

GLM-4.5V es el último modelo de lenguaje grande multimodal de código abierto (LLM) de Zhipu AI, diseñado para gestionar tanto tareas de lenguaje como de visión en un sistema unificado. Representa una actualización importante del modelo anterior GLM-4.1V, y cuenta con una arquitectura de Mezcla de Expertos (MoE) con 106 mil millones de parámetros (aproximadamente 12B activos por entrada).
Este diseño permite que GLM-4.5V logre un rendimiento superior a un costo de inferencia menor, al activar solo las subredes de “expertos” especializadas según sea necesario. El modelo introduce la Codificación Posicional Rotatoria 3D (3D-RoPE) para un contexto de tokens extendido de 64k, lo que le permite manejar documentos largos y entradas multidimensionales con facilidad.
En términos más sencillos, GLM-4.5V puede “ver” y razonar sobre imágenes y vídeos mientras participa en diálogos en lenguaje natural, lo que lo convierte en un potente modelo de lenguaje y visión (VLM) para desarrolladores.
¿Qué es GLM 4.5V?
1. Razonamiento visual avanzado
- Va más allá de las descripciones básicas: comprende imágenes complejas, diagramas científicos y comparaciones
- Soporta razonamiento espacial: identifica objetos y cuadros delimitadores
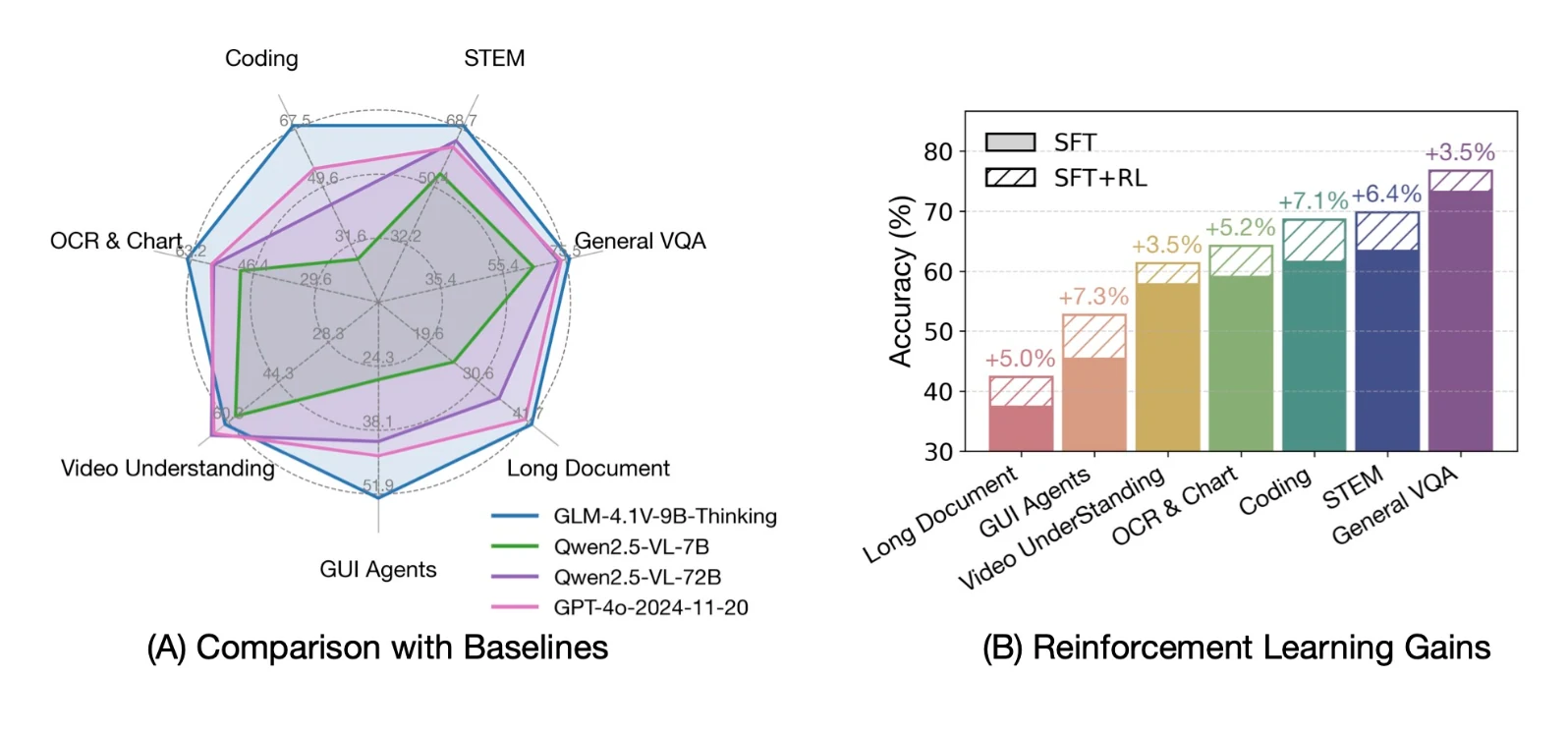
- Logró las puntuaciones más altas en benchmarks de respuesta visual como MMBench y MMBench+
De Hugging Face
2. Entrada multimodal + Modo de pensamiento
- Acepta texto, imágenes y vídeos en las conversaciones
- Ofrece un interruptor de “Modo de pensamiento”: permite el razonamiento paso a paso antes de la respuesta final
- Ideal para tareas complejas que requieren explicaciones lógicas
De Hugging Face
3. Uso unificado de herramientas
- Diseñado para casos de uso de agentes de IA: puede llamar de forma autónoma a herramientas o API externas
- Soporte integrado para llamada de funciones, compatible con la interfaz de OpenAI
- Utiliza entrenamiento basado en demostraciones para el uso de herramientas
GLM-4.5V es un modelo de IA multimodal potente y fácil de usar para desarrolladores, capaz de gestionar comprensión de imágenes, respuesta visual (Visual QA), OCR de documentos, generación de código y automatización de interfaces gráficas, todo a través de una interfaz unificada. Es ideal para agentes de IA, herramientas de productividad, investigación y mucho más.
Requisitos del sistema de GLM 4.5V
| Aspecto | Detalles |
|---|---|
| Tamaño del modelo | 106B de parámetros (MoE); 12B activos por token |
| VRAM | 640GB |
| Necesidad mínima de GPU | 8× NVIDIA H100 (80GB cada una) |
| Opciones de precisión | Soporta formatos de cuantización FP16, FP8, INT8, INT4 |
| Configuración de VRAM baja (optimizada) | Posible con 2 GPUs de 80GB usando FP8 y particionamiento cuidadoso |
| Soporte de paralelismo | Soporta paralelismo de tensores y de modelo (por ejemplo, 4 GPUs de 40GB) |
| Bibliotecas clave | vLLM, SGLang |
Cómo acceder a la API de GLM 4.5V
Acceder a GLM-4.5V a través de Novita AI ofrece múltiples vías adaptadas a diferentes niveles de experiencia técnica y casos de uso. Tanto si eres un usuario empresarial que explora las capacidades de la IA como un desarrollador que crea aplicaciones de producción, Novita AI te proporciona las herramientas que necesitas.
1. Usar el patio de juegos (Playground) (Disponible ahora - No requiere codificación)
- Acceso instantáneo: Regístrate y empieza a experimentar con los modelos GLM-4.5V en segundos
- Interfaz interactiva: Prueba prompts de razonamiento visual complejos y visualiza las salidas de cadena de pensamiento en tiempo real
- Comparación de modelos: Compara GLM-4.5V con otros modelos líderes para tu caso de uso específico
El patio de juegos te permite subir imágenes directamente, probar varios prompts y ver resultados inmediatos sin ninguna configuración técnica. Perfecto para prototipado, prueba de ideas y comprensión de las capacidades del modelo antes de la implementación completa.
2. Integración vía API (En vivo y lista - Para desarrolladores)
Conecta GLM-4.5V a tus aplicaciones con la API REST unificada de Novita AI.
Opción 1: Integración directa de API (ejemplo en Python)

from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Características clave:
- API compatible con OpenAI para una integración perfecta
- Control flexible de parámetros para ajustar las respuestas
- Soporte de streaming para respuestas en tiempo real
Opción 2: Flujos de trabajo multiagente con OpenAI Agents SDK
Crea sistemas multiagente sofisticados usando GLM-4.5V:
- Integración lista para usar: Usa GLM-4.5V en cualquier flujo de trabajo de OpenAI Agents
- Capacidades avanzadas de agente: Soporte para transferencias, enrutamiento e integración de herramientas con un rendimiento superior en razonamiento visual
- Arquitectura escalable: Diseña agentes que aprovechen las capacidades unificadas de razonamiento, codificación y análisis visual de GLM-4.5V
3. Conéctate con plataformas de terceros
Herramientas de desarrollo: Integración perfecta con IDE y entornos de desarrollo populares como Cursor, Trae, Qwen Code y Cline a través de API compatibles con OpenAI.
Frameworks de orquestación: Conéctate con LangChain, Dify, CrewAI, Langflow y otras plataformas de orquestación de IA usando conectores oficiales.
****Integración con Hugging Face**: Novita AI es un proveedor de inferencia oficial de Hugging Face, lo que garantiza una compatibilidad amplia con el ecosistema.
Uso de la interfaz de línea de comandos (CLI) de GLM 4.5V
Para los desarrolladores que prefieren ejecutar modelos de forma local o quieren tener más control sobre el entorno, GLM-4.5V también se puede usar mediante una interfaz de línea de comandos. Zhipu AI ha publicado los pesos del modelo como código abierto y proporciona herramientas para ejecutar el modelo en tu propio hardware.
El modelo está disponible en el Hub de Hugging Face como zai-org/GLM-4.5V. Puedes descargar el modelo y luego usar la biblioteca Transformers para generar salidas. Por ejemplo, en un script de Python o un cuaderno Jupyter:
python3 inference/trans_infer_cli.py --model-path zai-org/GLM-4.5V --image test.jpg --question "这张图里有什么?"
| Característica | CLI | API |
|---|---|---|
| Uso | Introduce comandos y parámetros en la terminal | Llama a bibliotecas o solicitudes HTTP en código |
| Salida | Se imprime directamente en la terminal | Devuelve objetos o JSON, fácil de procesar posteriormente |
| Ideal para | Prueba de modelos, inferencia rápida, scripts pequeños | Desarrollo de aplicaciones, integración de servicios, llamadas a gran escala |
| Flexibilidad | Parámetros fijos, combinaciones limitadas | Totalmente programable, soporta lógica compleja |
| Dependencias | Solo necesitas un script o herramienta CLI | Requiere escribir código y gestionar dependencias |
Crea una herramienta sencilla de reconocimiento de imágenes usando MCP y GLM4.5V
Si quieres aprovechar las capacidades de GLM, como crear una herramienta sencilla de reconocimiento de imágenes para demostrar su integración de reconocimiento visual y razonamiento, puedes usar la funcionalidad MCP soportada por Novita AI. A continuación tienes el código de ejemplo:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Solución de problemas comunes de GLM 4.5V
1. Errores de memoria y carga (CUDA OOM)
Causa: El modelo es demasiado grande para caber en la memoria GPU disponible.
Soluciones:
- Usa el backend de inferencia recomendado
- Ejemplo: Habilita
--attention-backend fa3en SGLang para reducir el uso de memoria.
- Ejemplo: Habilita
- Usa más GPUs con un tamaño de paralelismo de tensores menor
- Ejemplo: Establece TP=8 (8 GPUs) en lugar de TP=4 para asignar fragmentos de modelo más pequeños por GPU.
- Carga un modelo cuantizado (8 bits o 4 bits)
- Por ejemplo, usa
load_in_8bit=Trueal usar HuggingFace Transformers.
- Por ejemplo, usa
- Elige instancias en la nube con mayor VRAM
- Ejemplo: A100 (80GB) o H200 (141GB); la H200 puede ejecutar el modelo en una sola GPU.
- Procesa entradas largas en fragmentos más pequeños
- Divide vídeos largos en segmentos más cortos o desactiva el modo de pensamiento para reducir el tamaño de la salida.
2. Entrada de imagen no reconocida
Causa: La imagen no está formateada o pasada correctamente al modelo.
Soluciones:
- Para API de estilo OpenAI, estructura la entrada como un mensaje especial
- Ejemplo:
[{"type": "image_url", "image_url": {"url": "<URL>"}}, {"type": "text", "text": "tu pregunta"}]
- Ejemplo:
- Al usar HuggingFace Transformers, usa
AutoProcessor- Ejemplo: Llama a
processor(images=[...], text=[...])antes de la inferencia.
- Ejemplo: Llama a
- Asegúrate de que la URL de la imagen sea pública o usa codificación base64 si es compatible
- Si el modelo ignora la imagen o dice que no la recibió, la entrada puede no ser válida.
4. Formato de salida extraño
Problemas:
- Las salidas incluyen HTML sin procesar (por ejemplo,
<div>...</div>) - Caracteres de escape inesperados (por ejemplo,
<) - Respuestas repetidas o añadidas
Soluciones:
- Indica al modelo que formatee el código en Markdown (por ejemplo, usa triples comillas invertidas)
- Aplica parches para corregir el escape de HTML (disponibles en los repositorios oficiales)
- Desactiva el modo de pensamiento si no es necesario
- Procesa la salida posteriormente para eliminar contenido duplicado
5. Artefactos de uso de herramientas
Problema: El modelo genera comandos relacionados con herramientas (por ejemplo, <|search|>).
Solución:
Usa la API de finalización de chat estándar en lugar de endpoints de agente, y evita prompts que imiten escenarios de uso de herramientas.
6. Limitaciones de precisión
Limitaciones conocidas:
- Puede tener dificultades con tareas visuales de grano fino como contar o reconocimiento facial
- Las preguntas solo de texto pueden responderse mejor con modelos de texto especializados
- Es lento con documentos o vídeos muy largos; puede sufrir tiempos de espera
Recomendaciones:
- Usa el modo de streaming para entradas largas para recibir salidas parciales
- Divide entradas grandes en segmentos más pequeños
- Comprueba los límites reales de longitud de contexto de tu proveedor de API
GLM-4.5V es un cambio de juego para la IA de lenguaje y visión, llevando capacidades que antes pertenecían al ámbito de los modelos propietarios al mundo del código abierto y el alojamiento propio. Hemos cubierto qué es GLM-4.5V y por qué es especial, la configuración que necesitas para ejecutarlo, cómo solucionar problemas comunes y múltiples formas de acceder a él (API en la nube o CLI local). Con estos conocimientos, los desarrolladores pueden incorporar GLM-4.5V en sus proyectos con confianza.
¿Debo actualizar de Gemma 3 27B a GLM 4.5V?
GLM-4.5V es el último modelo de lenguaje grande multimodal de código abierto de Zhipu AI. Puede gestionar tanto tareas de lenguaje como de visión, incluyendo texto, imágenes y vídeos, con capacidades avanzadas de razonamiento.
¿Qué puede hacer GLM-4.5V?
Soporta razonamiento visual avanzado (por ejemplo, diagramas científicos, razonamiento espacial, respuesta visual), comprensión de documentos largos, generación de código, OCR, automatización de interfaces gráficas y diálogo multimodal.
¿En qué se diferencia GLM-4.5V de modelos anteriores?
Mejora GLM-4.1V al usar una arquitectura de Mezcla de Expertos (MoE) con 106B de parámetros (12B activos por entrada), además de 3D-RoPE para una longitud de contexto de 64k, lo que permite un menor costo y un rendimiento más fuerte.
Novita AI es la plataforma en la nube todo en uno que impulsa tus ambiciones en IA. APIs integradas, sin servidor, instancias GPU: las herramientas económicas que necesitas. Elimina la infraestructura, empieza gratis y haz realidad tu visión de la IA.



