

GLM-4.5VはZhipu AIが開発した最新のオープンソースマルチモーダル大規模言語モデル(LLM)で、言語タスクと視覚タスクを単一の統合システムで処理するように設計されています。これは以前のGLM-4.1Vモデルからの大幅なアップグレードであり、1060億のパラメータを持つ**Mixture-of-Experts(MoE)**アーキテクチャを採用しています(入力ごとに約120億のパラメータがアクティブになります)。
この設計により、GLM-4.5Vは必要な場合にのみ専門的な「エキスパート」サブネットワークをアクティブ化することで、推論コストを抑えつつ優れたパフォーマンスを実現します。このモデルは64kトークンの拡張コンテキストのために**3D Rotatory Positional Encoding(3D-RoPE)**を導入しており、長文書や多次元入力を容易に処理できます。
簡単に言えば、GLM-4.5Vは画像や動画を**「見て」推論することができる**だけでなく、自然な言語対話にも参加できるため、開発者にとって強力なビジョン・言語モデル(VLM)です。
GLM 4.5Vとは?
- 高度な視覚推論
- 基本的なキャプション生成を超えて、複雑な画像、科学図表、比較を理解できます
- 空間推論をサポート:オブジェクトとバウンディングボックスを識別します
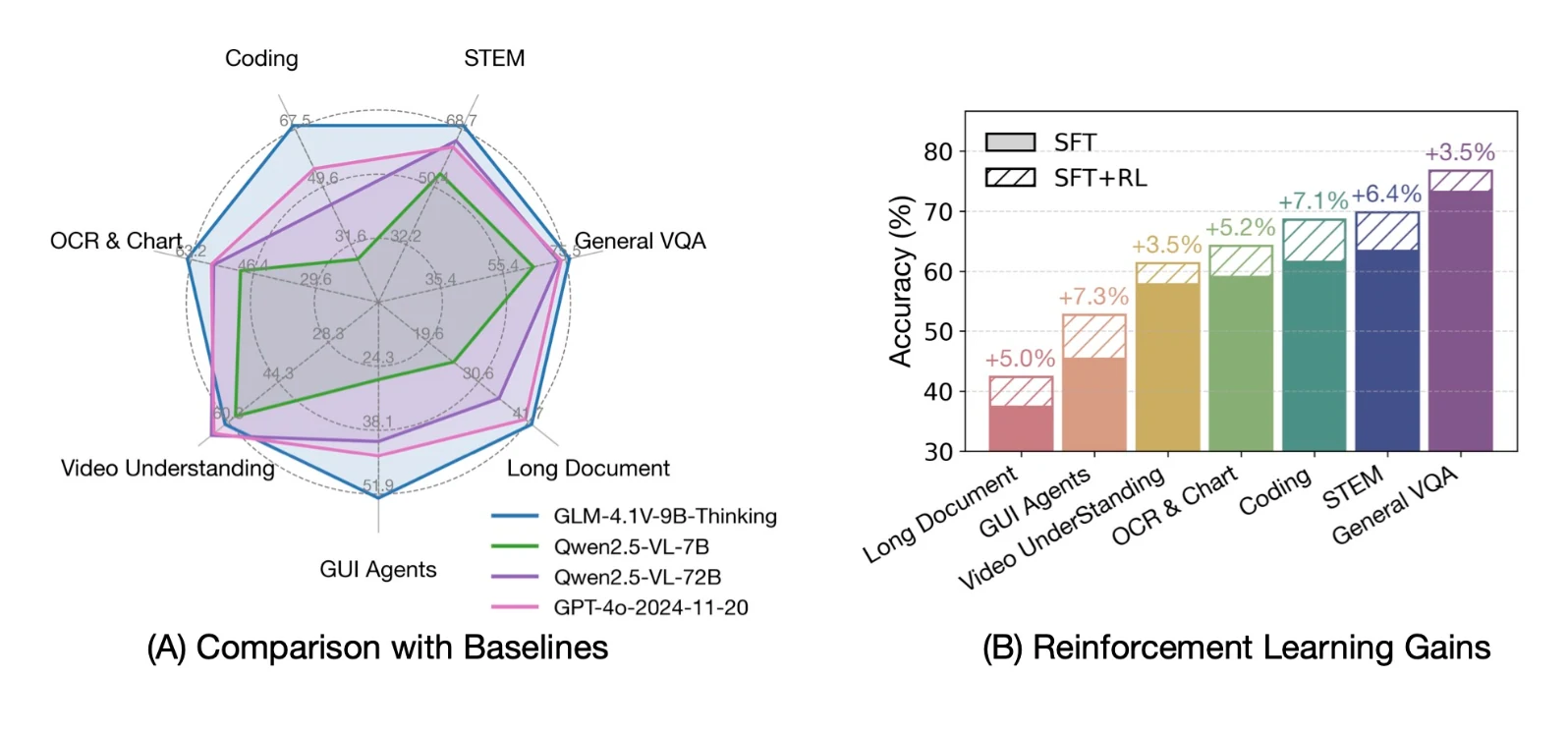
- MMBenchやMMBench+などの視覚QAベンチマークで最高スコアを達成しました
 出典:Hugging Face
出典:Hugging Face
- マルチモーダル入力 + 思考モード
- 会話でテキスト、画像、動画を受け付けます
- 「思考モード」スイッチを提供:最終回答の前にステップバイステップの推論を有効にします
- 論理的な説明を必要とする複雑なタスクに最適です
 出典:Hugging Face
出典:Hugging Face
- 統合ツール利用
- AIエージェントのユースケース向けに設計:外部ツールやAPIを自律的に呼び出せます
- ビルトインで関数呼び出しをサポートし、OpenAIのインターフェースと互換性があります
- ツール利用のためにデモンストレーションベースのトレーニングを採用しています
GLM-4.5Vは、画像理解、ビジュアルQA、ドキュメントOCR、コード生成、GUI自動化をすべて統合インターフェースを通じて処理できる、強力で開発者に優しいマルチモーダルAIモデルです。AIエージェント、生産性ツール、研究などに最適です。
GLM 4.5Vのシステム要件
| 項目 | 詳細 |
|---|---|
| モデルサイズ | 106Bパラメータ(MoE);トークンごとに120億アクティブ |
| VRAM | 640GB |
| ベースラインGPU要件 | 8× NVIDIA H100(各80GB) |
| 精度オプション | FP16、FP8、INT8、INT4量子化形式をサポート |
| 低VRAMセットアップ(最適化済み) | FP8と慎重なパーティショニングを使用することで、2×80GB GPUで可能 |
| 並列処理サポート | テンソル並列とモデル並列をサポート(例:4×40GB GPU) |
| 主要ライブラリ | vLLM、SGLang |
GLM 4.5V APIへのアクセス方法
Novita AIを通じてGLM-4.5Vにアクセスすることで、異なる技術的専門知識レベルやユースケースに合わせた複数の利用方法が提供されます。AI機能を探索するビジネスユーザーでも、本番アプリケーションを構築する開発者でも、Novita AIは必要なツールを提供します。
1. プレイグラウンドを利用する(現在利用可能 - コーディング不要)
- 即時アクセス: サインアップして数秒でGLM-4.5Vモデルの実験を開始できます
- インタラクティブなインターフェース: 複雑な視覚推論プロンプトをテストし、チェーンオブソートの出力をリアルタイムで視覚化できます
- モデル比較: 特定のユースケースに合わせてGLM-4.5Vを他の主要モデルと比較できます
プレイグラウンドを使用すると、画像を直接アップロードしたり、さまざまなプロンプトをテストしたり、技術的なセットアップなしで即座に結果を確認できます。プロトタイピング、アイデアのテスト、完全な実装前にモデルの機能を理解するのに最適です。
2. APIを統合する(本番運用可能 - 開発者向け)
Novita AIの統合REST APIを使用して、GLM-4.5Vをアプリケーションに接続できます。
オプション1:直接API統合(Python例)

from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主な機能:
- シームレスな統合のためのOpenAI互換API
- 応答の微調整のための柔軟なパラメータ制御
- リアルタイム応答のためのストリーミングサポート
オプション2:OpenAI Agents SDKを使用したマルチエージェントワークフロー
GLM-4.5Vを使用して高度なマルチエージェントシステムを構築できます:
- プラグアンドプレイ統合: 任意のOpenAI AgentsワークフローでGLM-4.5Vを使用できます
- 高度なエージェント機能: 優れた視覚推論パフォーマンスで、ハンドオフ、ルーティング、ツール統合をサポート
- スケーラブルなアーキテクチャ: GLM-4.5Vの統合推論、コーディング、視覚分析機能を活用するエージェントを設計できます
3. サードパーティプラットフォームとの連携
開発ツール: Cursor、Trae、Qwen Code、Clineなどの人気IDEや開発環境を、OpenAI互換APIを通じてシームレスに統合できます。
オーケストレーションフレームワーク: LangChain、Dify、CrewAI、LangflowなどのAIオーケストレーションプラットフォームを、公式コネクタを使用して接続できます。
** Hugging Face統合**:Novita AIはHugging Faceの公式推論プロバイダーであり、幅広いエコシステム互換性を確保しています。
GLM 4.5Vコマンドラインインターフェース(CLI)の使用
ローカルでモデルを実行することを好む開発者や、環境により多くの制御を望む開発者向けに、GLM-4.5Vはコマンドラインインターフェース(CLI)でも使用できます。Zhipu AIはモデルの重みをオープンソース化し、独自のハードウェアでモデルを実行するためのツールを提供しています。
このモデルはHugging Face Hubでzai-org/GLM-4.5Vとして公開されています。モデルをダウンロードし、Transformersライブラリを使用して出力を生成できます。例えば、PythonスクリプトやJupyterノートブックで:
python3 inference/trans_infer_cli.py --model-path zai-org/GLM-4.5V --image test.jpg --question "这张图里有什么?"
| 機能 | CLI | API |
|---|---|---|
| 利用方法 | ターミナルでコマンドとパラメータを入力 | コード内でライブラリ/HTTPリクエストを呼び出し |
| 出力 | ターミナルに直接印刷 | オブジェクト/JSONを返却、後続処理が容易 |
| 最適な用途 | モデルのテスト、クイック推論、小規模スクリプト | アプリケーション開発、サービス統合、大規模呼び出し |
| 柔軟性 | パラメータが固定されており、組み合わせが限定的 | 完全にプログラム可能で、複雑なロジックをサポート |
| 依存関係 | スクリプト/CLIツールのみ必要 | コードの作成と依存関係の管理が必要 |
MCPとGLM4.5Vを使用したシンプルな画像認識ツールの構築
GLMの機能を活用したい場合(例えば、視覚認識と推論の統合を示すシンプルな画像認識ツールを構築する場合)、Novita AIがサポートするMCP機能を使用できます。以下にサンプルコードを示します:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
GLM 4.5Vの一般的なトラブルシューティング
1. メモリと読み込みエラー(CUDA OOM) 原因: モデルが大きすぎて、利用可能なGPUメモリに収まりません。 解決策:
- 推論バックエンドを使用する
- 例:SGLangで
--attention-backend fa3を有効にしてメモリ使用量を削減します。
- 例:SGLangで
- テンソル並列サイズを小さくしてより多くのGPUを使用する
- 例:TP=4の代わりにTP=8(8基のGPU)を設定して、GPUごとのモデルチャンクを小さく割り当てます。
- 量子化モデルを読み込む(8ビットまたは4ビット)
- 例:HuggingFace Transformersを使用する場合は
load_in_8bit=Trueを指定します。
- 例:HuggingFace Transformersを使用する場合は
- より高いVRAMを搭載したクラウドインスタンスを選択する
- 例:A100(80GB)またはH200(141GB);H200は単一のGPUでモデルを実行できる場合があります。
- 長い入力を小さなチャンクに分割して処理する
- 長い動画を短いセグメントに分割するか、思考モードを無効にして出力サイズを削減します。
2. 画像入力が認識されない 原因: 画像がモデルに正しくフォーマットまたは渡されていません。 解決策:
- OpenAIスタイルのAPIの場合、入力を特別なメッセージとして構成します
- 例:
[{"type": "image_url", "image_url": {"url": "<URL>"}}, {"type": "text", "text": "your question"}]
- 例:
- HuggingFace Transformersを使用する場合は、
AutoProcessorを使用します- 例:推論の前に
processor(images=[...], text=[...])を呼び出します。
- 例:推論の前に
- 画像URLが公開されていることを確認するか、サポートされている場合はbase64エンコーディングを使用します
- モデルが画像を無視したり、画像を受信していないと返したりする場合は、入力が無効である可能性があります。
4. 異常な出力フォーマット 問題:
- 出力に生のHTML(例:
<div>...</div>)が含まれる - 予期しないエスケープ文字(例:
<)が含まれる - 回答が繰り返されたり、追記されたりする
解決策:
- モデルにMarkdownでコードをフォーマットするように指示します(例:トリプルバッククォートを使用)
- HTMLエスケープを修正するパッチを適用します(公式リポジトリで利用可能)
- 不要な場合は思考モードを無効にします
- 重複したコンテンツを削除するために出力を後処理します
5. ツール利用のアーティファクト
問題: モデルがツール関連のコマンド(例:<|search|>)を出力します。
解決策:
エージェントエンドポイントの代わりに標準のチャット補完APIを使用し、ツール利用シナリオを模倣するようなプロンプトを避けてください。
6. 精度の制限 既知の制限:
- カウントや顔認識などの細かい視覚タスクには苦労する場合があります
- テキストのみの質問は、専門的なテキストモデルで回答した方が良い場合があります
- 非常に長いドキュメントや動画では低速で、タイムアウトが発生する場合があります
推奨事項:
- 長い入力にはストリーミングモードを使用して部分的な出力を受信します
- 大きな入力を小さなセグメントに分割します
- APIプロバイダーの実際のコンテキスト長の制限を確認してください
GLM-4.5Vはビジョン・言語AIのゲームチェンジャーであり、これまでプロプライエタリモデルの領域にあった機能をオープンソースおよびセルフホストの世界にもたらします。ここでは、GLM-4.5Vとは何か、その特徴、実行に必要なセットアップ、一般的な問題のトラブルシューティング方法、クラウドAPIやローカルCLIによる複数のアクセス方法について説明しました。この知識をもとに、開発者は自信を持ってプロジェクトにGLM-4.5Vを組み込むことができます。
Gemma 3 27BからGLM 4.5Vにアップグレードすべきですか? GLM-4.5VはZhipu AIの最新のオープンソースマルチモーダル大規模言語モデルです。テキスト、画像、動画を処理でき、高度な推論機能を備えています。
GLM-4.5Vにはどのような機能がありますか? 高度な視覚推論(科学図表、空間推論、ビジュアルQAなど)、長文書理解、コード生成、OCR、GUI自動化、マルチモーダル対話をサポートしています。
GLM-4.5Vは以前のモデルとどのように異なりますか? GLM-4.1Vを改良し、106Bパラメータ(入力ごとに120億アクティブ)のMixture-of-Experts(MoE)アーキテクチャを採用するとともに、64kコンテキスト長のための3D-RoPEを搭載しているため、低コストで高いパフォーマンスを実現します。
Novita AIは、あなたのAIの野望を実現するオールインワンクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス——必要なコスト効率の良いツールを提供します。インフラの管理を不要にし、無料で始めて、あなたのAIビジョンを実現しましょう。



