

GLM-4.5V은 Zhipu AI에서 출시한 최신 오픈소스 멀티모달 대규모 언어 모델(LLM)로, 언어와 비전 작업을 통합된 시스템에서 처리하도록 설계되었습니다. 이는 기존 GLM-4.1V 모델의 주요 업그레이드 버전으로, 1060억 개의 매개변수를 가진 전문가 혼합(Mixture-of-Experts, MoE) 아키텍처(입력당 약 120억 개 활성화)를 특징으로 합니다.
이 설계를 통해 GLM-4.5V는 필요할 때만 전문 “전문가” 서브네트워크를 활성화하여 추론 비용을 낮추면서도 우수한 성능을 달성할 수 있습니다. 모델은 확장된 64k 토큰 컨텍스트를 위해 **3D 회전 위치 인코딩(3D Rotatory Positional Encoding, 3D-RoPE)**을 도입하여 긴 문서와 다차원 입력을 쉽게 처리할 수 있습니다.
간단히 말해, GLM-4.5V는 자연어 대화를 진행하면서도 이미지와 비디오를 “보고” 추론할 수 있어, 개발자를 위한 강력한 비전-언어 모델(VLM)입니다.
GLM 4.5V란 무엇인가요?
1. 고급 시각적 추론
- 기본 캡션을 넘어 복잡한 이미지, 과학 다이어그램, 비교를 이해합니다
- 공간 추론 지원: 객체와 경계 상자를 식별합니다
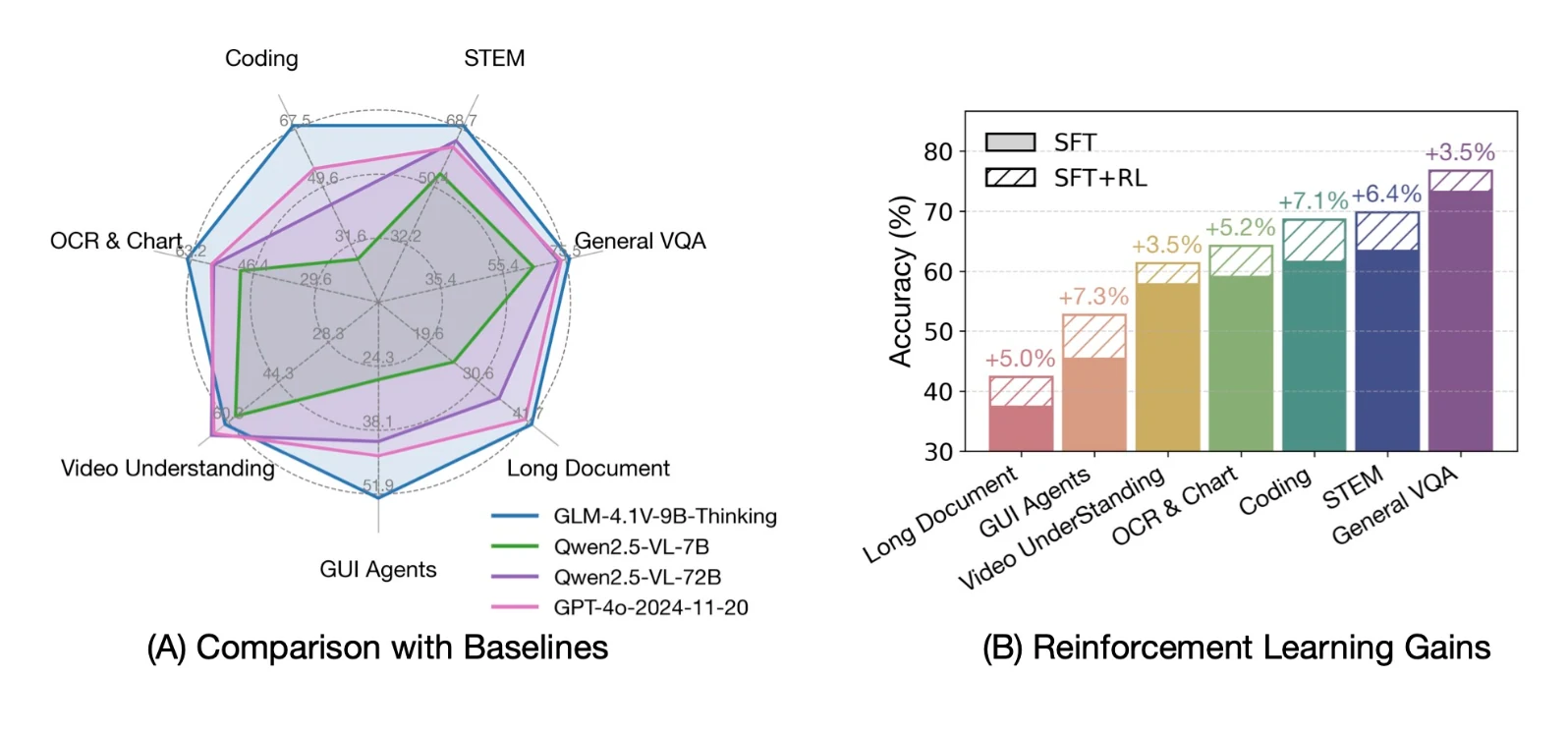
- MMBench 및 MMBench+ 와 같은 시각적 QA 벤치마크에서 최고 점수를 달성했습니다
2. 멀티모달 입력 + 사고 모드
- 대화에서 텍스트, 이미지, 비디오를 입력받습니다
- “사고 모드” 스위치 제공: 최종 답변 전 단계별 추론을 활성화합니다
- 논리적 설명이 필요한 복잡한 작업에 이상적입니다
3. 통합 도구 사용
- AI 에이전트 사용 사례를 위해 설계됨: 외부 도구나 API를 자율적으로 호출할 수 있습니다
- 함수 호출 기본 지원, OpenAI 인터페이스와 호환됩니다
- 도구 사용을 위한 데모 기반 훈련을 사용합니다
GLM-4.5V는 이미지 이해, 시각적 QA, 문서 OCR, 코드 생성, GUI 자동화를 통합 인터페이스를 통해 처리할 수 있는 강력하고 개발자 친화적인 멀티모달 AI 모델입니다. AI 에이전트, 생산성 도구, 연구 등에 이상적입니다.
GLM 4.5V 시스템 요구 사항
| 항목 | 세부 정보 |
|---|---|
| 모델 크기 | 106B 매개변수(MoE); 토큰당 12B 활성화 |
| VRAM | 640GB |
| 기준 GPU 요구 사항 | 8× NVIDIA H100 (각각 80GB) |
| 정밀도 옵션 | FP16, FP8, INT8, INT4 양자화 형식 지원 |
| 저용량 VRAM 설정(최적화됨) | FP8을 사용하고 신중한 분할을 통해 2×80GB GPU로 가능 |
| 병렬 처리 지원 | 텐서 및 모델 병렬 처리 지원(예: 4×40GB GPU) |
| 주요 라이브러리 | vLLM, SGLang |
GLM 4.5V API에 접근하는 방법
Novita AI를 통해 GLM-4.5V에 접근하면 다양한 기술 수준과 사용 사례에 맞춘 여러 경로를 제공합니다. 비즈니스 사용자가 AI 기능을 탐색하든, 프로덕션 애플리케이션을 구축하는 개발자든, Novita AI는 필요한 도구를 제공합니다.
1. 플레이그라운드 사용 (현재 사용 가능 - 코딩 불필요)
- 즉시 접근: 가입하고 몇 초 만에 GLM-4.5V 모델 실험을 시작하세요
- 인터랙티브 인터페이스: 복잡한 시각적 추론 프롬프트를 테스트하고 실시간으로 사고 과정 출력을 시각화하세요
- 모델 비교: 특정 사용 사례에 맞춰 GLM-4.5V를 다른 주요 모델과 비교하세요
플레이그라운드를 사용하면 이미지를 직접 업로드하고, 다양한 프롬프트를 테스트하며, 기술 설정 없이 즉시 결과를 확인할 수 있습니다. 프로토타이핑, 아이디어 테스트, 전체 구현 전 모델 기능을 이해하기에 완벽합니다.
2. API를 통한 통합 (라이브 및 준비 완료 - 개발자용)
Novita AI의 통합 REST API로 GLM-4.5V를 애플리케이션에 연결하세요.
옵션 1: 직접 API 통합 (Python 예시)

from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
주요 기능:
- 원활한 통합을 위한 OpenAI 호환 API
- 응답 미세 조정을 위한 유연한 매개변수 제어
- 실시간 응답을 위한 스트리밍 지원
옵션 2: OpenAI Agents SDK를 사용한 멀티 에이전트 워크플로우
GLM-4.5V를 사용하여 정교한 멀티 에이전트 시스템을 구축하세요:
- 플러그 앤 플레이 통합: 모든 OpenAI Agents 워크플로우에서 GLM-4.5V 사용
- 고급 에이전트 기능: 우수한 시각적 추론 성능을 갖춘 핸드오프, 라우팅, 도구 통합 지원
- 확장 가능한 아키텍처: GLM-4.5V의 통합 추론, 코딩, 시각적 분석 기능을 활용하는 에이전트 설계
3. 타사 플랫폼과 연결
개발 도구: Cursor, Trae, Qwen Code, Cline과 같은 인기 IDE 및 개발 환경을 OpenAI 호환 API를 통해 원활하게 통합합니다.
오케스트레이션 프레임워크: 공식 커넥터를 사용하여 LangChain, Dify, CrewAI, Langflow 및 기타 AI 오케스트레이션 플랫폼과 연결합니다.
**Hugging Face 통합: Novita AI는 Hugging Face의 공식 추론 제공자로서 광범위한 생태계 호환성을 보장합니다.
GLM 4.5V 명령줄 인터페이스(CLI) 사용
로컬에서 모델을 실행하거나 환경에 대한 더 많은 제어를 원하는 개발자의 경우, GLM-4.5V를 명령줄 인터페이스를 통해 사용할 수도 있습니다. Zhipu AI는 모델 가중치를 오픈소스로 공개하고 자체 하드웨어에서 모델을 실행할 수 있는 도구를 제공했습니다.
모델은 Hugging Face Hub에서 zai-org/GLM-4.5V로 사용할 수 있습니다. 모델을 다운로드한 다음 Transformers 라이브러리를 사용하여 출력을 생성할 수 있습니다. 예를 들어, Python 스크립트나 Jupyter 노트북에서:
python3 inference/trans_infer_cli.py --model-path zai-org/GLM-4.5V --image test.jpg --question "这张图里有什么?"
| 기능 | CLI | API |
|---|---|---|
| 사용법 | 터미널에서 명령 + 매개변수 입력 | 코드에서 라이브러리/HTTP 요청 호출 |
| 출력 | 터미널에 직접 출력 | 객체/JSON 반환, 후속 처리 용이 |
| 적합한 경우 | 모델 테스트, 빠른 추론, 소규모 스크립트 | 애플리케이션 개발, 서비스 통합, 대규모 호출 |
| 유연성 | 고정 매개변수, 제한된 조합 | 완전히 프로그래밍 가능, 복잡한 로직 지원 |
| 종속성 | 스크립트/CLI 도구만 필요 | 코드 작성 및 종속성 관리 필요 |
MCP와 GLM4.5V를 사용한 간단한 이미지 인식 도구 구축
GLM의 기능을 활용하여 시각적 인식과 추론의 통합을 보여주는 간단한 이미지 인식 도구를 구축하려는 경우, Novita AI가 지원하는 MCP 기능을 사용할 수 있습니다. 아래는 샘플 코드입니다:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
일반적인 GLM 4.5V 문제 해결
1. 메모리 및 로딩 오류 (CUDA OOM)
원인: 모델 크기가 사용 가능한 GPU 메모리에 맞지 않습니다.
해결 방법:
- 권장 추론 백엔드 사용
- 예: SGLang에서
--attention-backend fa3을 활성화하여 메모리 사용량을 줄입니다.
- 예: SGLang에서
- 더 작은 텐서 병렬 크기로 더 많은 GPU 사용
- 예: TP=4 대신 TP=8(8개 GPU)로 설정하여 GPU당 더 작은 모델 청크를 할당합니다.
- 양자화된 모델 로드(8비트 또는 4비트)
- 예: HuggingFace Transformers를 사용할 때
load_in_8bit=True를 사용합니다.
- 예: HuggingFace Transformers를 사용할 때
- 더 높은 VRAM을 가진 클라우드 인스턴스 선택
- 예: A100(80GB) 또는 H200(141GB); H200은 단일 GPU에서 모델을 실행할 수 있습니다.
- 긴 입력을 더 작은 청크로 처리
- 긴 비디오를 더 짧은 세그먼트로 분할하거나 출력 크기를 줄이기 위해 사고 모드를 비활성화합니다.
2. 이미지 입력이 인식되지 않음
원인: 이미지가 모델에 올바르게 형식화되거나 전달되지 않았습니다.
해결 방법:
- OpenAI 스타일 API의 경우, 입력을 특수 메시지로 구조화합니다
- 예:
[{"type": "image_url", "image_url": {"url": "<URL>"}}, {"type": "text", "text": "your question"}]
- 예:
- HuggingFace Transformers를 사용할 때
AutoProcessor사용- 예: 추론 전에
processor(images=[...], text=[...])를 호출합니다.
- 예: 추론 전에
- 이미지 URL이 공개인지 확인하거나 지원되는 경우 base64 인코딩 사용
- 모델이 이미지를 무시하거나 이미지를 받지 못했다고 말하는 경우 입력이 유효하지 않을 수 있습니다.
4. 이상한 출력 형식
문제:
- 출력에 원시 HTML이 포함됨(예:
<div>...</div>) - 예상치 못한 이스케이프 문자(예:
<) - 반복되거나 추가된 답변
해결 방법:
- 모델에 코드를 Markdown 형식으로 포맷하도록 지시합니다(예: 삼중 백틱 사용)
- HTML 이스케이프를 수정하는 패치 적용(공식 리포지토리에서 사용 가능)
- 필요하지 않은 경우 사고 모드 비활성화
- 중복 콘텐츠를 제거하도록 출력 후처리
5. 도구 사용 아티팩트
문제: 모델이 도구 관련 명령을 출력합니다(예: <|search|>).
해결 방법: 표준 채팅 완성 API를 사용하고 도구 사용 시나리오를 모방하는 프롬프트를 피하세요.
6. 정확도 제한
알려진 제한 사항:
- 개수 세기나 얼굴 인식과 같은 세밀한 시각적 작업에서 어려움을 겪을 수 있습니다
- 텍스트 전용 질문은 전문 텍스트 모델이 더 잘 답변할 수 있습니다
- 매우 긴 문서나 비디오의 경우 느리며 타임아웃이 발생할 수 있습니다
권장 사항:
- 긴 입력에 스트리밍 모드를 사용하여 부분 출력을 받습니다
- 대용량 입력을 작은 세그먼트로 분할합니다
- API 제공업체의 실제 컨텍스트 길이 제한을 확인합니다
GLM-4.5V는 비전-언어 AI의 게임 체인저로, 이전에는 독점 모델의 영역이었던 기능을 오픈소스 및 자체 호스트 세계로 가져옵니다. 우리는 GLM-4.5V가 무엇인지, 왜 특별한지, 실행하는 데 필요한 설정, 일반적인 문제 해결 방법, 접근 방법(클라우드 API 또는 로컬 CLI)을 다루었습니다. 이 지식을 바탕으로 개발자는 자신의 프로젝트에 GLM-4.5V를 자신감 있게 통합할 수 있습니다.
Gemma 3 27B에서 GLM 4.5V로 업그레이드해야 할까요?
GLM-4.5V는 Zhipu AI의 최신 오픈소스 멀티모달 대규모 언어 모델입니다. 텍스트, 이미지, 비디오를 처리할 수 있으며 고급 추론 기능을 갖추고 있습니다.
GLM-4.5V는 무엇을 할 수 있나요?
고급 시각적 추론(예: 과학 다이어그램, 공간 추론, 시각적 QA), 긴 문서 이해, 코드 생성, OCR, GUI 자동화, 멀티모달 대화를 지원합니다.
GLM-4.5V는 이전 모델과 어떻게 다른가요?
전문가 혼합(Mixture-of-Experts, MoE) 아키텍처를 사용하여 106B 매개변수(입력당 12B 활성화)로 GLM-4.1V를 개선했으며, 3D-RoPE를 통해 64k 컨텍스트 길이를 지원하여 더 낮은 비용과 더 강력한 성능을 제공합니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구를 제공합니다. 인프라를 제거하고, 무료로 시작하고, AI 비전을 현실로 만드세요.



