

Points clés
QwQ 32B : Excellent pour gérer les tâches complexes, les cas limites et les scénarios nécessitant de la flexibilité. Prend en charge les précisions 16 bits, 8 bits et 4 bits, ce qui le rend efficace pour les applications en temps réel et sensibles aux coûts.
Gemma 3 27B : Optimisé pour les tâches de haute précision avec le support FP16, mais rencontre des difficultés avec les cas limites et les mots de passe longs. Performe au mieux dans les environnements à fortes ressources.
Novita AI ne fournit pas seulement des services API stables, mais offre également des prix extrêmement compétitifs. Par exemple, Gemma 3 27B ne coûte que 0,119 $ par million de jetons en entrée et 0,2 $ par million de jetons en sortie, tandis que QwQ 32B coûte 0,18 $ par million de jetons en entrée et 0,2 $ par million de jetons en sortie.
QwQ 32B vs Gemma 3 27B : Présentation de base
Présentation de QwQ 32B

Présentation de Gemma 3 27B

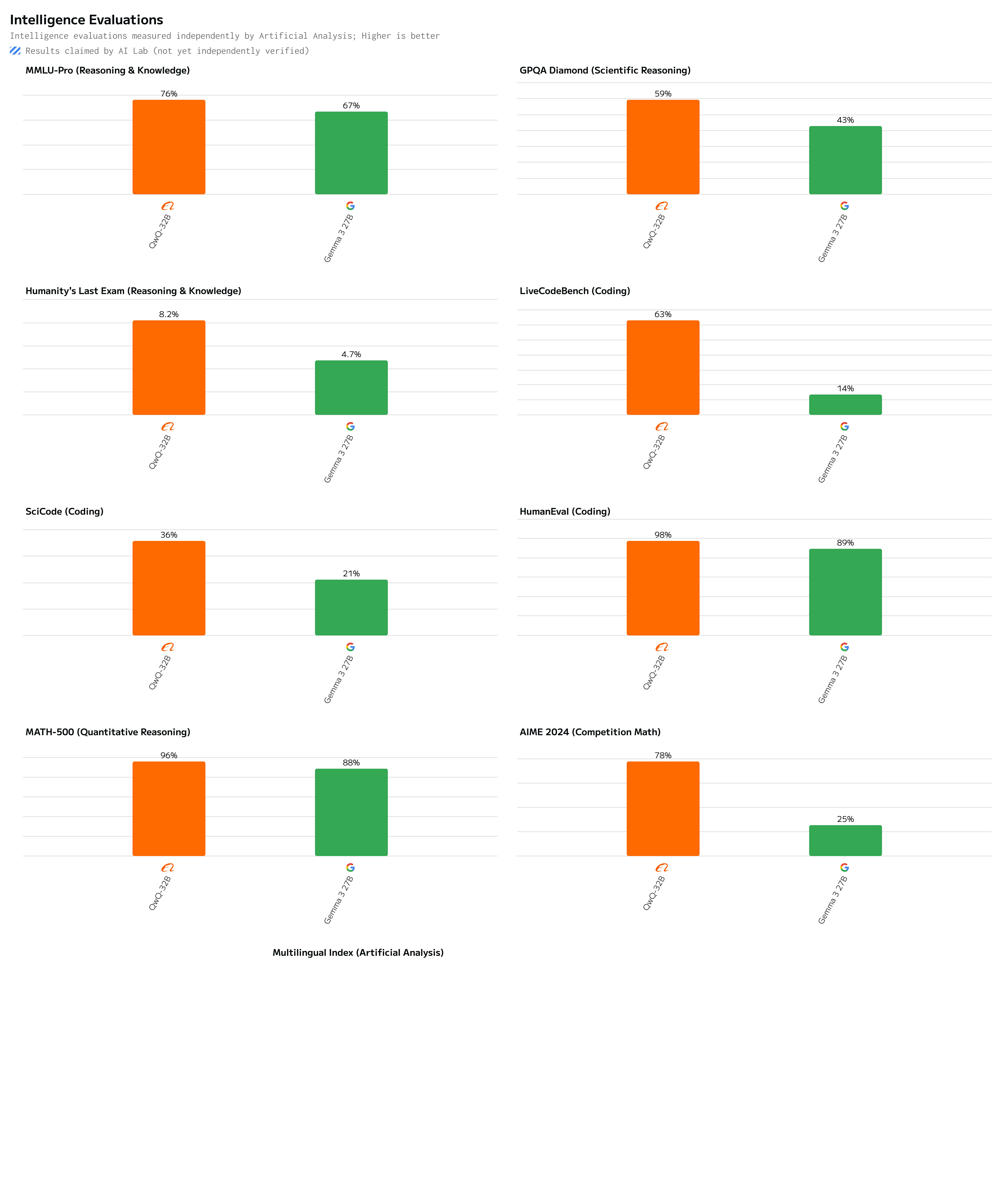
QwQ 32B vs Gemma 3 27B : Benchmarks
QwQ 32B surpasse Gemma 3 27B dans tous les tests. Cela indique que QwQ 32B démontre des capacités plus solides et une meilleure polyvalence dans des tâches multi-domaines, tandis que Gemma 3 27B peut exceller dans certains domaines spécifiques mais est en retard globalement.
Si vous souhaitez le tester vous-même, vous pouvez lancer un essai gratuit sur le site Novita AI.

Essayez la démo de QwQ 32B et Gemma 3 27B dès maintenant !
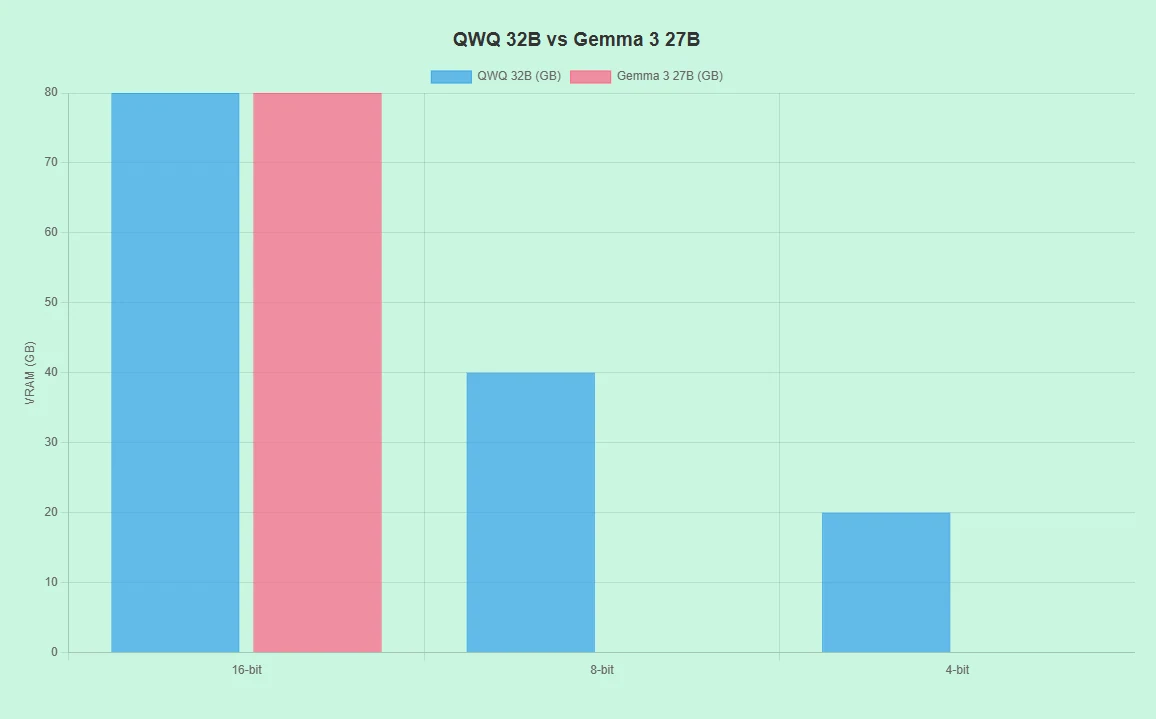
QwQ 32B vs Gemma 3 27B : Configuration matérielle requise
QwQ 32B vs Gemma 3 27B : Applications
QwQ 32B
Déploiement flexible :
- Prend en charge différents matériels (ex. RTX 4090, A100) avec des précisions 16 bits, 8 bits et 4 bits.
- Idéal pour des services IA évolutifs et adaptables.
Solutions économiques :
- Faible demande de VRAM en modes 8 bits/4 bits, réduisant les coûts.
- Adapté aux applications budget-friendly comme les chatbots ou les systèmes de recommandation.
Applications temps réel et périphériques :
- Fonctionne pour les appareils mobiles/IoT et les tâches IA en temps réel.
- Exemple : IA embarquée ou systèmes de support client en direct.
Ajustement fin personnalisé :
- Ajustement fin efficace sur des GPU de milieu de gamme pour des tâches spécifiques (ex. modèles juridiques, médicaux).
Gemma 3 27B
IA à l’échelle de l’entreprise :
- Conçu pour du matériel haute performance (ex. clusters de GPU).
- Exemple : IA générative à grande échelle comme la synthèse ou la traduction.
Services IA basés sur le cloud :
- Tarification compétitive pour les services NLP centralisés.
- Exemple : API hébergées dans le cloud pour les entreprises.
Entraînement intensif en ressources :
- Idéal pour l’entraînement de modèles complexes sur du matériel puissant.
QwQ 32B vs Gemma 3 27B : Tâches
Prompt:
Un mot de passe est considéré comme fort si toutes les conditions suivantes sont remplies :
- Il a au moins 6 caractères et au plus 20 caractères.
- Il contient au moins une lettre minuscule, au moins une lettre majuscule et au moins un chiffre.
- Il ne contient pas trois caractères répétés à la suite (par exemple, "Baaabb0" est faible, mais "Baaba0" est fort).
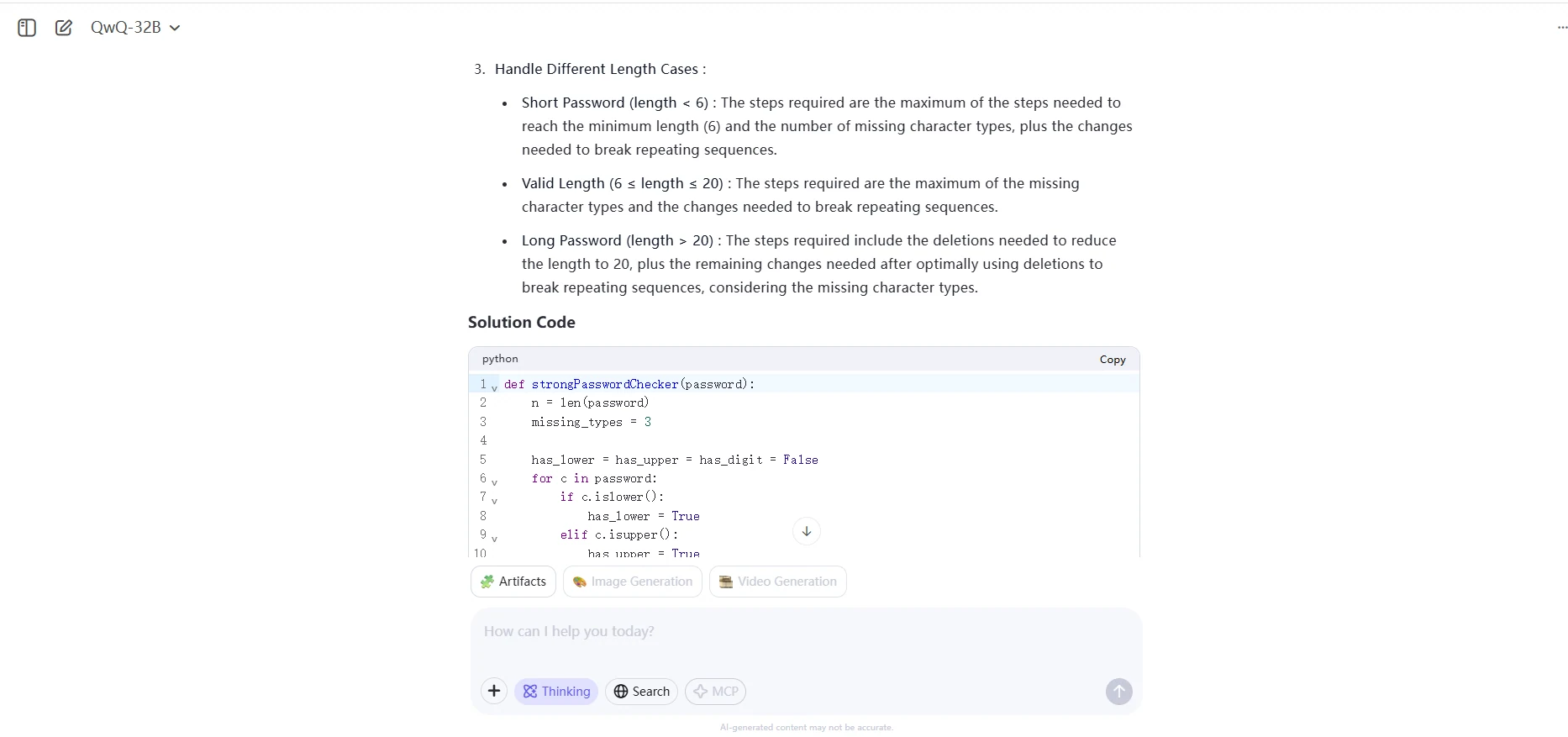
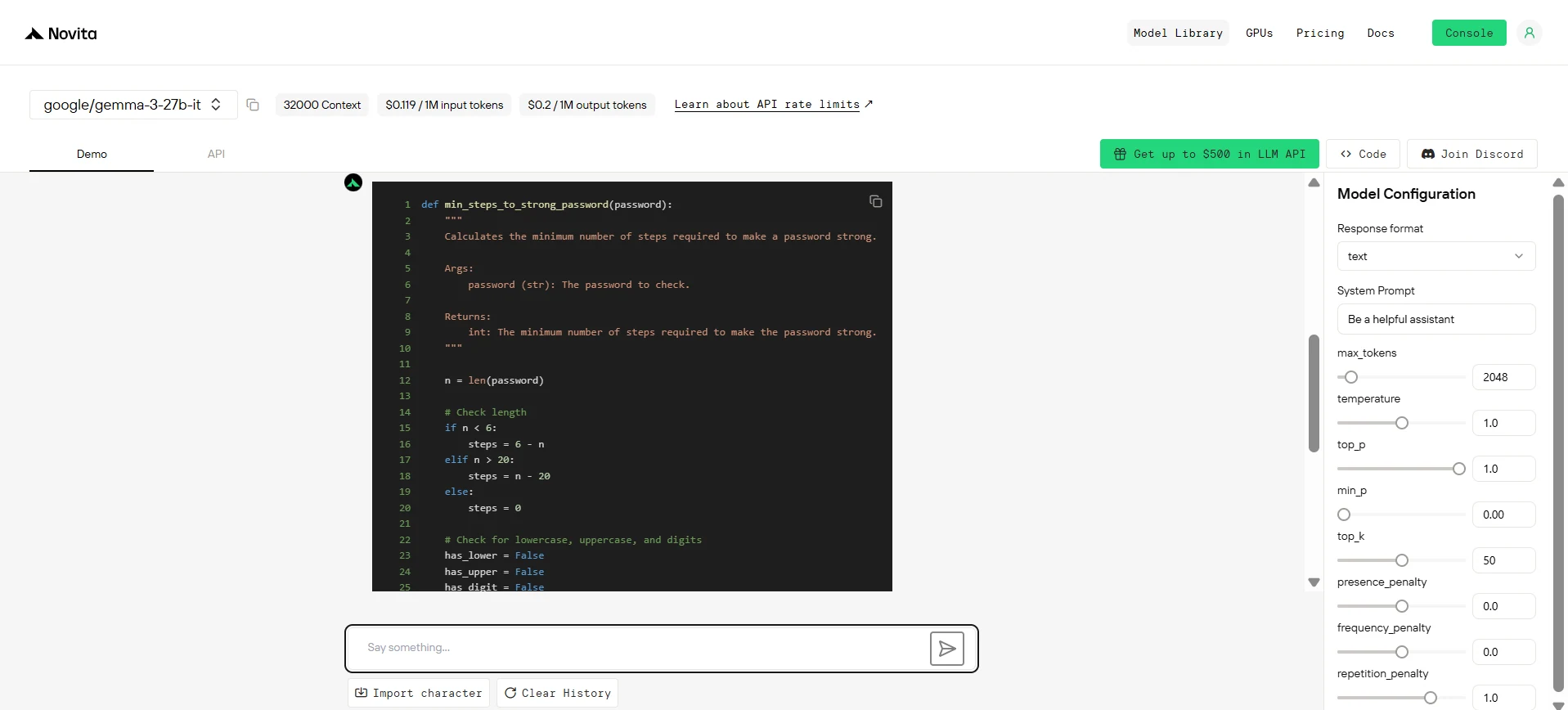
Étant donné une chaîne de caractères password, retournez le nombre minimum d'étapes nécessaires pour rendre le mot de passe fort. Si le mot de passe est déjà fort, retournez 0.
En une étape, vous pouvez :
- Insérer un caractère dans le mot de passe,
- Supprimer un caractère du mot de passe, ou
- Remplacer un caractère du mot de passe par un autre caractère.
Exemple 1 :
Input: password = "a"
Output: 5
Exemple 2 :
Input: password = "aA1"
Output: 3
Exemple 3 :
Input: password = "1337C0d3"
Output: 0
Contraintes :
1 <= password.length <= 50
password se compose de lettres, de chiffres, du point '.' ou du point d'exclamation '!'.
QwQ 32B
Gemma 3 27B
Comment accéder à QwQ 32B et Gemma 3 27B via l’API Novita ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Lancez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez la démo de QwQ 32B et Gemma 3 27B dès maintenant !
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page Settings (Paramètres) et copiez la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "google/gemma-3-27b-it"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant serviable"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Pour une IA flexible et économique avec des besoins matériels évolutifs, QwQ 32B est le choix idéal. Pour des tâches de haute précision et gourmandes en ressources, Gemma 3 27B est la meilleure option. Les deux modèles sont disponibles via les API de Novita AI, offrant une accessibilité et des performances inégalées. Lancez votre essai gratuit dès aujourd’hui et découvrez les capacités de ces modèles puissants.
Questions fréquentes
Quel modèle est le meilleur pour les startups ?
QwQ 32B est meilleur grâce à sa flexibilité, ses besoins matériels réduits et son bon rapport coût-efficacité.
Puis-je utiliser ces modèles sur des appareils périphériques (edge) ?
QwQ 32B prend en charge les modes de précision inférieure (8 bits, 4 bits), ce qui le rend adapté aux applications périphériques et en temps réel. Gemma 3 4B prend en charge Apple Silicon via mlx-vlm.
Existe-t-il un essai gratuit pour QwQ 32B et Gemma 3 27B ?
Oui, vous pouvez lancer un essai gratuit sur le site web de Novita AI pour explorer les deux modèles QwQ 32B et Gemma 3 27B.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant un GPU cloud fiable et abordable pour construire et passer à l’échelle.



