

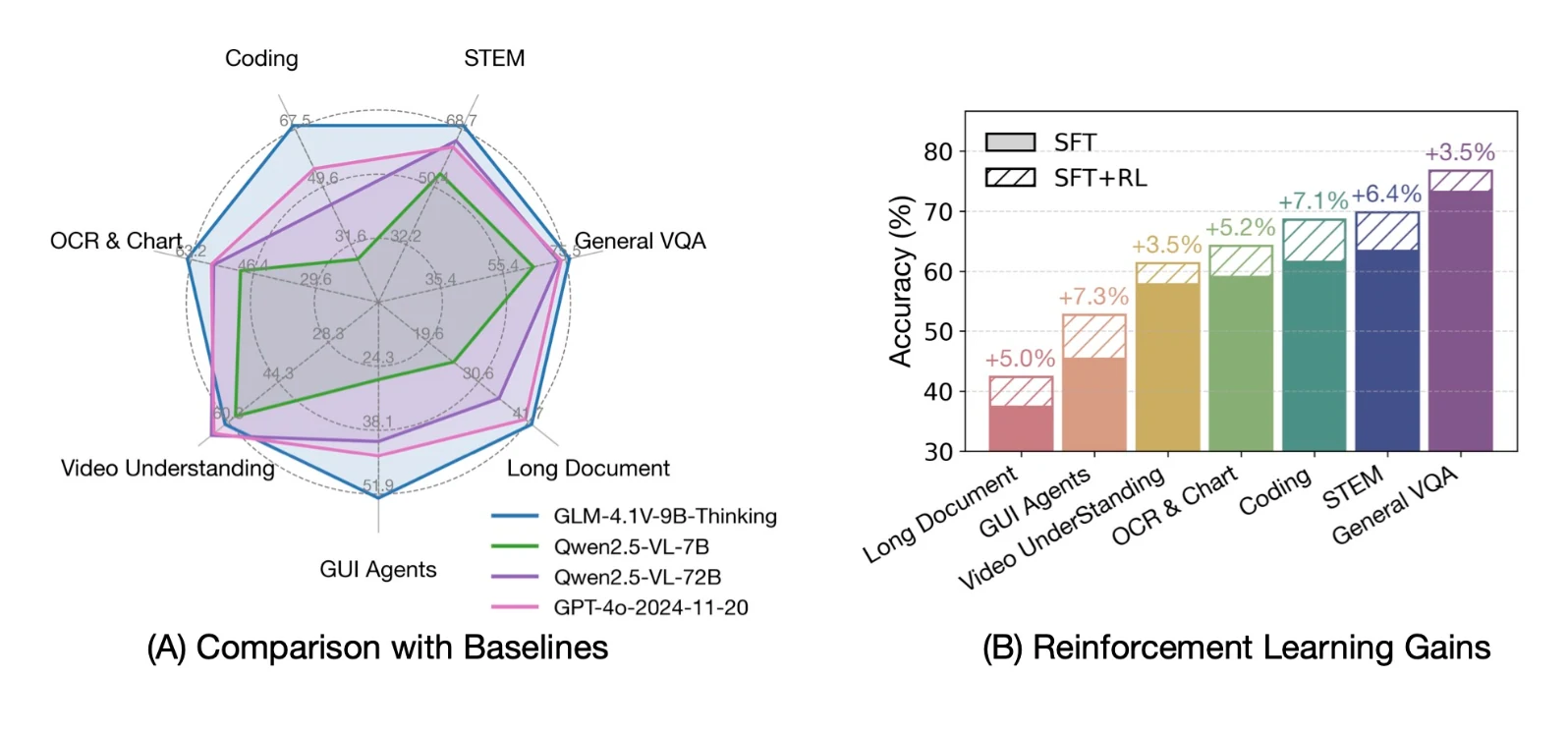
GLM-4.5V — это последняя открытая многомодальная большая языковая модель (LLM) от Zhipu AI, созданная для решения как языковых, так и зрительных задач в единой системе. Это значительное обновление по сравнению с предыдущей моделью GLM-4.1V, в которой используется архитектура смеси экспертов (MoE) с 106 миллиардами параметров (около 12 миллиардов активных на каждый вход).
Такая архитектура позволяет GLM-4.5V достигать превосходной производительности при более низкой стоимости вывода, активируя специализированные подсети «экспертов» только по необходимости. В модели реализовано 3D-вращательное позиционное кодирование (3D-RoPE) для расширенного контекста в 64k токенов, что позволяет легко работать с длинными документами и многомерными входными данными.
Проще говоря, GLM-4.5V может «видеть» и анализировать изображения и видео, а также вести диалог на естественном языке, что делает её мощной зрительно-языковой моделью (VLM) для разработчиков.
Что такое GLM 4.5V?
1. Продвинутое визуальное рассуждение
- Выходит за рамки простого описания — понимает сложные изображения, научные диаграммы и сравнения
- Поддерживает пространственное рассуждение: определяет объекты и ограничивающие рамки
- Достигла лучших результатов в бенчмарках визуального ответа на вопросы, таких как MMBench и MMBench+
Источник: Hugging Face
2. Многомодальный ввод + Режим рассуждения
- Принимает текст, изображения и видео в диалогах
- Предлагает переключатель «Режима рассуждения»: включает пошаговое рассуждение перед окончательным ответом
- Идеально подходит для сложных задач, требующих логических объяснений
Источник: Hugging Face
3. Унифицированное использование инструментов
- Создан для вариантов использования AI-агентов — может автономно вызывать внешние инструменты или API
- Встроенная поддержка вызова функций, совместимая с интерфейсом OpenAI
- Использует обучение на основе демонстраций для работы с инструментами
GLM-4.5V — это мощная, удобная для разработчиков многомодальная ИИ-модель, способная выполнять распознавание изображений, визуальный ответ на вопросы, OCR документов, генерацию кода и автоматизацию графического интерфейса — всё через единый интерфейс. Идеально подходит для AI-агентов, инструментов повышения производительности, исследований и многого другого.
Системные требования для GLM 4.5V
| Параметр | Детали |
|---|---|
| Размер модели | 106 млрд параметров (MoE); 12 млрд активных на токен |
| Объем VRAM | 640 ГБ |
| Минимальные требования к GPU | 8× NVIDIA H100 (по 80 ГБ каждый) |
| Варианты точности | Поддерживаются форматы квантования FP16, FP8, INT8, INT4 |
| Конфигурация с низким объемом VRAM (оптимизированная) | Возможна на 2×80 ГБ GPU с использованием FP8 и аккуратным разделением |
| Поддержка параллелизма | Поддерживается тензорный и модельный параллелизм (например, 4×40 ГБ GPU) |
| Ключевые библиотеки | vLLM, SGLang |
Как получить доступ к API GLM 4.5V
Доступ к GLM-4.5V через Novita AI предоставляет несколько вариантов, адаптированных под разные уровни технической подготовки и варианты использования. Будь вы бизнес-пользователем, изучающим возможности ИИ, или разработчиком, создающим производственные приложения, Novita AI предоставляет все необходимые инструменты.
1. Использование Playground (Доступно сейчас — не требуется написание кода)
- Мгновенный доступ: Зарегистрируйтесь и начните экспериментировать с моделями GLM-4.5V за несколько секунд
- Интерактивный интерфейс: Тестируйте сложные запросы на визуальное рассуждение и визуализируйте результаты пошагового мышления в реальном времени
- Сравнение моделей: Сравнивайте GLM-4.5V с другими ведущими моделями для вашего конкретного варианта использования
Playground позволяет загружать изображения напрямую, тестировать различные запросы и видеть немедленные результаты без какой-либо технической настройки. Идеально подходит для прототипирования, тестирования идей и понимания возможностей модели перед полной реализацией.
2. Интеграция через API (Работает и готово к использованию — для разработчиков)
Подключите GLM-4.5V к вашим приложениям с помощью единого REST API от Novita AI.
Вариант 1: Прямая интеграция через API (пример на Python)

Попробуйте GLM4.5V прямо сейчас!
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Ключевые особенности:
- API, совместимый с OpenAI, для бесшовной интеграции
- Гибкое управление параметрами для тонкой настройки ответов
- Поддержка потоковой передачи для ответов в реальном времени
Вариант 2: Многомодальные рабочие процессы с OpenAI Agents SDK
Создавайте сложные многоагентные системы с использованием GLM-4.5V:
- Интеграция из коробки: Используйте GLM-4.5V в любом рабочем процессе OpenAI Agents
- Расширенные возможности агентов: Поддержка передачи задач, маршрутизации и интеграции инструментов с превосходной производительностью визуального рассуждения
- Масштабируемая архитектура: Проектируйте агентов, которые используют унифицированные возможности GLM-4.5V по рассуждению, написанию кода и визуальному анализу
3. Подключение к сторонним платформам
Инструменты для разработки: Бесшовно интегрируйтесь с популярными IDE и средами разработки, такими как Cursor, Trae, Qwen Code и Cline через API, совместимые с OpenAI.
Фреймворки для оркестрации: Подключайтесь к LangChain, Dify, CrewAI, Langflow и другим платформам для оркестрации ИИ с использованием официальных коннекторов.
Интеграция с Hugging Face: Novita AI является официальным провайдером вывода для Hugging Face, что обеспечивает широкую совместимость с экосистемой.
Использование интерфейса командной строки (CLI) GLM 4.5V
Для разработчиков, которые предпочитают запускать модели локально или хотят больше контроля над окружением, GLM-4.5V также можно использовать через интерфейс командной строки. Zhipu AI открыла веса модели и предоставила инструменты для запуска модели на вашем собственном оборудовании.
Модель доступна на Hugging Face Hub под именем zai-org/GLM-4.5V. Вы можете скачать модель, а затем использовать библиотеку Transformers для генерации выходных данных. Например, в Python-скрипте или блокноте Jupyter:
python3 inference/trans_infer_cli.py --model-path zai-org/GLM-4.5V --image test.jpg --question "这张图里有什么?"
| Функция | CLI | API |
|---|---|---|
| Использование | Ввод команд и параметров в терминале | Вызов библиотек/HTTP-запросов в коде |
| Вывод | Печатается напрямую в терминал | Возвращает объекты/JSON, удобные для дальнейшей обработки |
| Идеально подходит для | Тестирования моделей, быстрого вывода, небольших скриптов | Разработки приложений, интеграции сервисов, массовых вызовов |
| Гибкость | Фиксированные параметры, ограниченные комбинации | Полностью программируемый, поддерживает сложную логику |
| Зависимости | Требуется только скрипт/инструмент CLI | Требуется написание кода и управление зависимостями |
Попробуйте GLM4.5V прямо сейчас!
Создание простого инструмента для распознавания изображений с использованием MCP и GLM4.5V
Если вы хотите использовать возможности GLM — например, создать простой инструмент для распознавания изображений, чтобы продемонстрировать интеграцию визуального распознавания и рассуждения — вы можете использовать функциональность MCP, поддерживаемую Novita AI. Ниже приведен пример кода:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Попробуйте GLM4.5V прямо сейчас!
Устранение распространенных проблем с GLM 4.5V
1. Ошибки памяти и загрузки (CUDA OOM)
Причина: Модель слишком велика, чтобы поместиться в доступную память GPU.
Решения:
- Используйте рекомендуемый бэкенд для вывода
- Пример: Включите
--attention-backend fa3в SGLang, чтобы снизить использование памяти.
- Пример: Включите
- Используйте больше GPU с меньшим размером тензорного параллелизма
- Пример: Установите TP=8 (8 GPU) вместо TP=4, чтобы распределять меньшие части модели на каждый GPU.
- Загрузите квантованную модель (8-бит или 4-бит)
- Например, используйте
load_in_8bit=Trueпри работе с HuggingFace Transformers.
- Например, используйте
- Выбирайте облачные инстансы с большим объемом VRAM
- Пример: A100 (80 ГБ) или H200 (141 ГБ); H200 может запускать модель на одном GPU.
- Обрабатывайте длинные входные данные меньшими частями
- Разделяйте длинные видео на более короткие сегменты или отключайте режим рассуждения, чтобы уменьшить размер вывода.
2. Входные изображения не распознаются
Причина: Изображение отформатировано или передано модели некорректно.
Решения:
- Для API в стиле OpenAI структурируйте входные данные как специальное сообщение
- Пример:
[{"type": "image_url", "image_url": {"url": "<URL>"}}, {"type": "text", "text": "your question"}]
- Пример:
- При использовании HuggingFace Transformers используйте
AutoProcessor- Пример: Вызовите
processor(images=[...], text=[...])перед выводом.
- Пример: Вызовите
- Убедитесь, что URL изображения является публичным, или используйте кодирование base64, если оно поддерживается
- Если модель игнорирует изображение или сообщает, что не получила его, входные данные могут быть недействительными.
4. Нестандартное форматирование вывода
Проблемы:
- В выводе присутствует сырой HTML (например,
<div>...</div>) - Неожиданные экранирующие символы (например,
<) - Повторяющиеся или добавленные в конце ответы
Решения:
- Попросите модель форматировать код в Markdown (например, использовать тройные обратные кавычки)
- Примените патчи для исправления экранирования HTML (доступны в официальных репозиториях)
- Отключите режим рассуждения, если он не нужен
- Постобработайте вывод, чтобы удалить дублирующийся контент
5. Артефакты использования инструментов
Проблема: Модель выводит команды, связанные с инструментами (например, <|search|>).
Решение:
Используйте стандартный API завершения чата вместо конечных точек агентов и избегайте запросов, имитирующих сценарии использования инструментов.
6. Ограничения точности
Известные ограничения:
- Может испытывать трудности с тонкими визуальными задачами, такими как подсчет или распознавание лиц
- Вопросы только с текстом могут лучше отвечать специализированные текстовые модели
- Медленно работает с очень длинными документами или видео; может возникать таймаут
Рекомендации:
- Используйте режим потоковой передачи для длинных входных данных, чтобы получать частичные выводы
- Разделяйте большие входные данные на более мелкие сегменты
- Проверьте фактические лимиты длины контекста вашего API-провайдера
GLM-4.5V меняет правила игры в области зрительно-языкового ИИ, перенося возможности, которые ранее были доступны только в проприетарных моделях, в мир открытого исходного кода и самостоятельного хостинга. Мы рассмотрели, что такое GLM-4.5V и чем она особенна, какая настройка требуется для её запуска, как устранять распространенные проблемы и несколько способов получить к ней доступ (облачный API или локальный CLI). Имея эти знания, разработчики могут с уверенностью интегрировать GLM-4.5V в свои проекты
Стоит ли обновляться с Gemma 3 27B до GLM 4.5V?
GLM-4.5V — это последняя открытая многомодальная большая языковая модель от Zhipu AI. Она может выполнять как языковые, так и зрительные задачи, включая работу с текстом, изображениями и видео, с расширенными возможностями рассуждения.
Что может делать GLM-4.5V?
Она поддерживает продвинутое визуальное рассуждение (например, научные диаграммы, пространственное рассуждение, визуальный ответ на вопросы), понимание длинных документов, генерацию кода, OCR, автоматизацию графического интерфейса и многомодальный диалог.
Чем GLM-4.5V отличается от предыдущих моделей?
Она улучшает GLM-4.1V за счет использования архитектуры смеси экспертов (MoE) с 106 млрд параметров (12 млрд активных на вход), а также 3D-RoPE для длины контекста в 64k токенов, что обеспечивает более низкую стоимость и более высокую производительность.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши ИИ-амбиции. Интегрированные API, бессерверные вычисления, GPU-инстансы — доступные инструменты, которые вам нужны. Избавьтесь от инфраструктуры, начните бесплатно и воплотите ваше ИИ-видение в реальность.



