

GLM-4.5V é o mais recente modelo de linguagem grande (LLM) multimodal de código aberto da Zhipu AI, projetado para lidar com tarefas de linguagem e visão em um sistema unificado. Ele representa uma atualização significativa em relação ao modelo anterior GLM-4.1V, apresentando uma arquitetura Mistura de Especialistas (MoE) com 106 bilhões de parâmetros (cerca de 12B ativos por entrada).
Esse design permite que o GLM-4.5V alcance desempenho superior com custo de inferência menor, ativando apenas as subredes de “especialistas” especializadas conforme necessário. O modelo introduz a Codificação Posicional Rotatória 3D (3D-RoPE) para um contexto estendido de 64k tokens, permitindo que ele lide com documentos longos e entradas multidimensionais com facilidade.
Em termos mais simples, o GLM-4.5V pode “ver” e raciocinar sobre imagens e vídeos enquanto também participa de diálogos em linguagem natural, tornando-o um modelo de linguagem e visão (VLM) poderoso para desenvolvedores.
O que é o GLM 4.5V?
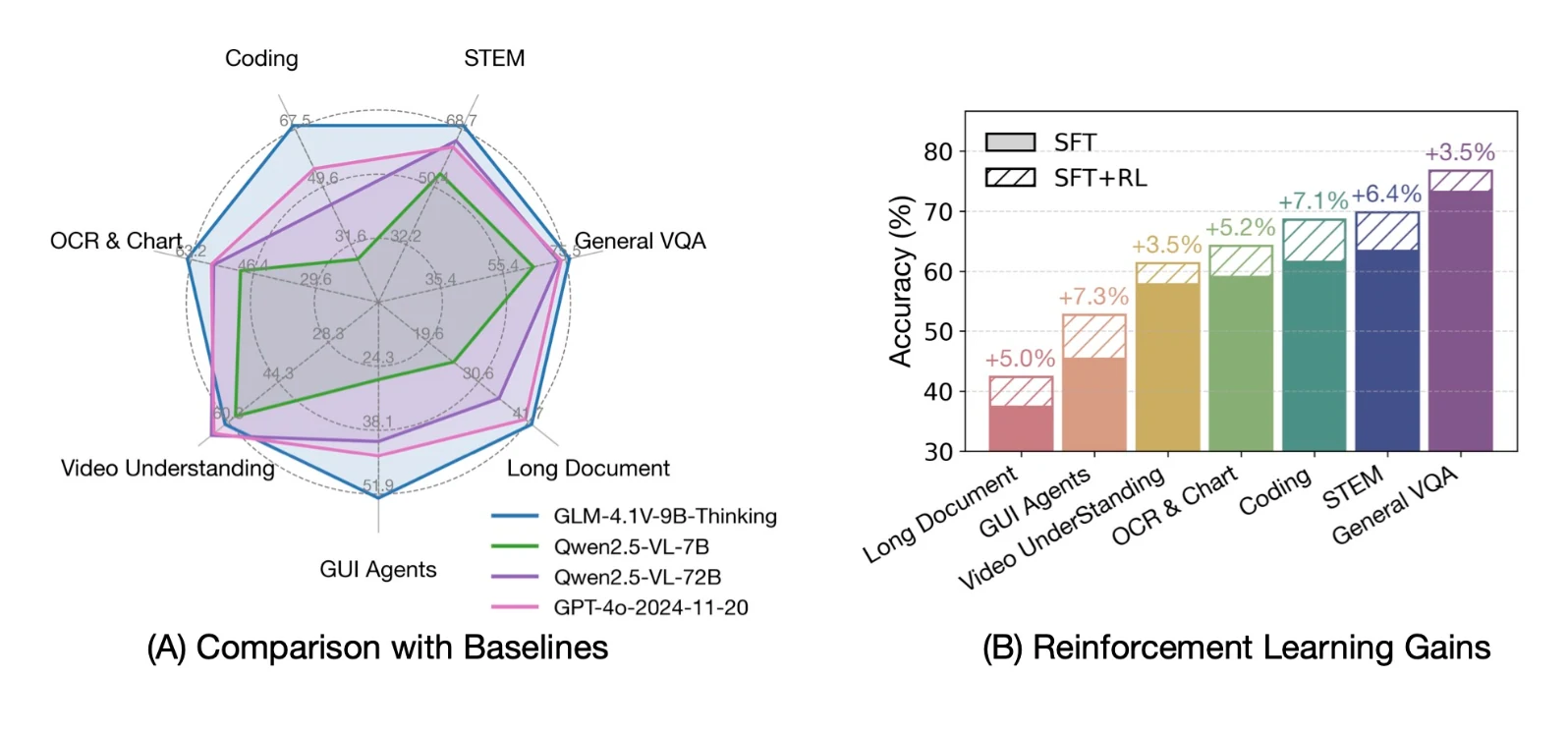
1. Raciocínio Visual Avançado
- Vai além da legenda básica — compreende imagens complexas, diagramas científicos e comparações
- Suporta raciocínio espacial: identifica objetos e caixas delimitadoras
- Alcançou pontuações máximas em benchmarks de QA visual como MMBench e MMBench+
De Hugging Face
2. Entrada Multimodal + Modo de Pensamento
- Aceita texto, imagens e vídeos nas conversas
- Oferece uma opção de “Modo de Pensamento”: permite raciocínio passo a passo antes da resposta final
- Ideal para tarefas complexas que exigem explicações lógicas
De Hugging Face
3. Uso Unificado de Ferramentas
- Projetado para casos de uso de agentes de IA — pode chamar ferramentas externas ou APIs de forma autônoma
- Suporte nativo para chamada de funções, compatível com a interface da OpenAI
- Usa treinamento baseado em demonstrações para uso de ferramentas
O GLM-4.5V é um modelo de IA multimodal poderoso e amigável para desenvolvedores, capaz de lidar com compreensão de imagens, QA visual, OCR de documentos, geração de código e automação de GUI — tudo por meio de uma interface unificada. É ideal para agentes de IA, ferramentas de produtividade, pesquisa e muito mais.
Requisitos de Sistema do GLM 4.5V
| Aspecto | Detalhes |
|---|---|
| Tamanho do Modelo | 106B de parâmetros (MoE); 12B ativos por token |
| VRAM | 640GB |
| Necessidade Mínima de GPU | 8× NVIDIA H100 (80GB cada) |
| Opções de Precisão | Suporta formatos de quantização FP16, FP8, INT8 e INT4 |
| Configuração de Baixa VRAM (Otimizada) | Possível com 2 GPUs de 80GB usando FP8 e particionamento cuidadoso |
| Suporte a Paralelismo | Paralelismo de tensor e de modelo suportado (ex: 4 GPUs de 40GB) |
| Bibliotecas Principais | vLLM, SGLang |
Como Acessar a API do GLM 4.5V
Acessar o GLM-4.5V por meio da Novita AI oferece múltiplos caminhos adaptados a diferentes níveis de conhecimento técnico e casos de uso. Seja você um usuário empresarial explorando capacidades de IA ou um desenvolvedor criando aplicações de produção, a Novita AI fornece as ferramentas que você precisa.
1. Use o Playground (Disponível Agora - Sem necessidade de codificação)
- Acesso Instantâneo: Cadastre-se e comece a experimentar com os modelos GLM-4.5V em segundos
- Interface Interativa: Teste prompts complexos de raciocínio visual e visualize as saídas de raciocínio passo a passo em tempo real
- Comparação de Modelos: Compare o GLM-4.5V com outros modelos líderes para seu caso de uso específico
O playground permite que você envie imagens diretamente, teste vários prompts e veja resultados imediatos sem nenhuma configuração técnica. Perfeito para prototipagem, teste de ideias e compreensão das capacidades do modelo antes da implementação completa.
2. Integre via API (Ao Vivo e Pronto - Para Desenvolvedores)
Conecte o GLM-4.5V às suas aplicações com a API REST unificada da Novita AI.
Opção 1: Integração Direta de API (Exemplo em Python)

from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Principais Recursos:
- API compatível com a OpenAI para integração perfeita
- Controle flexível de parâmetros para ajuste fino das respostas
- Suporte a streaming para respostas em tempo real
Opção 2: Fluxos de Trabalho Multiagente com o SDK de Agentes da OpenAI
Crie sistemas multiagente sofisticados usando o GLM-4.5V:
- Integração Plug-and-Play: Use o GLM-4.5V em qualquer fluxo de trabalho de Agentes da OpenAI
- Capacidades Avançadas de Agente: Suporte a transferências, roteamento e integração de ferramentas com desempenho superior de raciocínio visual
- Arquitetura Escalável: Projete agentes que aproveitem as capacidades unificadas de raciocínio, codificação e análise visual do GLM-4.5V
3. Conecte-se com Plataformas de Terceiros
Ferramentas de Desenvolvimento: Integre-se perfeitamente com IDEs populares e ambientes de desenvolvimento como Cursor, Trae, Qwen Code e Cline por meio de APIs compatíveis com a OpenAI.
Frameworks de Orquestração: Conecte-se com LangChain, Dify, CrewAI, Langflow e outras plataformas de orquestração de IA usando conectores oficiais.
Integração com o Hugging Face: A Novita AI atua como um provedor de inferência oficial do Hugging Face, garantindo ampla compatibilidade com o ecossistema.
Usando a Interface de Linha de Comando (CLI) do GLM 4.5V
Para desenvolvedores que preferem executar modelos localmente ou desejam mais controle sobre o ambiente, o GLM-4.5V também pode ser usado por meio de uma interface de linha de comando. A Zhipu AI disponibilizou os pesos do modelo em código aberto e forneceu ferramentas para executar o modelo em seu próprio hardware.
O modelo está disponível no Hugging Face Hub como zai-org/GLM-4.5V. Você pode baixar o modelo e depois usar a biblioteca Transformers para gerar saídas. Por exemplo, em um script Python ou notebook Jupyter:
python3 inference/trans_infer_cli.py --model-path zai-org/GLM-4.5V --image test.jpg --question "这张图里有什么?"
| Recurso | CLI | API |
|---|---|---|
| Uso | Insira comandos + parâmetros no terminal | Chame bibliotecas/solicitações HTTP no código |
| Saída | Impressa diretamente no terminal | Retorna objetos/JSON, fácil para processamento posterior |
| Ideal para | Teste de modelos, inferência rápida, scripts pequenos | Desenvolvimento de aplicações, integração de serviços, chamadas em larga escala |
| Flexibilidade | Parâmetros fixos, combinações limitadas | Totalmente programável, suporta lógica complexa |
| Dependências | Apenas precisa de um script/ferramenta CLI | Requer escrita de código e gerenciamento de dependências |
Crie uma Ferramenta Simples de Reconhecimento de Imagens usando MCP e GLM4.5V
Se você deseja aproveitar as capacidades do GLM — como construir uma ferramenta simples de reconhecimento de imagens para demonstrar sua integração de reconhecimento visual e raciocínio — você pode usar a funcionalidade MCP suportada pela Novita AI. Abaixo está o código de exemplo:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Solução de Problemas Comuns do GLM 4.5V
1. Erros de Memória e Carregamento (CUDA OOM) Causa: O modelo é muito grande para caber na memória de GPU disponível.
Soluções:
- Use o backend de inferência recomendado
- Exemplo: Habilite
--attention-backend fa3no SGLang para reduzir o uso de memória.
- Exemplo: Habilite
- Use mais GPUs com tamanho de paralelismo de tensor menor
- Exemplo: Defina TP=8 (8 GPUs) em vez de TP=4 para alocar pedaços de modelo menores por GPU.
- Carregue um modelo quantizado (8 bits ou 4 bits)
- Por exemplo, use
load_in_8bit=Trueao usar o HuggingFace Transformers.
- Por exemplo, use
- Escolha instâncias de nuvem com VRAM maior
- Exemplo: A100 (80GB) ou H200 (141GB); o H200 pode executar o modelo em uma única GPU.
- Processe entradas longas em pedaços menores
- Divida vídeos longos em segmentos mais curtos ou desative o modo de pensamento para reduzir o tamanho da saída.
2. Entrada de Imagem Não Reconhecida Causa: A imagem não está formatada ou passada corretamente para o modelo.
Soluções:
- Para APIs no estilo OpenAI, estruture a entrada como uma mensagem especial
- Exemplo:
[{"type": "image_url", "image_url": {"url": "<URL>"}}, {"type": "text", "text": "your question"}]
- Exemplo:
- Ao usar o HuggingFace Transformers, use
AutoProcessor- Exemplo: Chame
processor(images=[...], text=[...])antes da inferência.
- Exemplo: Chame
- Garanta que a URL da imagem seja pública ou use codificação base64 se suportado
- Se o modelo ignorar a imagem ou disser que não a recebeu, a entrada pode ser inválida.
4. Formatação de Saída Estranha Problemas:
- Saídas incluem HTML bruto (ex:
<div>...</div>) - Caracteres de escape inesperados (ex:
<) - Respostas repetidas ou adicionadas
Soluções:
- Instrua o modelo a formatar código em Markdown (ex: use aspas triplas)
- Aplique patches para corrigir o escape de HTML (disponíveis em repositórios oficiais)
- Desative o modo de pensamento se não for necessário
- Pós-processe a saída para remover conteúdo duplicado
5. Artefatos de Uso de Ferramentas
Problema: O modelo gera comandos relacionados a ferramentas (ex: <|search|>).
Solução:
Use a API padrão de conclusão de chat em vez de endpoints de agente, e evite prompts que imitem cenários de uso de ferramentas.
6. Limitações de Precisão Limitações conhecidas:
- Pode ter dificuldades com tarefas visuais de granulação fina, como contagem ou reconhecimento facial
- Perguntas apenas de texto podem ser melhor respondidas por modelos de texto especializados
- Lento com documentos ou vídeos muito longos; pode atingir limites de tempo
Recomendações:
- Use o modo de streaming para entradas longas para receber saídas parciais
- Divida entradas grandes em segmentos menores
- Verifique os limites reais de comprimento de contexto do seu provedor de API
O GLM-4.5V é um divisor de águas para a IA de linguagem e visão, trazendo capacidades que antes eram exclusivas de modelos proprietários para o mundo de código aberto e auto-hospedado. Cobrimos o que é o GLM-4.5V e por que ele é especial, a configuração necessária para executá-lo, como solucionar problemas comuns e múltiplas formas de acessá-lo (API de nuvem ou CLI local). Com esse conhecimento, os desenvolvedores podem incorporar o GLM-4.5V em seus projetos com confiança
Devo atualizar do Gemma 3 27B para o GLM 4.5V?
O GLM-4.5V é o mais recente modelo de linguagem grande multimodal de código aberto da Zhipu AI. Ele pode lidar com tarefas de linguagem e visão, incluindo texto, imagens e vídeos, com capacidades avançadas de raciocínio.
O que o GLM-4.5V pode fazer?
Ele suporta raciocínio visual avançado (ex: diagramas científicos, raciocínio espacial, QA visual), compreensão de documentos longos, geração de código, OCR, automação de GUI e diálogo multimodal.
Como o GLM-4.5V difere de modelos anteriores?
Ele melhora o GLM-4.1V ao usar uma arquitetura Mistura de Especialistas (MoE) com 106B de parâmetros (12B ativos por entrada), além de 3D-RoPE para um comprimento de contexto de 64k, permitindo custo menor e desempenho mais forte.
Novita AI é a plataforma de nuvem tudo-em-um que capacita suas ambições de IA. APIs integradas, serverless, Instâncias de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA uma realidade.



