

GLM-4.5V هو أحدث نموذج لغوي كبير متعدد الوسائط مفتوح المصدر (LLM) من Zhipu AI، مصمم للتعامل مع مهام اللغة والرؤية في نظام موحد واحد. يمثل هذا ترقية كبيرة عن نموذج GLM-4.1V السابق، ويتميز بهندسة Mixture-of-Experts (MoE) مع 106 مليار معامل (حوالي 12 مليار معامل نشط لكل إدخال).
يتيح هذا التصميم لـ GLM-4.5V تحقيق أداء متفوق بتكلفة استدلال أقل من خلال تفعيل شبكات فرعية متخصصة “خبيرة” فقط عند الحاجة. يقدم النموذج 3D Rotatory Positional Encoding (3D-RoPE) لسياق رمزي ممتد يصل إلى 64k رمز، مما يمكنه من التعامل مع المستندات الطويلة والمدخلات متعددة الأبعاد بسهولة.
بشكل أبسط، يمكن لـ GLM-4.5V “رؤية” والاستدلال حول الصور والفيديوهات أثناء المشاركة في حوارات لغة طبيعية، مما يجعله نموذج لغة رؤية (VLM) قوي للمطورين.
ما هو GLM 4.5V؟
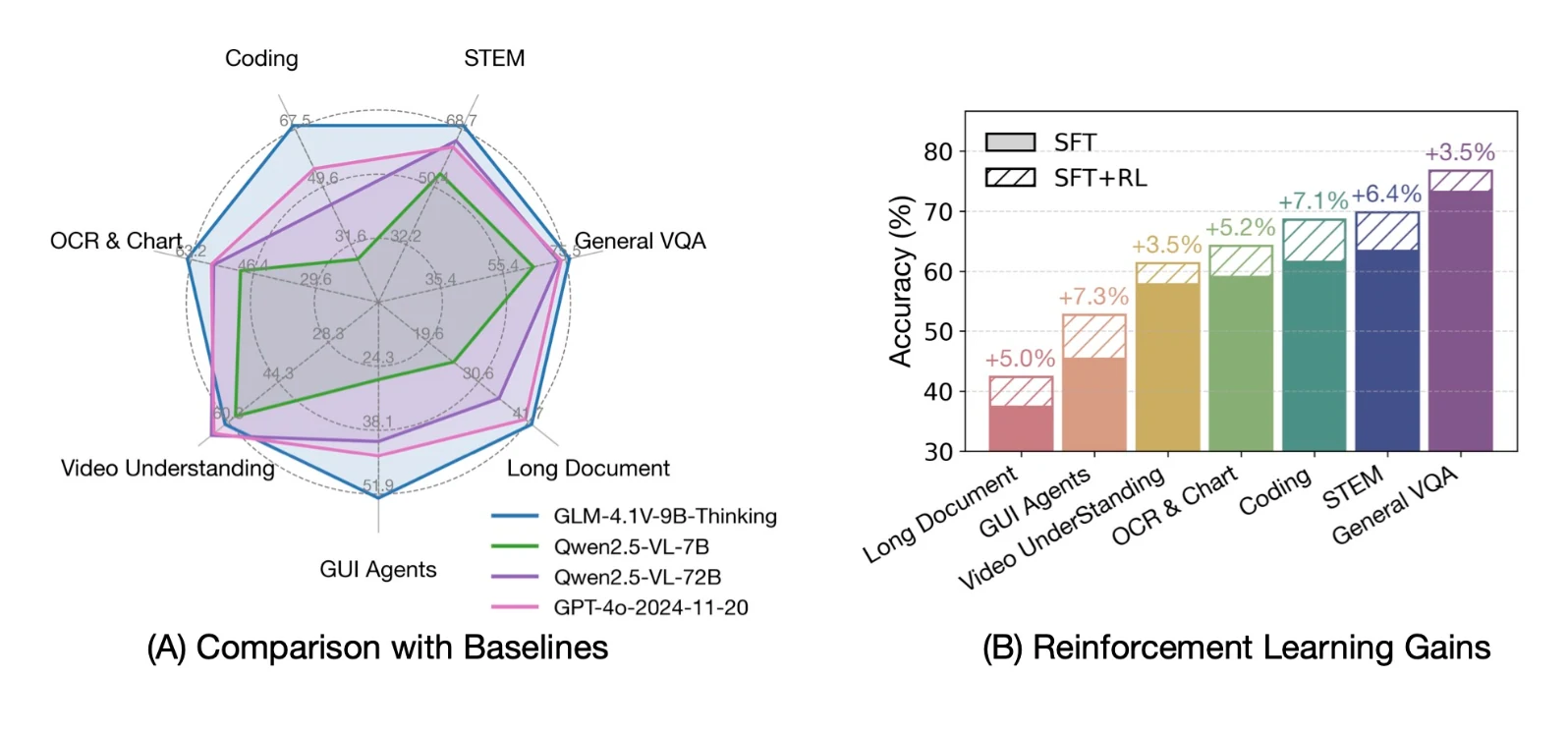
1. الاستدلال البصري المتقدم
- يتجاوز التسميات التوضيحية الأساسية — يفهم الصور المعقدة، المخططات العلمية، والمقارنات
- يدعم الاستدلال المكاني: يحدد الكائنات ومربعات الإحاطة
- حقق أعلى الدرجات في معايير الاستجابة البصرية للأسئلة مثل MMBench & MMBench+
من Hugging Face
2. إدخال متعدد الوسائط + وضع التفكير
- يقبل النصوص، الصور، والفيديوهات في المحادثات
- يقدم مفتاح “وضع التفكير”: يتيح استدلالًا خطوة بخطوة قبل الإجابة النهائية
- مثالي للمهام المعقدة التي تتطلب تفسيرات منطقية
من Hugging Face
3. استخدام الأدوات الموحد
- مصمم لحالات استخدام وكلاء الذكاء الاصطناعي — يمكنه استدعاء أدوات أو واجهات برمجة تطبيقات خارجية بشكل مستقل
- يدعم مدمجًا استدعاء الدوال، متوافق مع واجهة OpenAI
- يستخدم تدريبًا قائمًا على العروض التوضيحية لاستخدام الأدوات
GLM-4.5V هو نموذج ذكاء اصطناعي متعدد الوسائط قوي وصديق للمطورين، قادر على التعامل مع فهم الصور، الاستجابة البصرية للأسئلة، التعرف الضوئي على الحروف (OCR) للمستندات، توليد الأكواد، وأتمتة واجهة المستخدم الرسومية — كل ذلك من خلال واجهة موحدة. إنه مثالي لوكلاء الذكاء الاصطناعي، أدوات الإنتاجية، البحث، والمزيد.
متطلبات نظام GLM 4.5V
| الجانب | التفاصيل |
|---|---|
| حجم النموذج | 106 مليار معامل (MoE)؛ 12 مليار معامل نشط لكل رمز |
| ذاكرة الوصول العشوائي للفيديو (VRAM) | 640 جيجابايت |
| احتياج أساسي لوحدة معالجة الرسوميات (GPU) | 8 × NVIDIA H100 (80 جيجابايت لكل منها) |
| خيارات الدقة | يدعم تنسيقات التكميم FP16، FP8، INT8، INT4 |
| إعداد منخفض الذاكرة العشوائية للفيديو (مُحسَّن) | ممكن باستخدام وحدتي معالجة رسوميات 80 جيجابايت باستخدام FP8 وتقسيم دقيق |
| دعم التفرع | يدعم التفرع الشامل ونموذج التفرع (مثال: 4 وحدات معالجة رسوميات 40 جيجابايت) |
| المكتبات الأساسية | vLLM، SGLang |
كيفية الوصول إلى واجهة برمجة تطبيقات GLM 4.5V
ccessing GLM-4.5V عبر Novita AI يوفر مسارات متعددة مصممة لمستويات خبرة تقنية مختلفة وحالات استخدام مختلفة. سواء كنت مستخدمًا تجاريًا يستكشف إمكانيات الذكاء الاصطناعي أو مطورًا يبني تطبيقات إنتاجية، فإن Novita AI يوفر الأدوات التي تحتاجها.
1. استخدم مساحة التجربة (متاح الآن - لا يتطلب برمجة)
- وصول فوري: سجل وابدأ التجربة مع نماذج GLM-4.5V في ثوانٍ
- واجهة تفاعلية: اختبر مطالبات الاستدلال البصري المعقدة واعرض مخرجات سلسلة التفكير في الوقت الفعلي
- مقارنة النماذج: قارن بين GLM-4.5V والنماذج الرائدة الأخرى لحالة الاستخدام الخاصة بك
تتيح لك مساحة التجربة رفع الصور مباشرة، واختبار مختلف المطالبات، ورؤية النتائج الفورية دون أي إعداد تقني. مثالية للنماذج الأولية، واختبار الأفكار، وفهم إمكانات النموذج قبل التنفيذ الكامل.
2. التكامل عبر واجهة برمجة التطبيقات (مباشر وجاهز - للمطورين)
اربط GLM-4.5V بتطبيقاتك باستخدام واجهة برمجة التطبيقات REST الموحدة من Novita AI.
الخيار 1: التكامل المباشر عبر واجهة برمجة التطبيقات (مثال بلغة بايثون)

from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
الميزات الرئيسية:
- واجهة برمجة تطبيقات متوافقة مع OpenAI للتكامل السلس
- تحكم مرن في المعلمات لضبط الاستجابات بدقة
- دعم البث للاستجابات في الوقت الفعلي
الخيار 2: سير عمل متعدد الوكلاء باستخدام حزمة SDK لوكلاء OpenAI
ابنِ أنظمة متعددة الوكلاء متطورة باستخدام GLM-4.5V:
- تكامل Plug-and-Play: استخدم GLM-4.5V في أي سير عمل لوكلاء OpenAI
- إمكانيات الوكلاء المتقدمة: دعم التسليم، التوجيه، وتكامل الأدوات مع أداء استدلال بصري متفوق
- بنية قابلة للتطوير: صمم وكلاء يستفيدون من إمكانات GLM-4.5V في الاستدلال الموحد، البرمجة، والتحليل البصري
3. الاتصال بمنصات طرف ثالث
أدوات التطوير: تكامل سلس مع بيئات التطوير المتكاملة (IDEs) الشائعة وبيئات التطوير مثل Cursor و Trae و Qwen Code و Cline عبر واجهات برمجة تطبيقات متوافقة مع OpenAI.
أطر التنسيق: اتصل بـ LangChain و Dify و CrewAI و Langflow ومنصات تنسيق الذكاء الاصطناعي الأخرى باستخدام موصلات رسمية.
**تكامل مع Hugging Face: تعمل Novita AI كموفر استدلال رسمي لـ Hugging Face، مما يضمن توافقًا واسعًا مع النظام البيئي.
استخدام واجهة سطر أوامر GLM 4.5V (CLI)
للمطورين الذين يفضلون تشغيل النماذج محليًا أو يريدون مزيدًا من التحكم في البيئة، يمكن استخدام GLM-4.5V أيضًا عبر واجهة سطر الأوامر. قامت Zhipu AI بفتح مصدر أوزان النموذج وقدمت أدوات لتشغيل النموذج على الأجهزة الخاصة بك.
النموذج متاح على منصة Hugging Face Hub باسم zai-org/GLM-4.5V. يمكنك تنزيل النموذج ثم استخدام مكتبة Transformers لتوليد المخرجات. على سبيل المثال، في نص برمجي بلغة بايثون أو دفتر Jupyter:
python3 inference/trans_infer_cli.py --model-path zai-org/GLM-4.5V --image test.jpg --question "这张图里有什么?"
| الميزة | واجهة سطر الأوامر | واجهة برمجة التطبيقات |
|---|---|---|
| الاستخدام | إدخال الأوامر + المعلمات في الطرفية | استدعاء المكتبات/طلبات HTTP في الكود |
| المخرجات | مطبوعة مباشرة في الطرفية | تُرجع كائنات/JSON، يسهل معالجتها لاحقًا |
| الأفضل لـ | اختبار النماذج، الاستدلال السريع، النصوص البرمجية الصغيرة | تطوير التطبيقات، تكامل الخدمات، المكالمات واسعة النطاق |
| المرونة | معلمات ثابتة، مجموعات محدودة | قابل للبرمجة بالكامل، يدعم المنطق المعقد |
| التبعيات | تحتاج فقط إلى نص برمجي/أداة واجهة سطر أوامر | تتطلب كتابة الكود وإدارة التبعيات |
بناء أداة تعرف بسيطة على الصور باستخدام MCP و GLM4.5V
إذا كنت تريد الاستفادة من إمكانات GLM — مثل بناء أداة تعرف بسيطة على الصور لإظهار تكاملها للتعرف البصري والاستدلال — يمكنك استخدام وظيفة MCP المدعومة من Novita AI. أدناه نموذج الكود:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
استكشاف أخطاء GLM 4.5V الشائعة وإصلاحها
1. أخطاء الذاكرة والتحميل (CUDA OOM) السبب: النموذج كبير جدًا ليتناسب مع ذاكرة وحدة معالجة الرسوميات المتاحة.
الحلول:
- استخدم خلفية الاستدلال الموصى بها
- مثال: فعِّل
--attention-backend fa3في SGLang لتقليل استخدام الذاكرة.
- مثال: فعِّل
- استخدم المزيد من وحدات معالجة الرسوميات مع حجم تفرع شامل أصغر
- مثال: اضبط TP=8 (8 وحدات معالجة رسوميات) بدلاً من TP=4 لتخصيص أجزاء نموذج أصغر لكل وحدة معالجة رسوميات.
- حمِّل نموذجًا مكمَّمًا (8 بت أو 4 بت)
- على سبيل المثال، استخدم
load_in_8bit=Trueعند استخدام مكتبة Transformers من HuggingFace.
- على سبيل المثال، استخدم
- اختر مثيلات سحابية بذاكرة وصول عشوائي للفيديو (VRAM) أعلى
- مثال: A100 (80 جيجابايت) أو H200 (141 جيجابايت)؛ قد يعمل H200 على تشغيل النموذج على وحدة معالجة رسوميات واحدة.
- عالج المدخلات الطويلة في أجزاء أصغر
- قسِّم الفيديوهات الطويلة إلى مقاطع أقصر أو عطِّل وضع التفكير لتقليل حجم المخرجات.
2. إدخال الصور غير معترف به السبب: الصورة غير منسقة أو لم يتم تمريرها بشكل صحيح إلى النموذج.
الحلول:
- لواجهات برمجة التطبيقات بنمط OpenAI، قم بهيكلة الإدخال كرسالة خاصة
- مثال:
[{"type": "image_url", "image_url": {"url": "<URL>"}}, {"type": "text", "text": "your question"}]
- مثال:
- عند استخدام مكتبة Transformers من HuggingFace، استخدم
AutoProcessor- مثال: استدعِ
processor(images=[...], text=[...])قبل الاستدلال.
- مثال: استدعِ
- تأكد من أن عنوان URL للصورة عام أو استخدم ترميز base64 إذا كان مدعومًا
- إذا تجاهل النموذج الصورة أو قال إنه لم يتلقها، فقد يكون الإدخال غير صالح.
4. تنسيق مخرجات غريب المشاكل:
- تتضمن المخرجات HTML خام (مثال:
<div>...</div>) - أحرف هروب غير متوقعة (مثال:
<) - إجابات متكررة أو مضافة لاحقًا
الحلول:
- اطلب من النموذج تنسيق الأكواد بتنسيق Markdown (مثال: استخدام علامات الاقتباس الثلاثية)
- طبق التصحيحات لإصلاح هروب HTML (متوفرة في المستودعات الرسمية)
- عطِّل وضع التفكير إذا لم تكن بحاجة إليه
- عالج المخرجات لاحقًا لإزالة المحتوى المكرر
5. عناصر أداة الاستخدام
المشكلة: النموذج يخرج أوامر متعلقة بالأدوات (مثال: <|search|>).
الحل:
استخدم واجهة برمجة تطبيقات إكمال المحادثة القياسية بدلاً من نقاط نهاية الوكلاء، وتجنب المطالبات التي تحاكي سيناريوهات استخدام الأدوات.
6. قيود الدقة القيود المعروفة:
- قد يعاني من صعوبة في المهام البصرية الدقيقة مثل العد أو التعرف على الوجوه
- قد تتم الإجابة على الأسئلة النصية فقط بشكل أفضل بواسطة نماذج نصية متخصصة
- بطيء مع المستندات أو الفيديوهات الطويلة جدًا؛ قد يتعرض لانتهاء المهلة
التوصيات:
- استخدم وضع البث للمدخلات الطويلة لتلقي مخرجات جزئية
- قسِّم المدخلات الكبيرة إلى مقاطع أصغر
- تحقق من حدود طول السياق الفعلية لموفر واجهة برمجة التطبيقات الخاص بك
GLM-4.5V هو مغير قواعد اللعبة للذكاء الاصطناعي للغة الرؤية، حيث يجلب إمكانات كانت سابقًا في مجال النماذج المملوكة إلى عالم المصدر المفتوح والاستضافة الذاتية. لقد غطينا ما هو GLM-4.5V ولماذا هو مميز، الإعداد الذي تحتاجه لتشغيله، كيفية استكشاف الأخطاء الشائعة وإصلاحها، وطرق متعددة للوصول إليه (واجهة برمجة تطبيقات سحابية أو واجهة سطر أوامر محلية). بهذه المعرفة، يمكن للمطورين دمج GLM-4.5V في مشاريعهم بثقة.
هل يجب أن أترقي من Gemma 3 27B إلى GLM 4.5V؟
GLM-4.5V هو أحدث نموذج لغوي كبير متعدد الوسائط مفتوح المصدر من Zhipu AI. يمكنه التعامل مع مهام اللغة والرؤية، بما في ذلك النصوص والصور والفيديوهات، مع إمكانيات استدلال متقدمة.
ماذا يمكن لـ GLM-4.5V أن يفعل؟
يدعم الاستدلال البصري المتقدم (مثال: المخططات العلمية، الاستدلال المكاني، الاستجابة البصرية للأسئلة)، فهم المستندات الطويلة، توليد الأكواد، التعرف الضوئي على الحروف (OCR)، أتمتة واجهة المستخدم الرسومية، والحوار متعدد الوسائط.
كيف يختلف GLM-4.5V عن النماذج السابقة؟
يحسّن عن GLM-4.1V باستخدام هندسة Mixture-of-Experts (MoE) مع 106 مليار معامل (12 مليار معامل نشط لكل إدخال)، بالإضافة إلى 3D-RoPE لطول سياق يصل إلى 64k رمز، مما يتيح تكلفة أقل وأداء أقوى.
Novita AI هي منصة سحابية شاملة تمكّنك من تحقيق طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خوادم، مثيلات لوحدة معالجة الرسوميات — الأدوات فعالة التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



