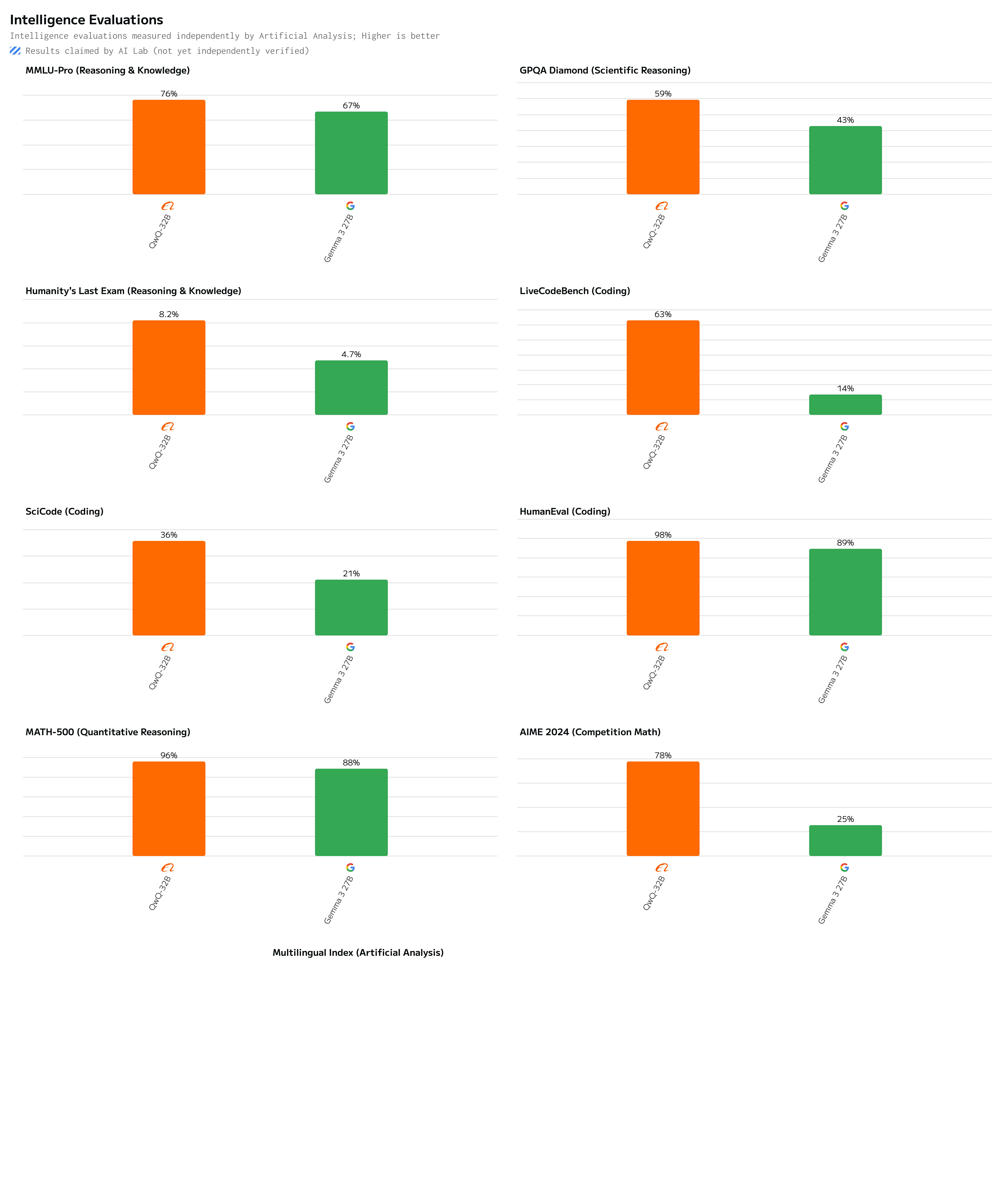
QwQ 32B مقابل Gemma 3 27B: المعايير
يتفوق QwQ 32B على Gemma 3 27B في جميع الاختبارات. يشير هذا إلى أن QwQ 32B يُظهر قدرات أقوى وتنوعًا أفضل عبر مهام متعددة المجالات، بينما قد يتفوق Gemma 3 27B في بعض المجالات المحددة لكنه يتأخر بشكل عام.
إذا كنت ترغب في اختباره بنفسك، يمكنك بدء تجربة مجانية على موقع Novita AI.

جرب نموذج QwQ 32B و Gemma 3 27B الآن!
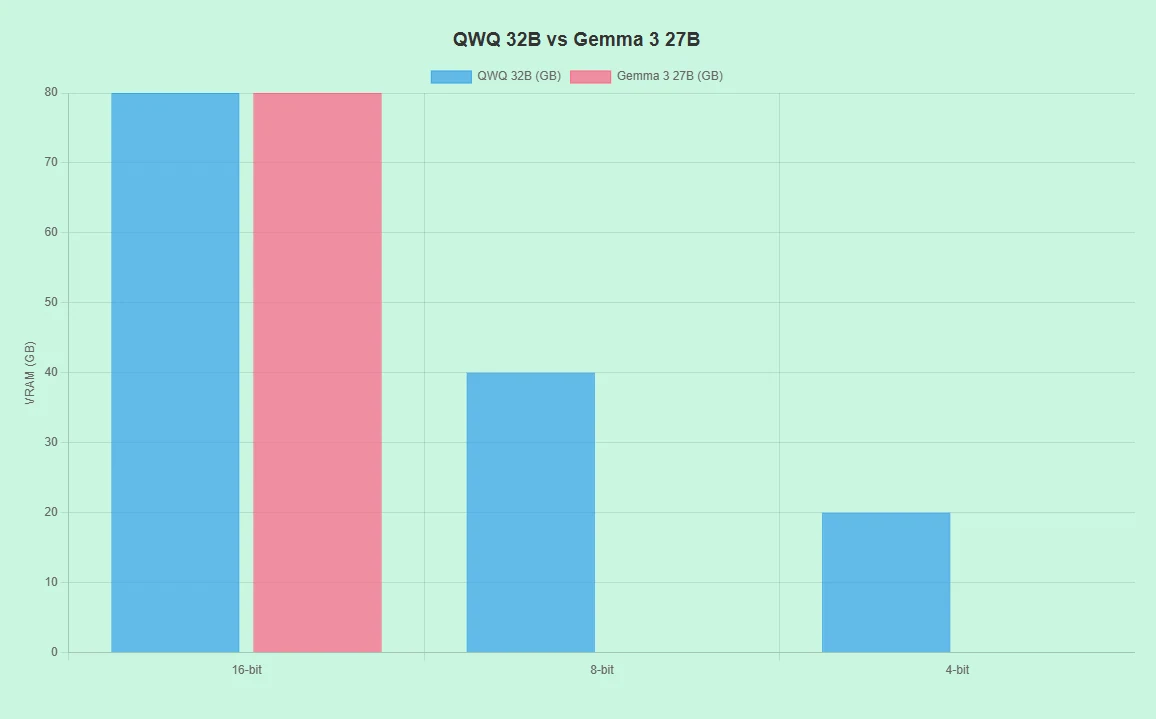
QwQ 32B مقابل Gemma 3 27B: متطلبات الأجهزة
QwQ 32B مقابل Gemma 3 27B: التطبيقات
QwQ 32B
نشر مرن:
- يدعم أجهزة متنوعة (مثل RTX 4090، A100) بدقة 16-bit و8-bit و4-bit.
- مثالي لخدمات الذكاء الاصطناعي القابلة للتوسع والتكيف.
حلول فعالة من حيث التكلفة:
- الطلب المنخفض على VRAM في وضعي 8-bit/4-bit يقلل التكاليف.
- مناسب للتطبيقات ذات الميزانية المحدودة مثل برامج الدردشة الآلية أو أنظمة التوصية.
تطبيقات الوقت الفعلي والحافة:
- يعمل مع أجهزة المحمول/IoT ومهام الذكاء الاصطناعي في الوقت الفعلي.
- مثال: الذكاء الاصطناعي على الجهاز أو أنظمة دعم العملاء المباشرة.
ضبط دقيق مخصص:
- ضبط دقيق فعال على وحدات معالجة رسوميات متوسطة لمهام خاصة بالمجال (مثل النماذج القانونية والطبية).
Gemma 3 27B
الذكاء الاصطناعي على مستوى المؤسسات:
- مصمم للأجهزة عالية الأداء (مثل مجموعات GPU).
- مثال: الذكاء الاصطناعي التوليدي واسع النطاق مثل التلخيص أو الترجمة.
خدمات الذكاء الاصطناعي السحابية:
- أسعار تنافسية لخدمات NLP المركزية.
- مثال: APIs مستضافة على السحابة للشركات.
التدريب كثيف الموارد:
- الأفضل لتدريب النماذج المعقدة على أجهزة قوية.
QwQ 32B مقابل Gemma 3 27B: المهام
Prompt:
تعتبر كلمة المرور قوية إذا توفرت جميع الشروط التالية:
- تحتوي على 6 أحرف على الأقل و 20 حرفًا على الأكثر.
- تحتوي على حرف صغير واحد على الأقل، وحرف كبير واحد على الأقل، ورقم واحد على الأقل.
- لا تحتوي على ثلاثة أحرف متكررة متتالية (على سبيل المثال، "Baaabb0" ضعيفة، لكن "Baaba0" قوية).
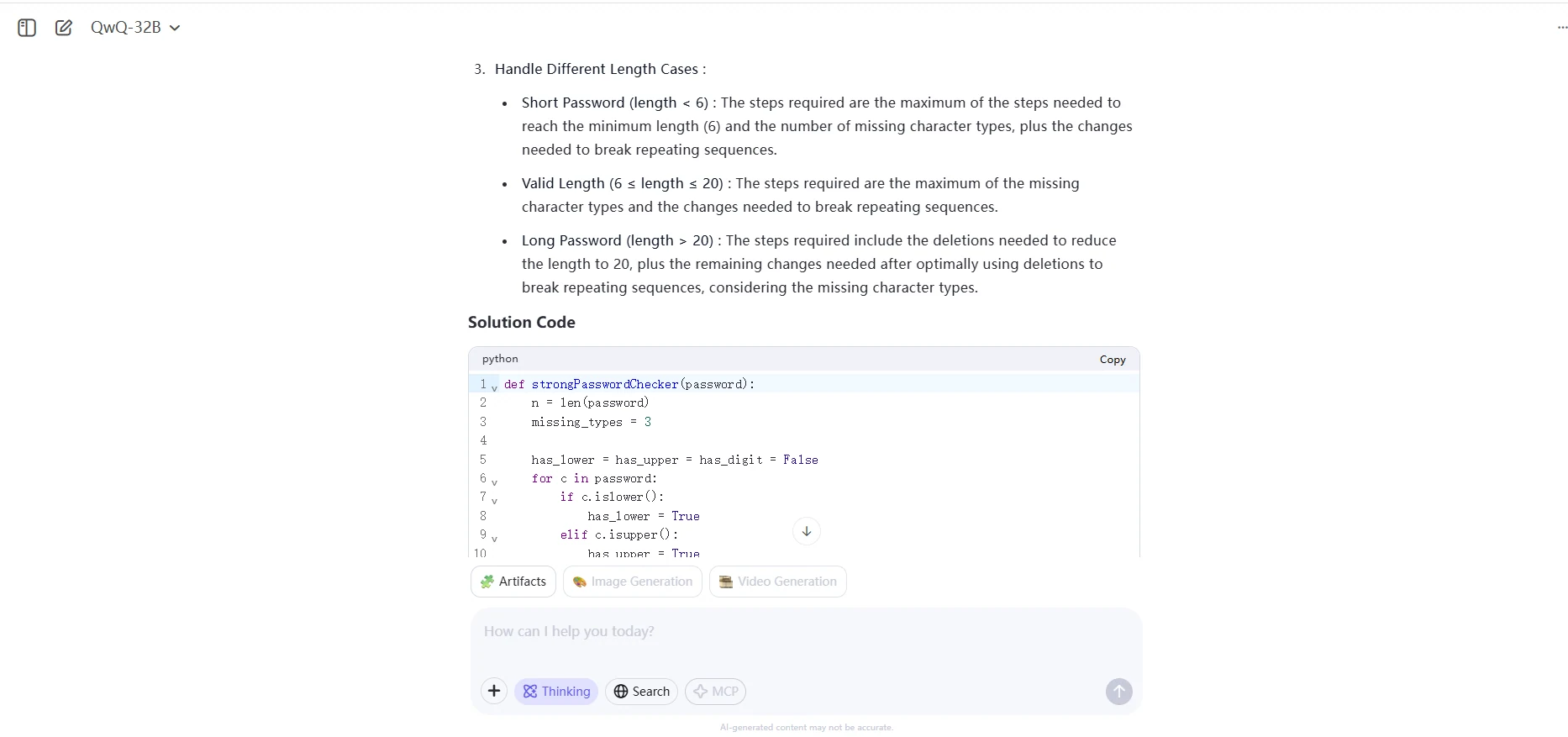
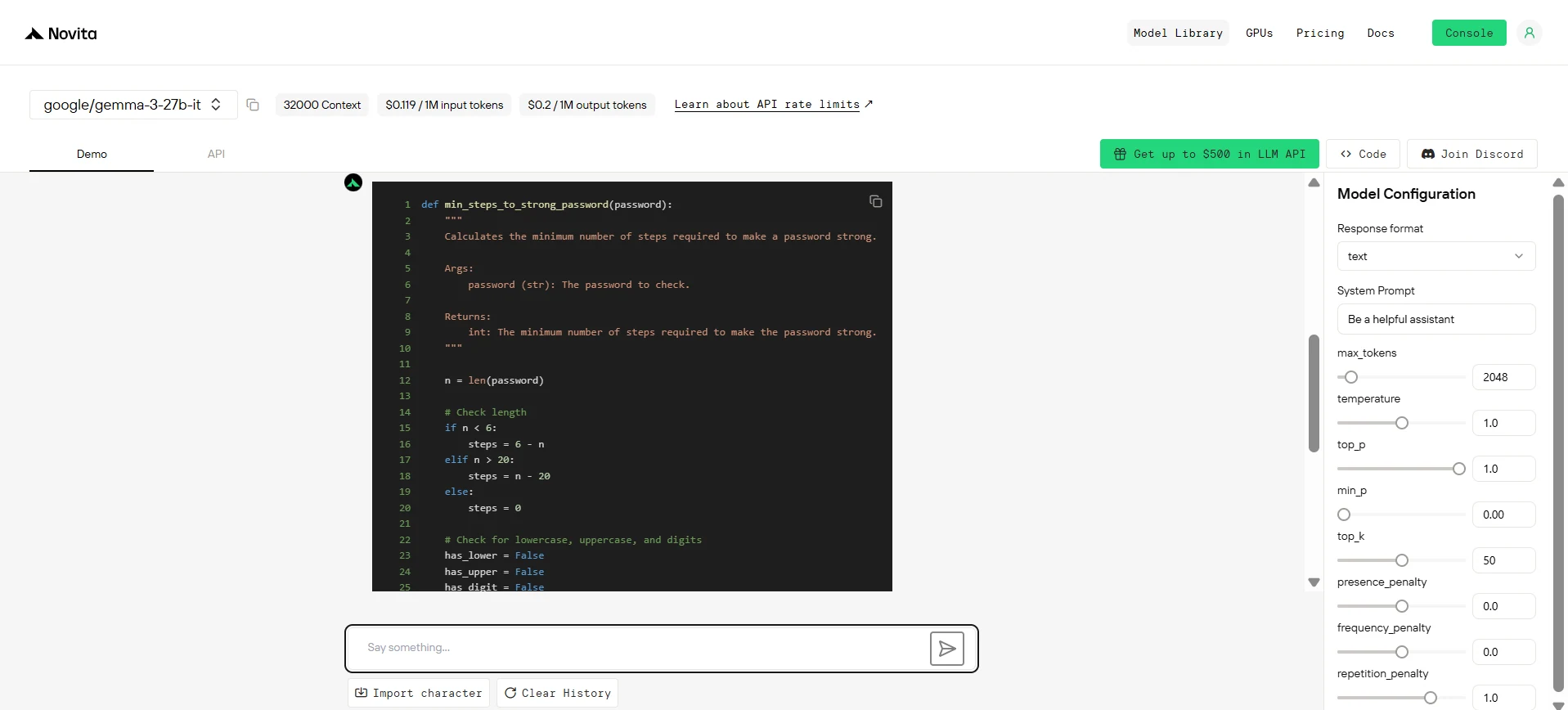
بإعطاء سلسلة كلمة مرور، أعد الحد الأدنى من الخطوات المطلوبة لجعل كلمة المرور قوية. إذا كانت كلمة المرور قوية بالفعل، أعد 0.
في خطوة واحدة، يمكنك:
- إدراج حرف واحد في كلمة المرور،
- حذف حرف واحد من كلمة المرور، أو
- استبدال حرف واحد في كلمة المرور بحرف آخر.
مثال 1:
Input: password = "a"
Output: 5
مثال 2:
Input: password = "aA1"
Output: 3
مثال 3:
Input: password = "1337C0d3"
Output: 0
القيود:
1 <= password.length <= 50
تتكون كلمة المرور من أحرف وأرقام ونقطة '.' أو علامة تعجب '!'.
QwQ 32B
Gemma 3 27B
كيفية الوصول إلى QwQ 32B و Gemma 3 27B عبر Novita API؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة وحدد النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف إمكانيات النموذج المحدد.
جرب نموذج QwQ 32B و Gemma 3 27B الآن!
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنقدم لك مفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.

بعد التثبيت، قم باستيراد المكتبات اللازمة في بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام chat completions API لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
للحصول على ذكاء اصطناعي مرن وفعال من حيث التكلفة مع احتياجات أجهزة قابلة للتوسع، فإن QwQ 32B هو الخيار المثالي. للمهام عالية الدقة كثيفة الموارد، فإن Gemma 3 27B هو الخيار الأفضل. كلا النموذجين متاحان عبر واجهات Novita AI APIs، مما يوفر إمكانية وصول وأداء لا مثيل لهما. ابدأ تجربتك المجانية اليوم واستمتع بقدرات هذه النماذج القوية.
الأسئلة المتكررة
أي نموذج أفضل للشركات الناشئة؟
QwQ 32B أفضل بسبب مرونته ومتطلبات الأجهزة المنخفضة وفعاليته من حيث التكلفة.
هل يمكنني استخدام هذه النماذج على الأجهزة الطرفية؟
QwQ 32B يدعم أوضاع الدقة المنخفضة (8-bit، 4-bit)، مما يجعله مناسبًا للتطبيقات الطرفية وفي الوقت الفعلي. Gemma 3 4B يدعم Apple silicon عبر mlx-vlm.
هل توجد نسخة تجريبية مجانية لـ QwQ 32B و Gemma 3 27B؟
نعم، يمكنك بدء تجربة مجانية على موقع Novita AI لاستكشاف كل من QwQ 32B و Gemma 3 27B.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط، مع توفير GPU سحابي ميسور التكلفة وموثوق للبناء والتوسع.



