

主なポイント
QwQ 32B : 複雑なタスク、エッジケース、柔軟性を必要とするシナリオの処理に優れています。 16ビット、8ビット、4ビット精度 をサポートし、リアルタイムやコスト重視のアプリケーションに効率的です。
Gemma 3 27B : FP16サポート により高精度タスクに最適化されていますが、エッジケースや長いパスワードには弱く、リソース豊富な環境で最も性能を発揮します。
Novita AI は安定したAPIサービスを提供するだけでなく、非常にコストパフォーマンスの高い価格設定も提供しています。例えば、Gemma 3 27B は入力100万トークンあたりわずか$0.119、出力100万トークンあたり$0.2、QwQ 32B は入力100万トークンあたり$0.18、出力100万トークンあたり$0.2です。
QwQ 32B vs Gemma 3 27B: 基本紹介
QwQ 32B 紹介

Gemma 3 27B 紹介

QwQ 32B vs Gemma 3 27B: ベンチマーク
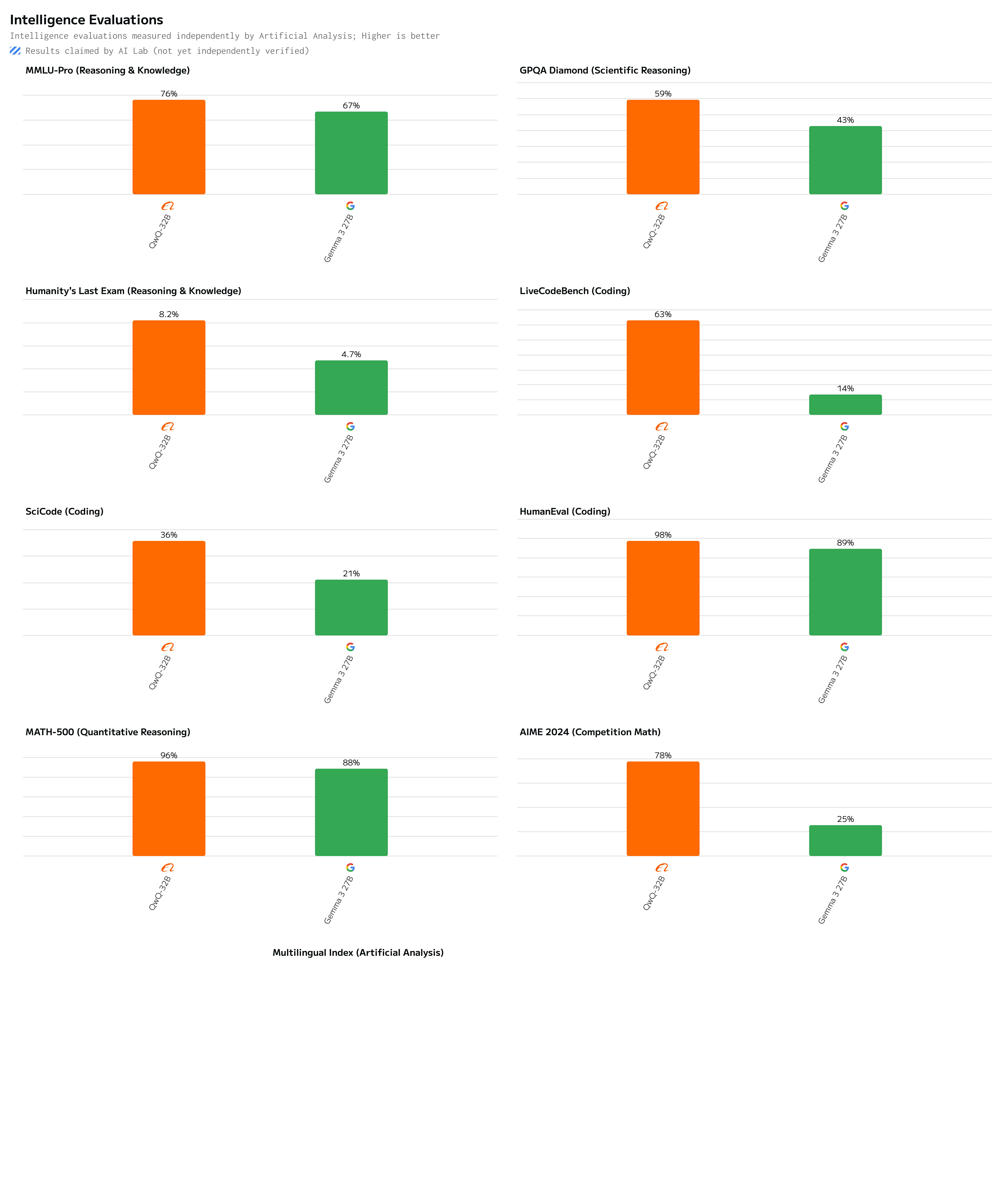
QwQ 32B はすべてのテストで Gemma 3 27B を上回っています。これは、QwQ 32B がマルチドメインタスクにおいてより強力な能力と汎用性を示す一方、Gemma 3 27B は特定の分野で優れる可能性があるものの、全体的には劣ることを示しています。
ご自身でテストしたい場合は、Novita AI のウェブサイトで無料トライアルを開始できます。

今すぐ QwQ 32B と Gemma 3 27B のデモを試す!
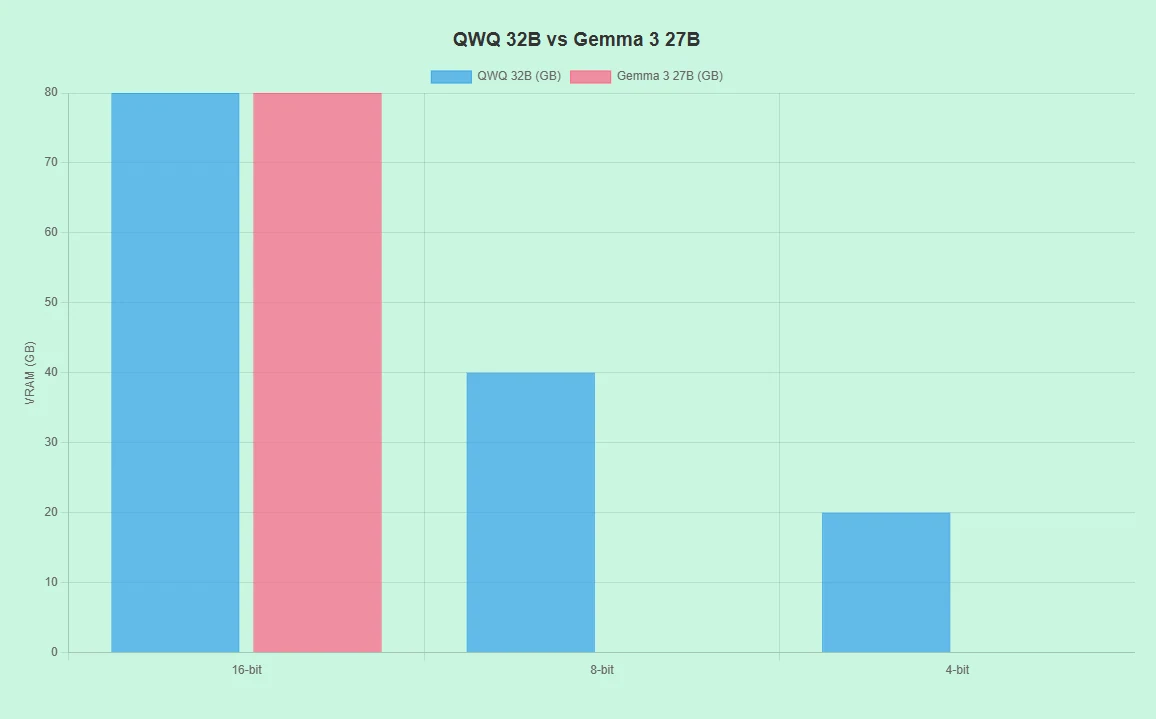
QwQ 32B vs Gemma 3 27B: ハードウェア要件
QwQ 32B vs Gemma 3 27B: アプリケーション
QwQ 32B
柔軟なデプロイ :
- RTX 4090、A100 などのさまざまなハードウェアを 16ビット、8ビット、4ビット精度 でサポート。
- スケーラブルで適応性の高い AI サービスに最適。
コスト効率の高いソリューション :
- 8ビット/4ビットモードでの低 VRAM 要求によりコスト削減。
- チャットボットやレコメンデーションシステムなど、予算に優しいアプリケーションに適しています。
リアルタイムおよびエッジアプリケーション :
- モバイル/IoT デバイスやリアルタイム AI タスクに対応。
- 例:オンデバイス AI やライブカスタマーサポートシステム。
カスタムファインチューニング :
- ミッドレンジ GPU での効率的なファインチューニングにより、ドメイン固有タスク(法律、医療モデルなど)に対応。
Gemma 3 27B
エンタープライズ規模の AI :
- 高性能ハードウェア(GPU クラスターなど)向けに設計。
- 例:要約や翻訳などの大規模生成 AI。
クラウドベースの AI サービス :
- 集中型 NLP サービス向けの競争力のある価格設定。
- 例:企業向けのクラウドホスト型 API。
リソース集約型トレーニング :
- 強力なハードウェアでの複雑なモデルトレーニングに最適。
QwQ 32B vs Gemma 3 27B: タスク
プロンプト:
パスワードは、以下の条件がすべて満たされている場合に強いと見なされます。
- 少なくとも6文字、最大20文字であること。
- 少なくとも1つの小文字、1つの大文字、1つの数字を含むこと。
- 連続して3つの繰り返し文字を含まないこと(例:"Baaabb0" は弱いが、"Baaba0" は強い)。
文字列パスワードが与えられたとき、パスワードを強くするために必要な最小ステップ数を返してください。パスワードがすでに強い場合は0を返します。
1ステップで、次のいずれかを行うことができます:
- パスワードに1文字挿入する、
- パスワードから1文字削除する、または
- パスワードの1文字を別の文字に置き換える。
例1:
入力: password = "a"
出力: 5
例2:
入力: password = "aA1"
出力: 3
例3:
入力: password = "1337C0d3"
出力: 0
制約:
1 <= password.length <= 50
password は英字、数字、ドット '.' または感嘆符 '!' で構成されます。
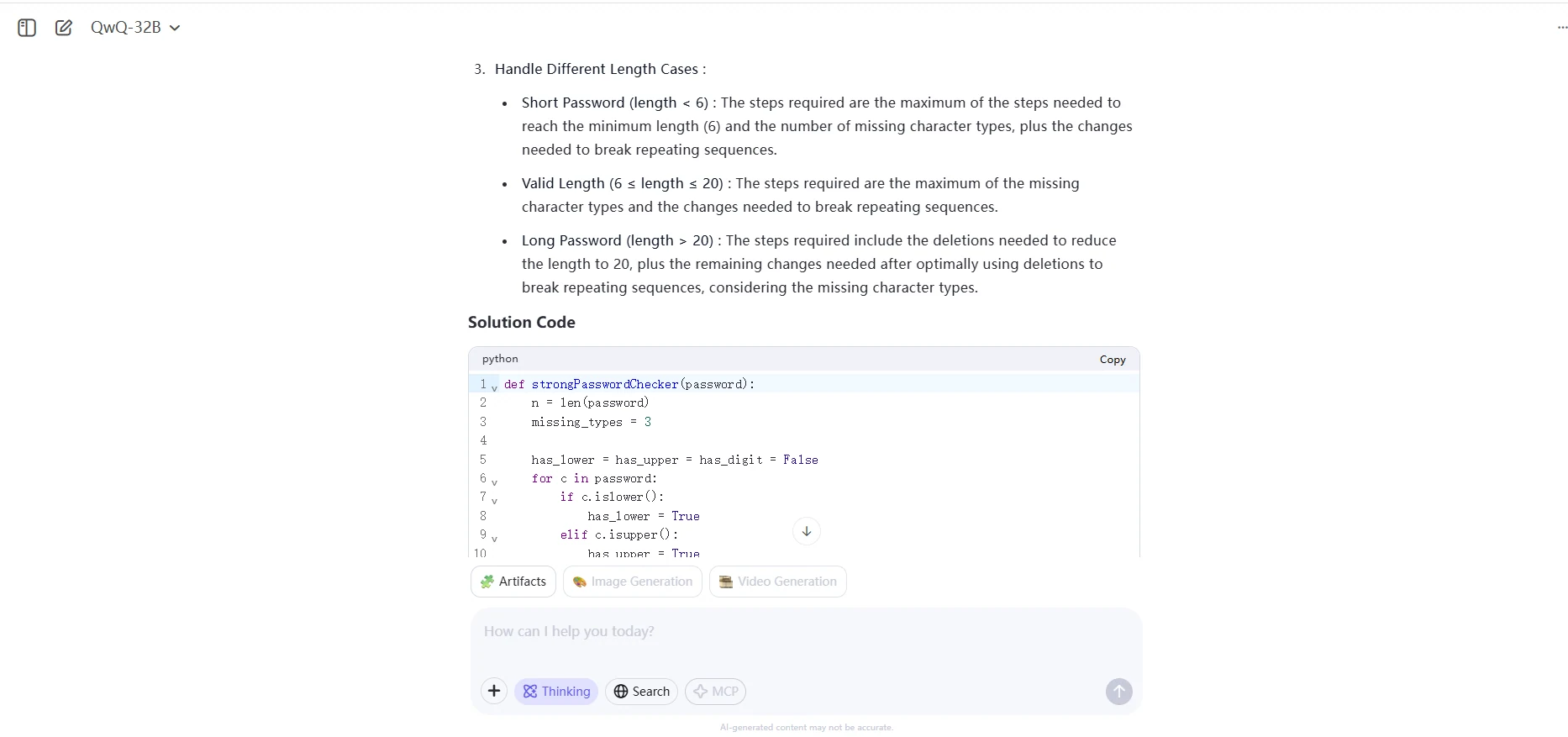
QwQ 32B
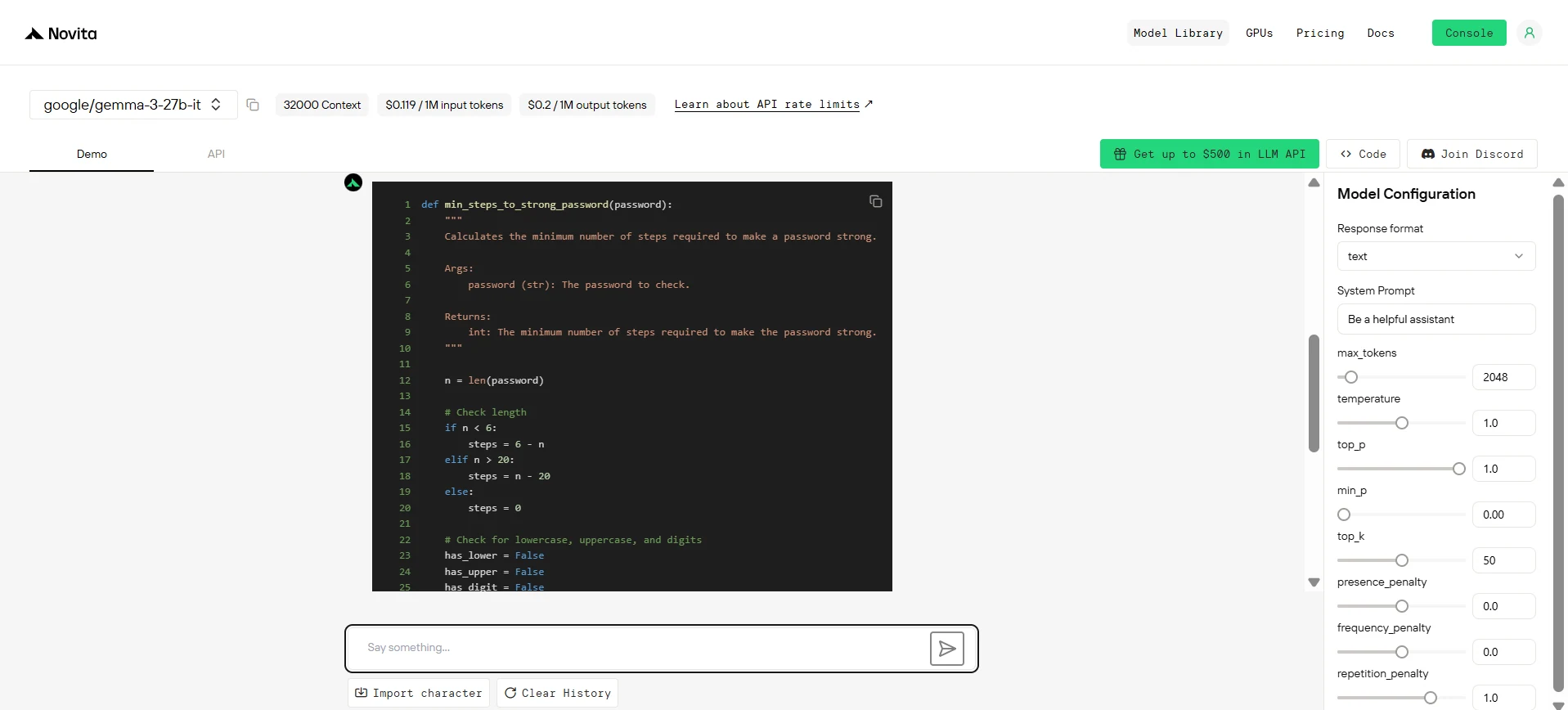
Gemma 3 27B
Novita API 経由で QwQ 32B と Gemma 3 27B にアクセスする方法
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、 モデルライブラリ ボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
今すぐ QwQ 32B と Gemma 3 27B のデモを試す!
ステップ4: API キーを取得
API で認証するために、新しい API キーを提供します。 「設定」 ページに移動し、画像のように API キーをコピーできます。

ステップ5: API をインストール
お使いのプログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。

インストール後、開発環境に必要なライブラリをインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。以下は、Python ユーザー向けの chat completions API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
柔軟でコスト効率が高く、スケーラブルなハードウェアを必要とする AI には、 QwQ 32B が理想的な選択肢です。高精度でリソース集約型のタスクには、 Gemma 3 27B がより良い選択肢です。どちらのモデルも Novita AI の API を通じて利用可能で、比類のないアクセス性とパフォーマンスを提供します。今すぐ無料トライアルを開始して、これらの強力なモデルの能力を体験してください。
よくある質問
スタートアップにはどのモデルが適していますか?
QwQ 32B は、柔軟性、低いハードウェア要件、コスト効率の良さから優れています。
これらのモデルをエッジデバイスで使用できますか?
QwQ 32B は低精度モード(8ビット、4ビット)をサポートしており、エッジおよびリアルタイムアプリケーションに適しています。Gemma 3 4B は Apple Silicon を mlx-vlm 経由でサポートしています。
QwQ 32B と Gemma 3 27B の無料トライアルはありますか?
はい、Novita AI のウェブサイトで無料トライアルを開始し、 QwQ 32B と Gemma 3 27B の両方を試すことができます。
*Novita AI *は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、AI の構築とスケーリングに手頃で信頼性の高い GPU クラウドも提供しています。



