

GLM-4.5V est le dernier modèle de langage multimodal open source (LLM) de Zhipu AI, conçu pour traiter à la fois des tâches de langage et de vision dans un système unifié. Il représente une mise à niveau majeure par rapport au modèle GLM-4.1V précédent, intégrant une architecture Mixture-of-Experts (MoE) avec 106 milliards de paramètres (environ 12B actifs par entrée).
Cette conception permet à GLM-4.5V d’atteindre des performances supérieures à un coût d’inférence plus faible en activant uniquement les sous-réseaux « experts » spécialisés selon les besoins. Le modèle introduit un encodage positionnel rotatif 3D (3D-RoPE) pour un contexte de jetons étendu à 64k, lui permettant de traiter facilement des documents longs et des entrées multidimensionnelles.
En termes plus simples, GLM-4.5V peut « voir » et raisonner sur des images et des vidéos tout en participant à des dialogues en langage naturel, ce qui en fait un modèle de langage visuel (VLM) puissant pour les développeurs.
Qu’est-ce que GLM 4.5V ?
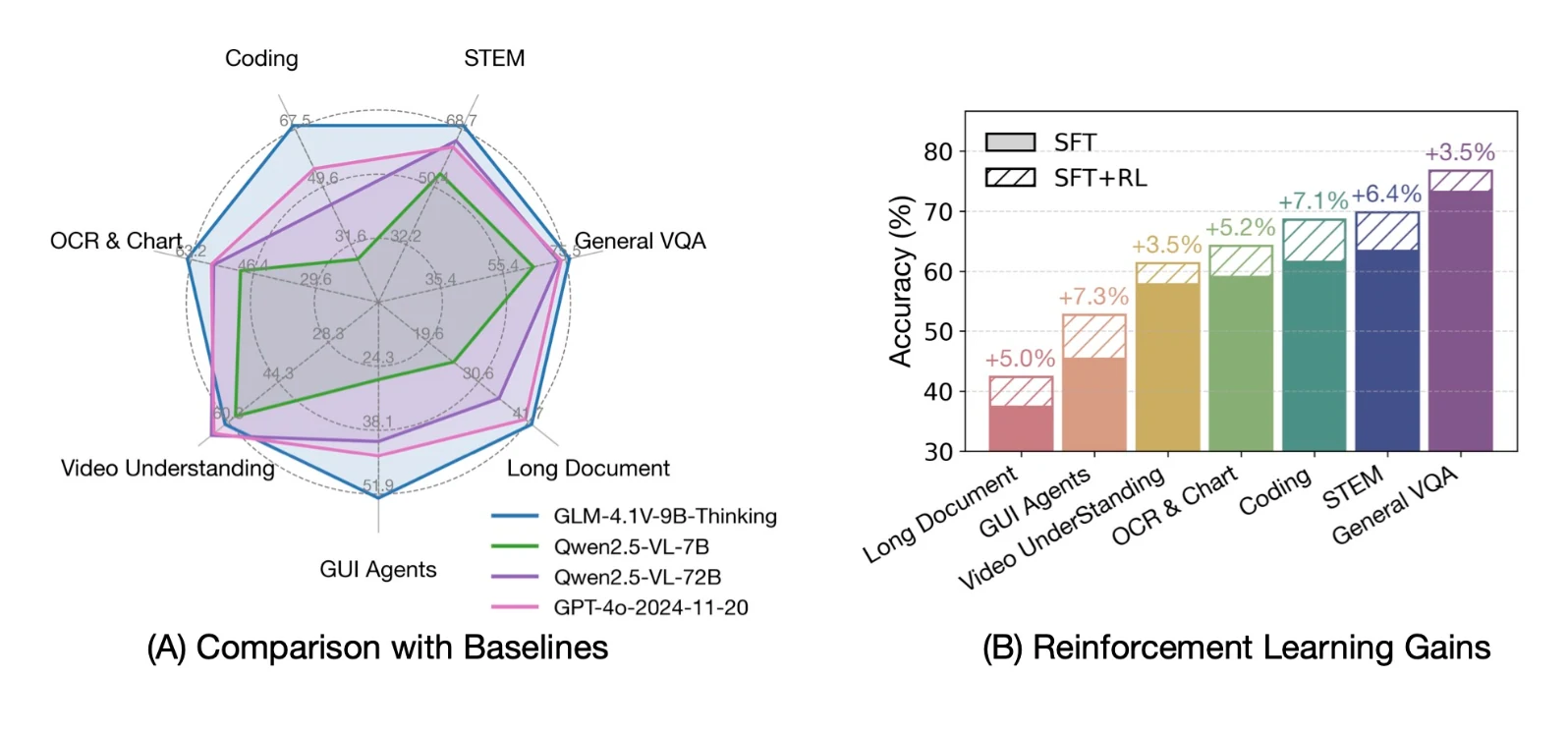
1. Raisonnement visuel avancé
- Va au-delà de la légende de base : comprend les images complexes, les diagrammes scientifiques et les comparaisons
- Prend en charge le raisonnement spatial : identifie les objets et les boîtes englobantes
- A obtenu les meilleurs scores sur les benchmarks de question-réponse visuelle comme MMBench & MMBench+
Depuis Hugging Face
2. Entrée multimodale + Mode de réflexion
- Accepte le texte, les images et les vidéos dans les conversations
- Propose un commutateur de « Mode de réflexion » : permet un raisonnement étape par étape avant la réponse finale
- Idéal pour les tâches complexes nécessitant des explications logiques
Depuis Hugging Face
3. Utilisation unifiée d’outils
- Conçu pour les cas d’usage d’agents IA : peut appeler de manière autonome des outils ou API externes
- Prise en charge native de l’appel de fonctions, compatible avec l’interface d’OpenAI
- Utilise un apprentissage basé sur des démonstrations pour l’utilisation d’outils
GLM-4.5V est un modèle d’IA multimodal puissant et convivial pour les développeurs, capable de traiter la compréhension d’images, le question-réponse visuel, l’OCR de documents, la génération de code et l’automatisation d’interface graphique — le tout via une interface unifiée. Il est idéal pour les agents IA, les outils de productivité, la recherche, et bien plus encore.
Exigences système de GLM 4.5V
| Aspect | Détails |
|---|---|
| Taille du modèle | 106B paramètres (MoE) ; 12B actifs par jeton |
| VRAM | 640 Go |
| Configuration GPU minimale | 8× NVIDIA H100 (80 Go chacun) |
| Options de précision | Prend en charge les formats de quantification FP16, FP8, INT8, INT4 |
| Configuration basse VRAM (optimisée) | Possible avec 2 GPU de 80 Go en utilisant FP8 et un partitionnement soigneux |
| Prise en charge du parallélisme | Parallélisme tenseur et de modèle pris en charge (ex. 4 GPU de 40 Go) |
| Bibliothèques clés | vLLM, SGLang |
Comment accéder à l’API de GLM 4.5V
L’accès à GLM-4.5V via Novita AI propose plusieurs voies adaptées à différents niveaux d’expertise technique et cas d’usage. Que vous soyez un utilisateur professionnel explorant les capacités de l’IA ou un développeur créant des applications de production, Novita AI met à disposition les outils dont vous avez besoin.
1. Utiliser le playground (Disponible dès maintenant - Aucun code requis)
- Accès instantané : Inscrivez-vous et commencez à expérimenter avec les modèles GLM-4.5V en quelques secondes
- Interface interactive : Testez des prompts de raisonnement visuel complexes et visualisez les sorties de chaîne de pensée en temps réel
- Comparaison de modèles : Comparez GLM-4.5V avec d’autres modèles de pointe pour votre cas d’usage spécifique
Le playground vous permet de télécharger des images directement, de tester différents prompts et d’obtenir des résultats immédiats sans aucune configuration technique. Parfait pour le prototypage, le test d’idées et la compréhension des capacités du modèle avant une mise en œuvre complète.
2. Intégration via API (En ligne et prête - Pour les développeurs)
Connectez GLM-4.5V à vos applications avec l’API REST unifiée de Novita AI.
Option 1 : Intégration API directe (Exemple Python)

Essayez GLM4.5V dès maintenant !
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fonctionnalités clés :
- API compatible OpenAI pour une intégration transparente
- Contrôle flexible des paramètres pour affiner les réponses
- Prise en charge du streaming pour des réponses en temps réel
Option 2 : Workflows multi-agents avec le SDK OpenAI Agents
Créez des systèmes multi-agents sophistiqués en utilisant GLM-4.5V :
- Intégration plug-and-play : Utilisez GLM-4.5V dans n’importe quel workflow OpenAI Agents
- Capacités d’agent avancées : Prise en charge des transferts, du routage et de l’intégration d’outils avec des performances de raisonnement visuel supérieures
- Architecture évolutive : Concevez des agents qui exploitent les capacités de raisonnement unifiées, de codage et d’analyse visuelle de GLM-4.5V
3. Se connecter à des plateformes tierces
Outils de développement : Intégrez-vous de manière transparente aux IDE et environnements de développement populaires comme Cursor, Trae, Qwen Code et Cline via des API compatibles OpenAI.
Frameworks d’orchestration : Connectez-vous à LangChain, Dify, CrewAI, Langflow et autres plateformes d’orchestration IA à l’aide de connecteurs officiels.
**Intégration Hugging Face : Novita AI est un fournisseur d’inférence officiel de Hugging Face, garantissant une compatibilité large avec l’écosystème.
Utilisation de l’interface en ligne de commande (CLI) de GLM 4.5V
Pour les développeurs qui préfèrent exécuter des modèles localement ou souhaitent plus de contrôle sur l’environnement, GLM-4.5V peut également être utilisé via une interface en ligne de commande. Zhipu AI a open-sourcé les poids du modèle et fourni des outils pour exécuter le modèle sur votre propre matériel.
Le modèle est disponible sur le Hub Hugging Face sous le nom zai-org/GLM-4.5V. Vous pouvez télécharger le modèle puis utiliser la bibliothèque Transformers pour générer des sorties. Par exemple, dans un script Python ou un notebook Jupyter :
python3 inference/trans_infer_cli.py --model-path zai-org/GLM-4.5V --image test.jpg --question "这张图里有什么?"
| Fonctionnalité | CLI | API |
|---|---|---|
| Utilisation | Saisir des commandes + paramètres dans le terminal | Appeler des bibliothèques/requêtes HTTP dans le code |
| Sortie | Imprimée directement dans le terminal | Retourne des objets/JSON, facile à traiter ultérieurement |
| Idéal pour | Tester des modèles, une inférence rapide, de petits scripts | Développement d’applications, intégration de services, appels à grande échelle |
| Flexibilité | Paramètres fixes, combinaisons limitées | Entièrement programmable, prend en charge une logique complexe |
| Dépendances | A seulement besoin d’un script/outil CLI | Nécessite d’écrire du code et de gérer les dépendances |
Essayez GLM4.5V dès maintenant !
Créer un outil simple de reconnaissance d’images avec MCP et GLM4.5V
Si vous souhaitez exploiter les capacités de GLM — comme la création d’un outil simple de reconnaissance d’images pour démontrer son intégration de reconnaissance visuelle et de raisonnement — vous pouvez utiliser la fonctionnalité MCP prise en charge par Novita AI. Vous trouverez ci-dessous un exemple de code :
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Essayez GLM4.5V dès maintenant !
Résolution des problèmes courants de GLM 4.5V
1. Erreurs de mémoire et de chargement (CUDA OOM) Cause : Le modèle est trop volumineux pour tenir dans la mémoire GPU disponible.
Solutions :
- Utiliser le backend d’inférence recommandé
- Exemple : Activez
--attention-backend fa3dans SGLang pour réduire l’utilisation de la mémoire.
- Exemple : Activez
- Utiliser plus de GPU avec une taille de parallélisme tenseur plus petite
- Exemple : Définissez TP=8 (8 GPU) au lieu de TP=4 pour allouer des morceaux de modèle plus petits par GPU.
- Charger un modèle quantifié (8 bits ou 4 bits)
- Par exemple, utilisez
load_in_8bit=Truelors de l’utilisation de HuggingFace Transformers.
- Par exemple, utilisez
- Choisissez des instances cloud avec plus de VRAM
- Exemple : A100 (80 Go) ou H200 (141 Go) ; le H200 peut exécuter le modèle sur un seul GPU.
- Traiter les entrées longues en morceaux plus petits
- Divisez les vidéos longues en segments plus courts ou désactivez le mode de réflexion pour réduire la taille de la sortie.
2. Entrée d’image non reconnue Cause : L’image n’est pas formatée ou transmise correctement au modèle.
Solutions :
- Pour les API de style OpenAI, structurez l’entrée comme un message spécial
- Exemple :
[{"type": "image_url", "image_url": {"url": "<URL>"}}, {"type": "text", "text": "your question"}]
- Exemple :
- Lors de l’utilisation de HuggingFace Transformers, utilisez
AutoProcessor- Exemple : Appelez
processor(images=[...], text=[...])avant l’inférence.
- Exemple : Appelez
- Assurez-vous que l’URL de l’image est publique ou utilisez un encodage base64 si c’est pris en charge
- Si le modèle ignore l’image ou indique ne pas l’avoir reçue, l’entrée est probablement invalide.
4. Formatage de sortie étrange Problèmes :
- Les sorties incluent du HTML brut (ex.
<div>...</div>) - Caractères d’échappement inattendus (ex.
<) - Réponses répétées ou ajoutées
Solutions :
- Demandez au modèle de formater le code en Markdown (ex. utilisez des triples backticks)
- Appliquez des correctifs pour résoudre l’échappement HTML (disponibles dans les dépôts officiels)
- Désactivez le mode de réflexion si ce n’est pas nécessaire
- Post-traitez la sortie pour supprimer le contenu en double
5. Artéfacts d’utilisation d’outils
Problème : Le modèle génère des commandes liées aux outils (ex. <|search|>).
Solution :
Utilisez l’API standard de complétion de chat au lieu des endpoints d’agent, et évitez les prompts qui imitent des scénarios d’utilisation d’outils.
6. Limites de précision Limites connues :
- Peut avoir des difficultés avec des tâches visuelles fines comme le comptage ou la reconnaissance faciale
- Les questions texte uniquement peuvent être mieux répondues par des modèles texte spécialisés
- Lent avec des documents ou vidéos très longs ; peut atteindre des limites de temps
Recommandations :
- Utilisez le mode streaming pour les entrées longues afin de recevoir des sorties partielles
- Divisez les grandes entrées en segments plus petits
- Vérifiez les limites réelles de longueur de contexte de votre fournisseur d’API
GLM-4.5V est une véritable révolution pour l’IA langage-visuel, apportant des capacités qui étaient auparavant l’apanage des modèles propriétaires dans le monde open source et auto-hébergé. Nous avons couvert ce qu’est GLM-4.5V et ce qui le rend spécial, la configuration dont vous avez besoin pour l’exécuter, comment résoudre les problèmes courants et plusieurs moyens d’y accéder (API cloud ou CLI local). Avec ces connaissances, les développeurs peuvent intégrer GLM-4.5V dans leurs projets en toute confiance.
Dois-je passer de Gemma 3 27B à GLM 4.5V ?
GLM-4.5V est le dernier modèle de langage multimodal open source de Zhipu AI. Il peut traiter à la fois des tâches de langage et de vision, incluant le texte, les images et les vidéos, avec des capacités de raisonnement avancées.
Que peut faire GLM-4.5V ?
Il prend en charge le raisonnement visuel avancé (ex. diagrammes scientifiques, raisonnement spatial, question-réponse visuel), la compréhension de documents longs, la génération de code, l’OCR, l’automatisation d’interface graphique et le dialogue multimodal.
En quoi GLM-4.5V diffère-t-il des modèles précédents ?
Il améliore GLM-4.1V en utilisant une architecture Mixture-of-Experts (MoE) avec 106B paramètres (12B actifs par entrée), ainsi qu’un 3D-RoPE pour une longueur de contexte de 64k, permettant un coût plus faible et des performances plus élevées.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en IA. API intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez les infrastructures, commencez gratuitement et concrétisez votre vision de l’IA.



