

- Features of GLM 4.5V not in GLM 4.1V
- GLM 4.5V vs GLM 4.1V: Architecture Comparison
- GLM 4.5V vs GLM 4.1V: Benchmark Comparison
- GLM 4.5V vs GLM 4.1V: Hardware Comparison
- GLM 4.5V vs GLM 4.1V: Application Comparison
- GLM 4.5V‘s Cost Advantages
- Novita AI: More Cost-Effectvely and Stable GLM 4.5V API Provider
- Build a Simple Image Recognition Tool using MCP and GLM.
GLM-4.5V represents a significant leap forward from GLM-4.1V, delivering enhanced scalability, multimodal capabilities, and cost efficiency. By integrating domain-specific experts, advanced vision modules, and a Mixture-of-Experts (MoE) architecture, GLM-4.5V excels in tasks like document understanding, real-time video OCR, and multimodal content generation, making it a versatile and developer-friendly solution.
Features of GLM 4.5V not in GLM 4.1V
GLM-4.5V demonstrates significantly higher versatility and tool integration compared to GLM-4.1V. It streamlines tasks that previously required multiple specialized models, handling everything from basic image recognition to complex video analysis and document processing within a single system. For instance, GLM-4.5V can generate front-end code from a webpage screenshot or analyze a map image for geolocation clues. Its ability to integrate reasoning with external tools and produce structured outputs sets it apart from GLM-4.1V, making 4.5V a more developer-friendly and scalable multimodal AI platform.

GLM 4.5V vs GLM 4.1V: Architecture Comparison
| Aspect | GLM-4.1V | GLM-4.5V |
|---|---|---|
| Scale | 9B parameters, dense transformer. | 106B total, 12B active via Mixture-of-Experts (MoE). |
| Specialization | Generalist model. | Domain-specific experts via MoE for better task performance. |
| Vision Modules | 2D image processing only. | Adds 3D convolution for video and GUI recognition. |
| Context Encoding | 2D RoPE for ~64k tokens. | 3D RoPE for 64k tokens + multi-dimensional input |
| Foundation Model | Based on GLM-4 (9B). | Built on GLM-4.5-Air, with enhanced language and multimodal capabilities. |
GLM 4.5V vs GLM 4.1V: Benchmark Comparison
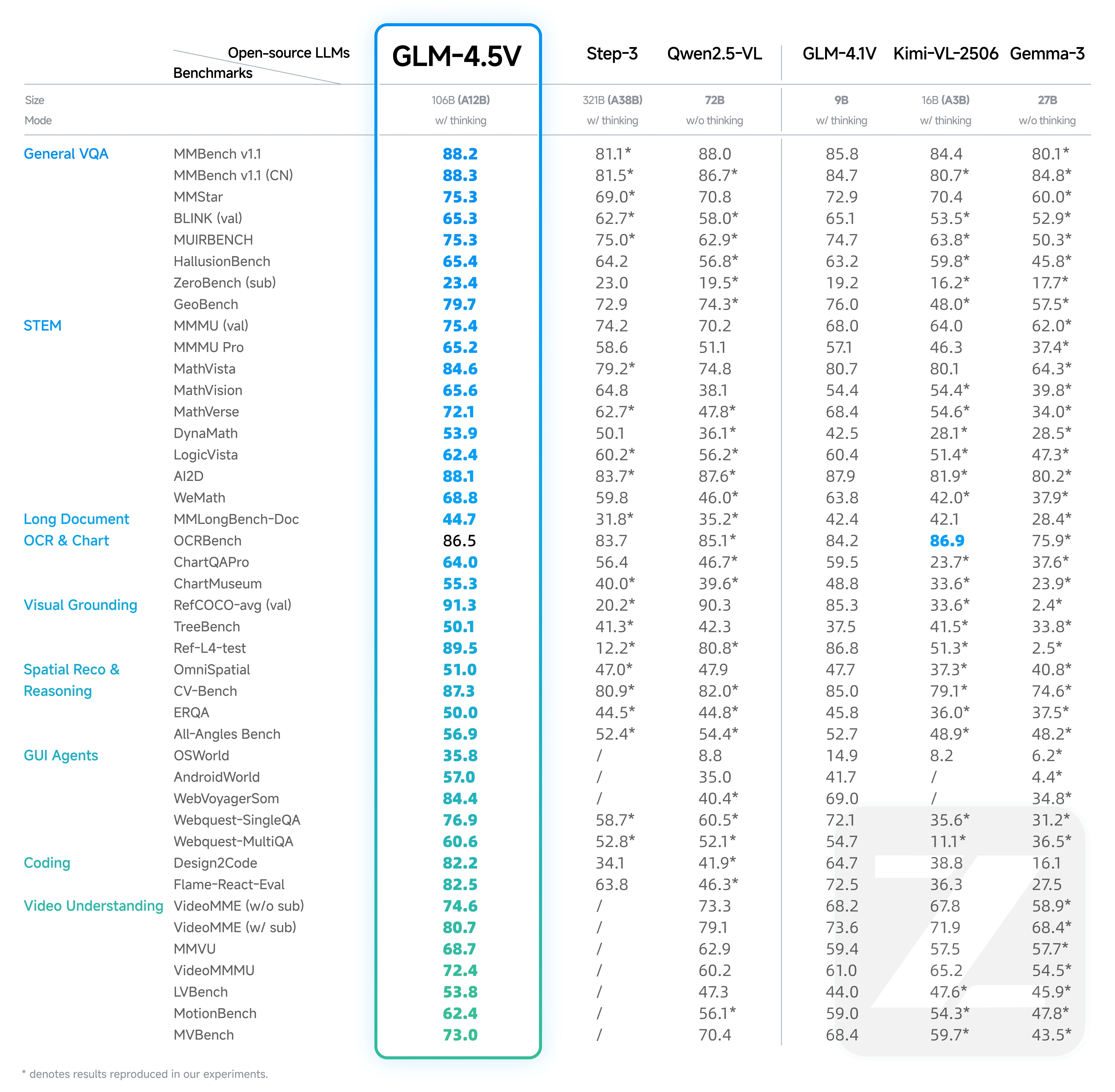
From Hugging Face
GLM-4.1V’s Achievements:
- Outperformed larger models like Qwen-2.5-VL (7B) and rivaled Qwen-72B despite its smaller size.
- Defined state-of-the-art for small-scale models before 2025.
GLM-4.5V’s Advancements:
- Surpassed open models in its parameter range and outperformed some larger models.
- Beat Step-3 (321B parameters) on multiple key benchmarks, showcasing its efficiency and accuracy.
Key Strengths of GLM-4.5V:
- Excels in general visual QA, STEM reasoning, and long-document OCR.
- Leverages MoE architecture and advanced training optimizations for superior performance.
GLM 4.5V vs GLM 4.1V: Hardware Comparison
| Aspect | GLM-4.1V | GLM-4.5V |
|---|---|---|
| VRAM Requirements | 24GB (e.g., NVIDIA A100 40GB, RTX 4090) | 80GB per GPU; typically requires 8×80GB GPUs for full deployment. |
| GPU Setup | Single high-end GPU is sufficient. | Multi-GPU setup (e.g., 8 GPUs) or cloud GPU clusters required. |
| CPU Compatibility | Can run on CPU (non-real-time) with optimizations. | Not designed for CPU; demands advanced hardware or cloud-based solutions. |
| Quantization Options | Supports 16-bit, 8-bit, and even 4-bit quantization for reduced memory. | Offers memory-optimized versions (e.g., FP8 quantization) to alleviate hardware demands. |
By offering a flexible reasoning mode and efficient speed-accuracy adjustments, GLM-4.5V minimizes hardware requirements, making it suitable for both high-performance and lightweight real-time use cases.
GLM 4.5V vs GLM 4.1V: Application Comparison
GLM 4.5V
1. Document Understanding
- Recognizes and analyzes text in complex documents.
- Handles handwriting, stamps, watermarks, and distortions.
- Extracts key information and generates structured summaries.
2. Table Recognition and Reconstruction
- Processes complex tables with merged cells and nested structures.
- Infers missing data and ensures consistency.
- Converts image-based tables into Excel, CSV, etc.
3. Multimodal Content Generation
- Generates reports and summaries based on recognized text, charts, or images.
- Provides trend analysis and actionable recommendations.
- Supports creation from handwritten notes or forms.
4. Real-time Video OCR
- Extracts subtitles and on-screen text from video streams.
- Tracks moving text dynamically and adapts to scene changes.
- Recognizes multiple languages in real-time.
GLM 4.1V
-
Educational Tools
- Ideal for teaching AI reasoning step-by-step with image analysis.
- Outputs both answers and reasoning, aiding in understanding AI decision-making.
-
Sensitive Applications
- Useful in fields like medical image analysis where transparency and chain-of-thought explanations are critical.
-
Lightweight Systems
- Can be deployed on simple web apps or devices with minimal back-end resources.
-
Experimentation and Research
- Compact model size makes it accessible for researchers and developers with limited computing power.
-
Tutoring Systems
- Enables vision-language capabilities for interactive learning environments.
GLM 4.5V‘s Cost Advantages
High Performance from LLMOCR Test
- Overall Accuracy: 98.7% across 1000 mixed-type documents.
- Specific Strengths:
- Chinese Recognition: 99.3%.
- English Recognition: 98.9%.
- Table Restoration: 97.5%.
- Handwriting Recognition: 96.8%.
- Efficiency: Processes documents in 0.42 seconds/page with a 99.95% API call success rate.
Cost Efficiency
- Average Cost: ¥0.015/page.
- Savings:
- 73% cost reduction compared to GPT-4V.
- 65% cost reduction compared to Claude-3.
Novita AI: More Cost-Effectvely and Stable GLM 4.5V API Provider
Novita AI’s GLM-4.5V API offers 65.5K context, with input priced at $0.60/1K tokens, output at $1.80/1K tokens, and function calling and structured outputs supported.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.

Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Build a Simple Image Recognition Tool using MCP and GLM.
If you want to leverage the capabilities of GLM—such as building a simple image recognition tool to demonstrate its integration of visual recognition and reasoning—you can use the MCP functionality supported by Novita AI. Below is the sample code:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")If you want to get the details, you can check out this article: How to Build Your First MCP Server with Novita AI!
GLM-4.5V outperforms its predecessor GLM-4.1V in every aspect: from its ability to process complex visuals and long documents to cost savings and superior hardware optimization. With its enhanced architecture and extensive application range, it is a game-changer for developers and enterprises seeking an all-in-one AI solution.
What are the key architectural improvements in GLM-4.5V?
GLM-4.5V introduces a Mixture-of-Experts (MoE) architecture with 106B parameters (12B active), 3D RoPE encoding, and 3D convolution for video and GUI recognition, surpassing GLM-4.1V’s dense transformer design.g steps, not just give answers.
How does GLM-4.5V handle multimodal tasks?
GLM-4.5V integrates advanced vision modules for 3D video and GUI recognition, enabling tasks like real-time video OCR, geolocation analysis, and multimodal content generation.
What tasks are better suited for GLM-4.5V compared to GLM-4.1V?
GLM-4.5V excels in document understanding (including handwriting and watermarks), table reconstruction, real-time video OCR, and multimodal content generation, areas where GLM-4.1V was limited.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



