

Wichtige Highlights
QwQ 32B: Hervorragend bei komplexen Aufgaben, Randfällen und Szenarien, die Flexibilität erfordern. Unterstützt 16‑Bit‑, 8‑Bit‑ und 4‑Bit‑Präzision und ist somit effizient für Echtzeit‑ und kostenbewusste Anwendungen.
Gemma 3 27B: Optimiert für hochpräzise Aufgaben mit FP16‑Unterstützung, hat aber Schwierigkeiten mit Randfällen und langen Passwörtern. Funktioniert am besten in ressourcenstarken Umgebungen.
Novita AI bietet nicht nur stabile API‑Dienste, sondern auch extrem kostengünstige Preise. Gemma 3 27B kostet beispielsweise nur 0,119 $ pro 1 Million Input‑Tokens und 0,2 $ pro 1 Million Output‑Tokens, während QwQ 32B 0,18 $ pro 1 Million Input‑Tokens und 0,2 $ pro 1 Million Output‑Tokens kostet.
QwQ 32B vs Gemma 3 27B: Grundlegende Einführung
QwQ 32B Einführung

Gemma 3 27B Einführung

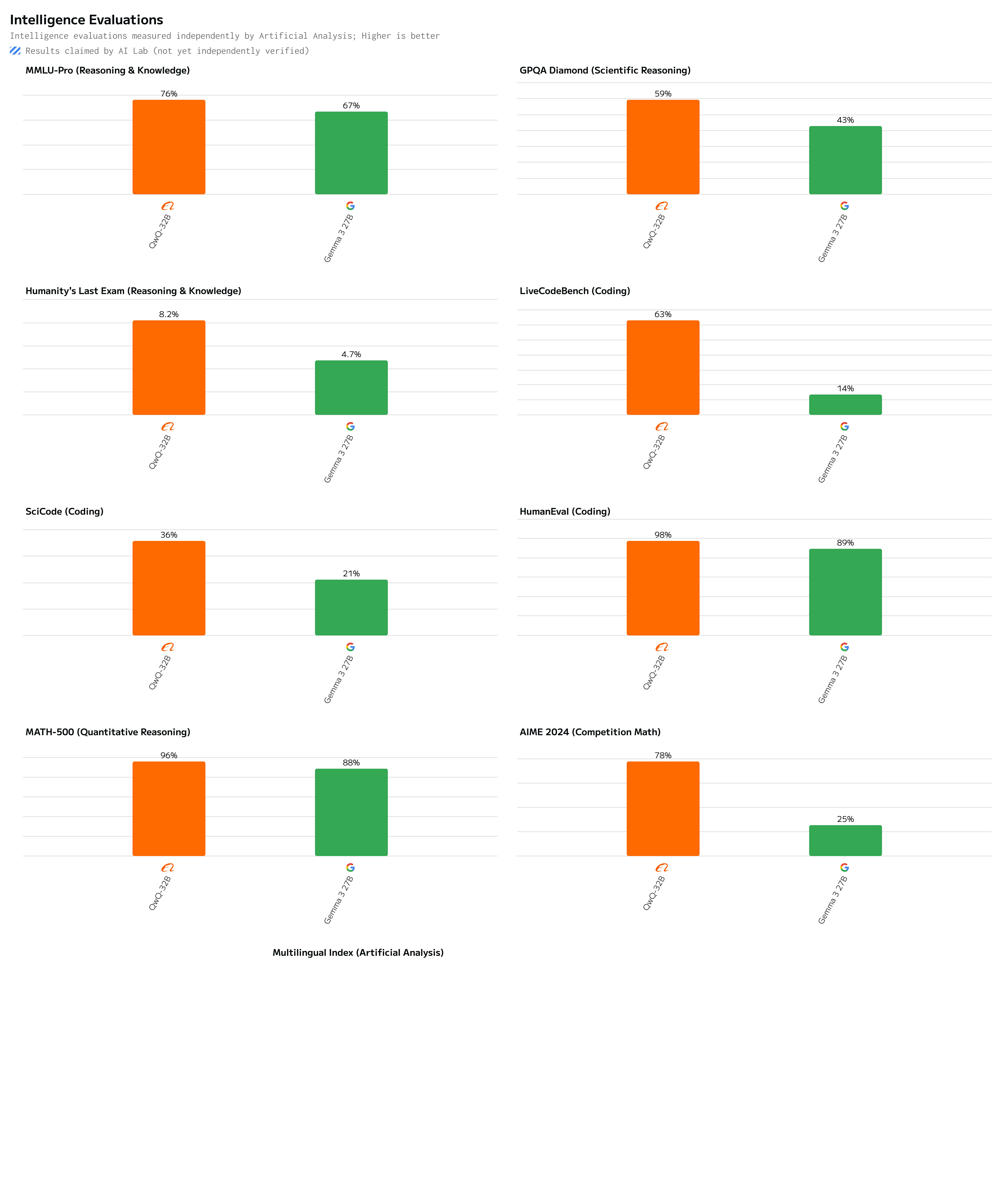
QwQ 32B vs Gemma 3 27B: Benchmark
QwQ 32B übertrifft Gemma 3 27B in allen Tests. Das deutet darauf hin, dass QwQ 32B stärkere Fähigkeiten und eine bessere Vielseitigkeit bei Aufgaben aus verschiedenen Bereichen zeigt, während Gemma 3 27B in bestimmten Bereichen glänzen kann, insgesamt aber zurückliegt.
Wenn du es selbst ausprobieren möchtest, kannst du auf der Novita‑AI‑Website eine kostenlose Testversion starten.

Teste jetzt die Demo von QwQ 32B und Gemma 3 27B!
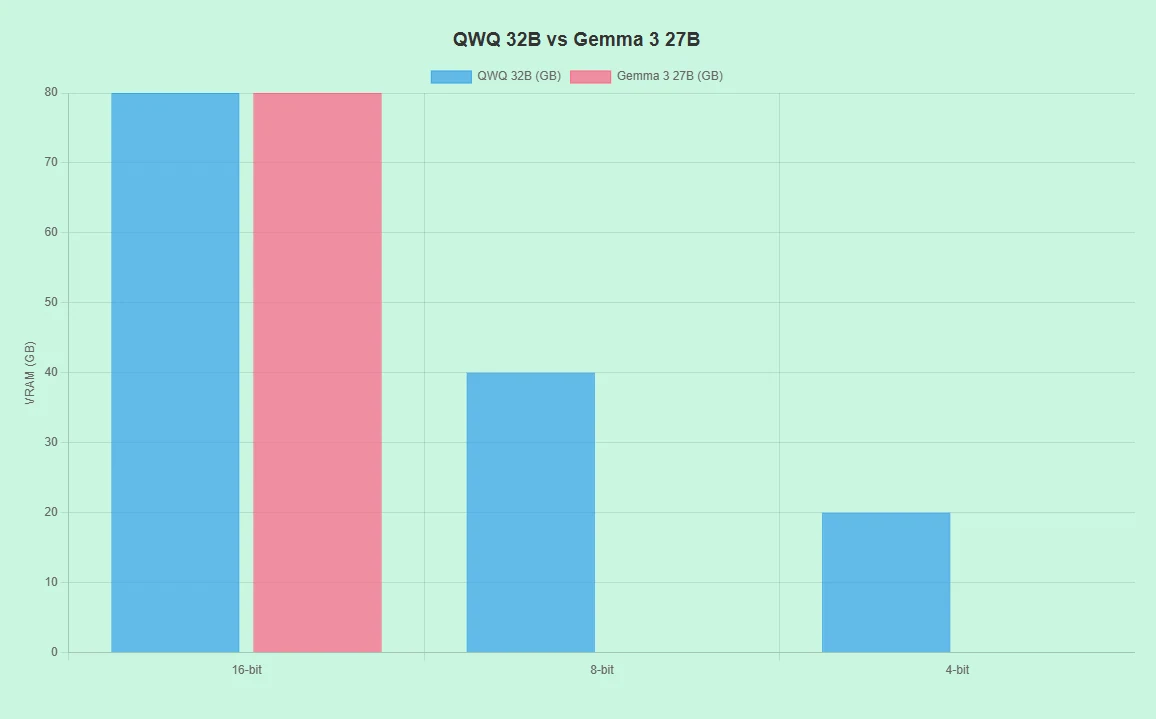
QwQ 32B vs Gemma 3 27B: Hardware‑Anforderungen
QwQ 32B vs Gemma 3 27B: Anwendungen
QwQ 32B
Flexible Bereitstellung:
- Unterstützt verschiedene Hardware (z. B. RTX 4090, A100) mit 16‑Bit‑, 8‑Bit‑ und 4‑Bit‑Präzision.
- Ideal für skalierbare und anpassungsfähige KI‑Dienste.
Kosteneffiziente Lösungen:
- Geringer VRAM‑Bedarf in 8‑Bit‑/4‑Bit‑Modi senkt die Kosten.
- Geeignet für preisbewusste Anwendungen wie Chatbots oder Empfehlungssysteme.
Echtzeit‑ und Edge‑Anwendungen:
- Funktioniert für mobile/IoT‑Geräte und Echtzeit‑KI‑Aufgaben.
- Beispiel: On‑Device‑KI oder Live‑Kundensupportsysteme.
Individuelles Fine‑Tuning:
- Effizientes Fine‑Tuning auf mittleren GPUs für domänenspezifische Aufgaben (z. B. Rechts‑ oder Medizinmodelle).
Gemma 3 27B
Enterprise‑Scale‑KI:
- Für leistungsstarke Hardware ausgelegt (z. B. GPU‑Cluster).
- Beispiel: Groß angelegte generative KI wie Zusammenfassung oder Übersetzung.
Cloud‑basierte KI‑Dienste:
- Wettbewerbsfähige Preise für zentralisierte NLP‑Dienste.
- Beispiel: Cloud‑gehostete APIs für Unternehmen.
Ressourcenintensives Training:
- Am besten für das Training komplexer Modelle auf leistungsstarker Hardware geeignet.
QwQ 32B vs Gemma 3 27B: Aufgaben
Prompt:
Ein Passwort gilt als stark, wenn alle folgenden Bedingungen erfüllt sind:
- Es hat mindestens 6 Zeichen und höchstens 20 Zeichen.
- Es enthält mindestens einen Kleinbuchstaben, mindestens einen Großbuchstaben und mindestens eine Ziffer.
- Es enthält nicht drei sich wiederholende Zeichen in Folge (d. h. "Baaabb0" ist schwach, aber "Baaba0" ist stark).
Bei einem gegebenen String password gib die Mindestanzahl von Schritten zurück, die erforderlich sind, um das Passwort stark zu machen. Wenn das Passwort bereits stark ist, gib 0 zurück.
In einem Schritt kannst du:
- Ein Zeichen in das Passwort einfügen,
- Ein Zeichen aus dem Passwort löschen oder
- Ein Zeichen des Passworts durch ein anderes Zeichen ersetzen.
Beispiel 1:
Input: password = "a"
Output: 5
Beispiel 2:
Input: password = "aA1"
Output: 3
Beispiel 3:
Input: password = "1337C0d3"
Output: 0
Einschränkungen:
1 <= password.length <= 50
password besteht aus Buchstaben, Ziffern, Punkt '.' oder Ausrufezeichen '!'.
QwQ 32B
Gemma 3 27B
Wie greife ich über die Novita‑API auf QwQ 32B und Gemma 3 27B zu?
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melde dich in deinem Konto an und klicke auf die Schaltfläche Modellbibliothek.

Schritt 2: Wähle dein Modell
Durchstöbere die verfügbaren Optionen und wähle das Modell aus, das deinen Anforderungen entspricht.
Schritt 3: Starte deine kostenlose Testversion
Beginne deine kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Teste jetzt die Demo von QwQ 32B und Gemma 3 27B!
Schritt 4: Erhalte deinen API‑Schlüssel
Zur Authentifizierung mit der API stellen wir dir einen neuen API‑Schlüssel zur Verfügung. Gehe auf die Seite „Einstellungen“ und kopiere den API‑Schlüssel wie im Bild gezeigt.

Schritt 5: Installiere die API
Installiere die API mit dem für deine Programmiersprache spezifischen Paketmanager.

Importiere nach der Installation die notwendigen Bibliotheken in deine Entwicklungsumgebung. Initialisiere die API mit deinem API‑Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat‑Completions‑API für Python‑Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<DEIN Novita AI API-Schlüssel>",
)
model = "google/gemma-3-27b-it"
stream = True # oder False
max_tokens = 2048
system_content = """Sei ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Für flexible, kosteneffiziente KI mit skalierbarem Hardware‑Bedarf ist QwQ 32B die ideale Wahl. Für hochpräzise, ressourcenintensive Aufgaben ist Gemma 3 27B die bessere Option. Beide Modelle sind über die Novita‑AI‑APIs verfügbar und bieten beispiellose Zugänglichkeit und Leistung. Starte noch heute deine kostenlose Testversion und erlebe die Fähigkeiten dieser leistungsstarken Modelle.
Häufig gestellte Fragen
Welches Modell ist besser für Startups?
QwQ 32B ist besser geeignet aufgrund seiner Flexibilität, geringeren Hardware‑Anforderungen und Kosteneffizienz.
Kann ich diese Modelle auf Edge‑Geräten verwenden?
QwQ 32B unterstützt niedrigere Präzisionsmodi (8‑Bit, 4‑Bit) und eignet sich daher für Edge‑ und Echtzeitanwendungen. Gemma 3 4B unterstützt Apple Silicon über mlx-vlm.
Gibt es eine kostenlose Testversion für QwQ 32B und Gemma 3 27B?
Ja, du kannst auf der Novita AI-Website eine kostenlose Testversion starten, um sowohl QwQ 32B als auch Gemma 3 27B zu testen.
Novita AI ist eine KI‑Cloud‑Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI‑Modelle mit unserer einfachen API bereitzustellen und gleichzeitig eine kostengünstige und zuverlässige GPU‑Cloud für den Aufbau und die Skalierung bereitstellt.



