

Destaques Principais
QwQ 32B: Excelente no tratamento de tarefas complexas, casos extremos e cenários que exigem flexibilidade. Suporta precisão 16-bit, 8-bit e 4-bit, tornando-se eficiente para aplicações em tempo real e sensíveis a custo.
Gemma 3 27B: Otimizada para tarefas de alta precisão com suporte a FP16, mas enfrenta dificuldades com casos extremos e senhas longas. Tem melhor desempenho em ambientes com muitos recursos.
A [Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) não só fornece serviços de API estáveis, mas também oferece preços extremamente competitivos. Por exemplo, o Gemma 3 27B custa apenas $0,119 por 1M de tokens de entrada e $0,2 por 1M de tokens de saída, enquanto o QwQ 32B custa $0,18 por 1M de tokens de entrada e $0,2 por 1M de tokens de saída.
QwQ 32B vs Gemma 3 27B: Introdução Básica
Introdução ao QwQ 32B

Introdução ao Gemma 3 27B

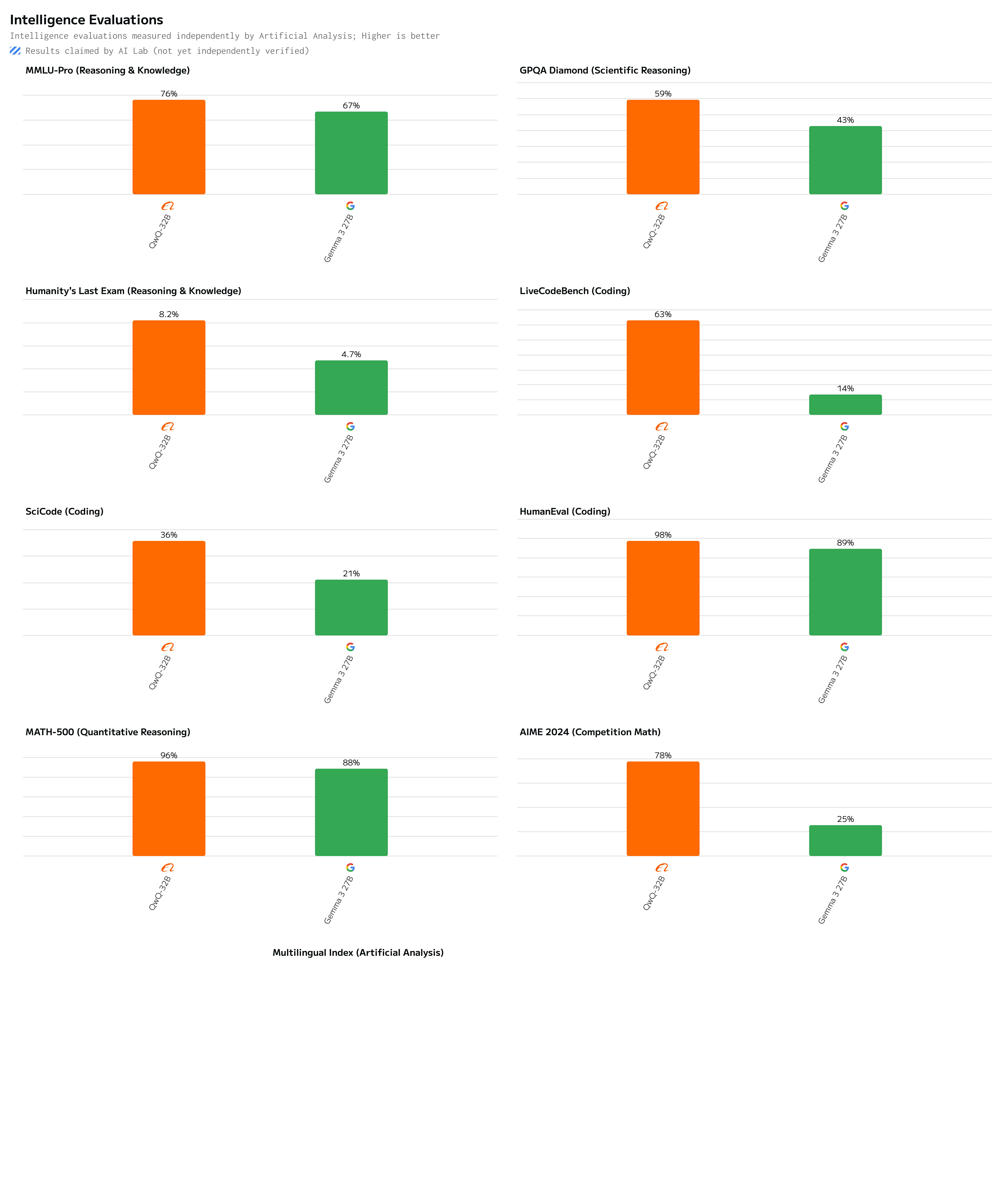
QwQ 32B vs Gemma 3 27B: Benchmark
O QwQ 32B supera o Gemma 3 27B em todos os testes. Isso indica que o QwQ 32B demonstra capacidades mais fortes e melhor versatilidade em tarefas de múltiplos domínios, enquanto o Gemma 3 27B pode se destacar em certas áreas específicas, mas fica atrás no geral.
Se você quiser testar por conta própria, pode iniciar uma avaliação gratuita no site da Novita AI.

[Experimente agora o Demo do QwQ 32B e Gemma 3 27B!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
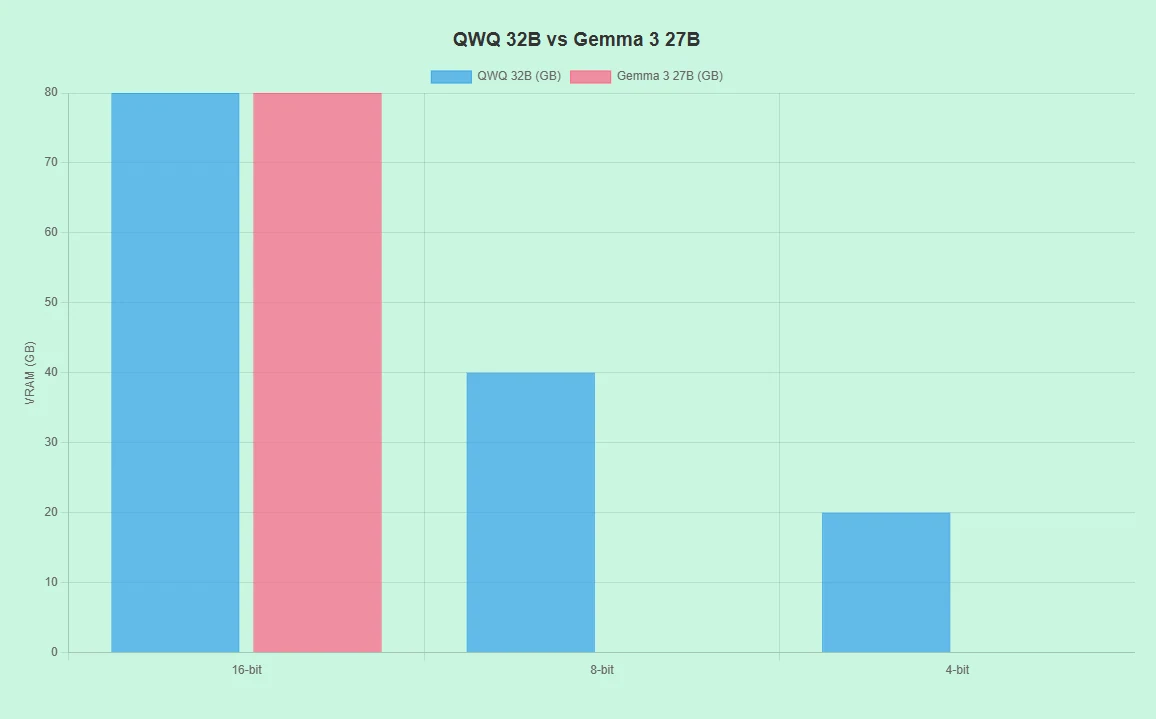
QwQ 32B vs Gemma 3 27B: Requisitos de Hardware
QwQ 32B vs Gemma 3 27B: Aplicações
QwQ 32B
Implantação Flexível:
- Suporta hardware variado (ex.: RTX 4090, A100) com precisão 16-bit, 8-bit e 4-bit.
- Ideal para serviços de IA escaláveis e adaptáveis.
Soluções de Custo-Eficiência:
- Baixa demanda de VRAM em modos 8-bit/4-bit reduz custos.
- Adequado para aplicações com orçamento limitado, como chatbots ou sistemas de recomendação.
Aplicações em Tempo Real e Edge:
- Funciona para dispositivos móveis/IoT e tarefas de IA em tempo real.
- Exemplo: IA no dispositivo ou sistemas de suporte ao cliente ao vivo.
Ajuste Fino Personalizado:
- Ajuste fino eficiente em GPUs de nível médio para tarefas específicas de domínio (ex.: modelos legais, médicos).
Gemma 3 27B
IA em Escala Empresarial:
- Projetada para hardware de alto desempenho (ex.: clusters de GPU).
- Exemplo: IA generativa em larga escala, como sumarização ou tradução.
Serviços de IA Baseados em Nuvem:
- Preços competitivos para serviços de PNL centralizados.
- Exemplo: APIs hospedadas na nuvem para empresas.
Treinamento Intensivo em Recursos:
- Melhor para treinar modelos complexos em hardware poderoso.
QwQ 32B vs Gemma 3 27B: Tarefas
Prompt:
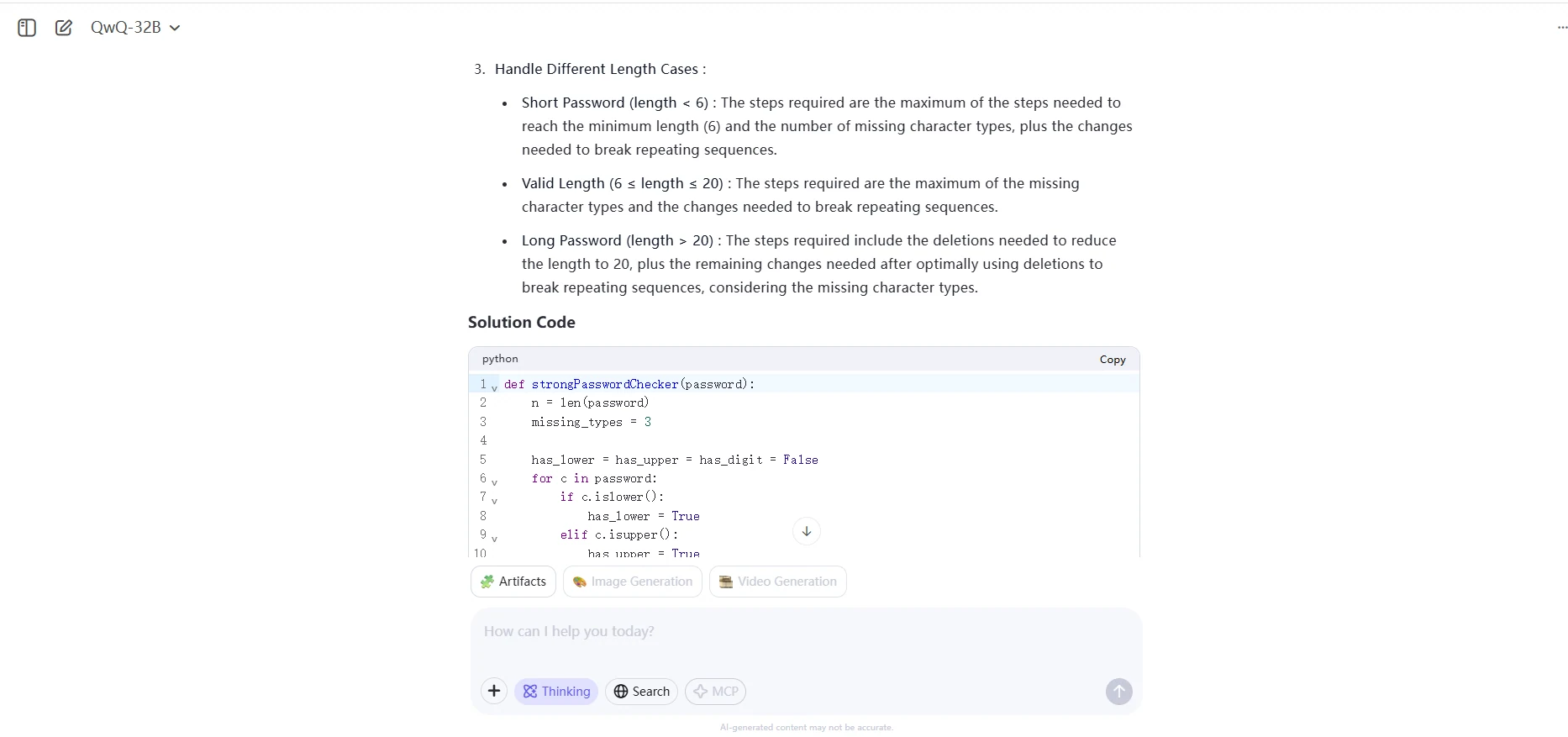
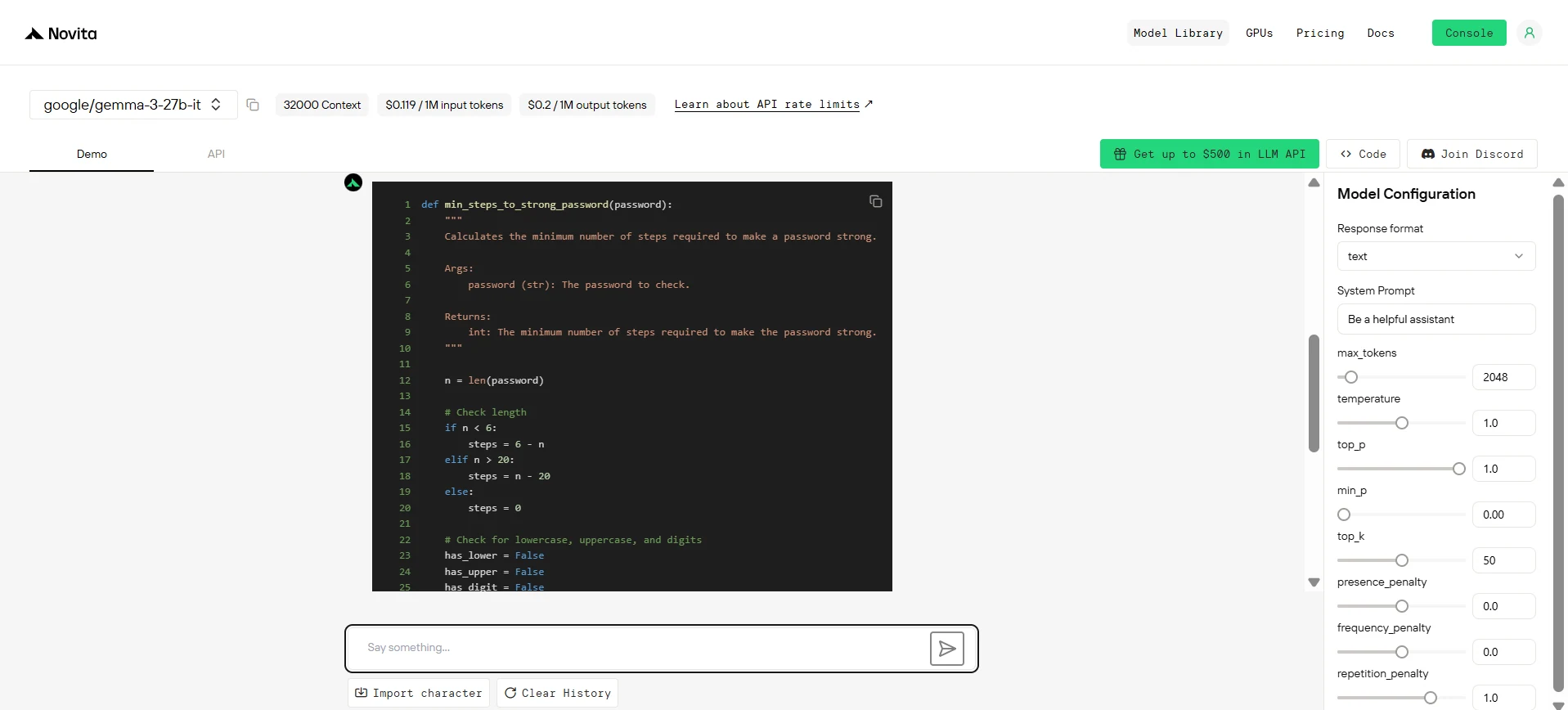
Uma senha é considerada forte se todas as condições abaixo forem atendidas:
- Ela tem pelo menos 6 caracteres e no máximo 20 caracteres.
- Ela contém pelo menos uma letra minúscula, pelo menos uma letra maiúscula e pelo menos um dígito.
- Ela não contém três caracteres repetidos em sequência (ex.: "Baaabb0" é fraca, mas "Baaba0" é forte).
Dada uma string password, retorne o número mínimo de passos necessários para tornar a senha forte. Se a senha já for forte, retorne 0.
Em um passo, você pode:
- Inserir um caractere na senha,
- Deletar um caractere da senha, ou
- Substituir um caractere da senha por outro caractere.
Exemplo 1:
Input: password = "a"
Output: 5
Exemplo 2:
Input: password = "aA1"
Output: 3
Exemplo 3:
Input: password = "1337C0d3"
Output: 0
Restrições:
1 <= password.length <= 50
password consiste em letras, dígitos, ponto '.' ou ponto de exclamação '!'.
QwQ 32B
Gemma 3 27B
Como Acessar QwQ 32B e Gemma 3 27B via API da Novita?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
[Experimente agora o Demo do QwQ 32B e Gemma 3 27B!](https://novita.ai/models/llm/meta-llama-llama-4-scout-17b-16e-instruct/?utm_source=blogs&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b)
Passo 4: Obtenha Sua Chave de API
Para autenticar na API, forneceremos uma nova chave de API. Entre na página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Para uma IA flexível e econômica com necessidades de hardware escaláveis, o QwQ 32B é a escolha ideal. Para tarefas de alta precisão e uso intensivo de recursos, o Gemma 3 27B é a melhor opção. Ambos os modelos estão disponíveis através das APIs da Novita AI, oferecendo acessibilidade e desempenho incomparáveis. Inicie seu teste gratuito hoje e experimente as capacidades desses modelos poderosos.
Perguntas Frequentes
Qual modelo é melhor para startups?
O QwQ 32B é melhor devido à sua flexibilidade, requisitos de hardware mais baixos e custo-benefício.
Posso usar esses modelos em dispositivos edge?
O QwQ 32B suporta modos de precisão mais baixa (8-bit, 4-bit), tornando-o adequado para aplicações edge e em tempo real. O Gemma 3 4B suporta Apple Silicon via mlx-vlm.
Há uma avaliação gratuita disponível para QwQ 32B e Gemma 3 27B?
Sim, você pode iniciar uma avaliação gratuita no site da [Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) para explorar tanto o QwQ 32B quanto o Gemma 3 27B.
[Novita AI](https://novita.ai/?utm_source=blog_llm&utm_medium=article&utm_campaign=qwq-32b-vs gemma-3-27b) é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, ao mesmo tempo que fornece uma GPU confiável e acessível na nuvem para construir e escalar.



