

- GLM 4.5V et Qwen 2.5-VL : différences architecturales clés
- GLM 4.5V et Qwen 2.5-VL : comparaison des benchmarks
- Forces et faiblesses de GLM 4.5V et Qwen 2.5-VL
- GLM 4.5V vs Qwen 2.5-VL : lequel est le meilleur pour le résumé de texte, le chatbot, le NLP basé sur l'image ?
- Novita AI : fournisseur d'API GLM 4.5V plus rentable et stable
- Créez un outil simple de reconnaissance d'images avec MCP et GLM.
GLM 4.5V et Qwen 2.5-VL sont deux modèles de vision-langage (VLM) open source de pointe récemment issus de la communauté IA chinoise. Les deux visent à repousser les limites de l’IA multimodale, en combinant la compréhension du langage naturel avec l’analyse de contenu visuel. Dans cet article, nous comparons GLM 4.5V et Qwen 2.5-VL selon plusieurs dimensions importantes pour les développeurs.
GLM 4.5V et Qwen 2.5-VL : différences architecturales clés
| Caractéristique | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Type d’architecture | Mixture-of-Experts (MoE), 355B paramètres totaux, ~32B actifs par token (Air : 106B total / 12B actifs) | Transformer dense, tous les 72B paramètres actifs pour chaque token |
| Efficacité vs capacité | Haute capacité avec un coût d’inférence réduit grâce à l’activation partielle des experts | Stable mais coût de calcul élevé, tous les paramètres utilisés par entrée |
| Encodeur visuel | Vision Transformer (ViT), implémentation standard | ViT avec Window Attention, RMSNorm et SwiGLU pour un traitement haute résolution plus efficace |
| Longueur de contexte | Jusqu’à 128K tokens (131K dans certaines configurations) | Jusqu’à 32K tokens |
GLM 4.5V et Qwen 2.5-VL : données d’entraînement
1. Échelle des données
| Catégorie | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Tokens textuels | ~23 billions de tokens au total – 15B généraux – 8B raisonnement/codage/tâches agent |
Estimé ~18B+ tokens pour la variante 72B (basé sur l’évolution des séries Qwen précédentes) |
2. Types de données
| Catégorie | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Texte | Texte multilingue, code, texte web, prompts de raisonnement, données de tâches agent | Texte multilingue général, instructions, éventuellement prompts alignés sur les préférences |
| Données visuelles | Paires image-texte nettoyées + re-légendées Diagrammes académiques, graphiques, images mathématiques Captures d’écran GUI, PDF, notes manuscrites, OCR multilingue |
Données visuelles larges Inclut formulaires scannés, factures, présentations, étiquettes de boîtes englobantes, texte OCR |
| Données vidéo | Vidéos longues avec supervision de raisonnement | Vidéos avec résolution dynamique et échantillonnage d’images |
3. Capacités supplémentaires et techniques d’entraînement
| Catégorie | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Support du raisonnement | Entraîné avec des prompts chain-of-thought penser... réponse entrelacés avec des tâches visuelles |
Le raisonnement est interne ; pas d’exposition explicite au chain-of-thought |
| Approche de fine-tuning | Reinforcement Learning with Curriculum Sampling (RLCS) sur plusieurs domaines : STEM, GUI, vidéos, documents | Fine-tuning RLHF/RLAIF-like (non entièrement divulgué), appliqué au moins au modèle 32B, probablement hérité dans le 72B |
| Capacités multimodales | Entraîné pour des tâches d’agent : raisonnement sur les images, actions (ex. interaction GUI, utilisation d’outils) | Performant sur les sorties structurées : OCR en JSON, analyse de mise en page (QwenVL HTML), détection d’objets avec coordonnées |
En résumé, l’entraînement de GLM 4.5V a mis l’accent sur la qualité et le raisonnement (données organisées + raisonnement explicite + RL multi-domaine), tandis que celui de Qwen 2.5-VL a mis l’accent sur la largeur et la vision (couverture large des données + entraînement visuel dynamique + un certain alignement RL).
GLM 4.5v et Qwen 2.5-VL : comparaison de la latence d’inférence
GLM 4.5V utilise une architecture Mixture-of-Experts (MoE), ce qui signifie que seule une petite partie (~12B paramètres) est active par token lors de l’inférence, malgré la taille totale du modèle dépassant 100B.
Cette conception lui permet de fonctionner plus efficacement, offrant des vitesses similaires à un modèle dense de 12B à 20B, plutôt que de se comporter comme un modèle dense de 72B+ en termes de latence et de débit.
GLM 4.5V gère de longs contextes (jusqu’à 128K tokens) avec une croissance de latence plus faible, ce qui le rend particulièrement adapté aux tâches impliquant de longs documents ou des conversations à plusieurs tours.
GLM prend en charge un mode spécial /nothink, qui désactive le raisonnement étape par étape lorsque ce n’est pas nécessaire, permettant des sorties plus rapides et plus concises.
Dans l’ensemble, GLM 4.5V offre une excellente efficacité et évolutivité d’inférence pour les longs contextes, mais nécessite un matériel puissant et un déploiement intelligent pour atteindre son plein potentiel.
GLM 4.5V et Qwen 2.5-VL : comparaison des benchmarks
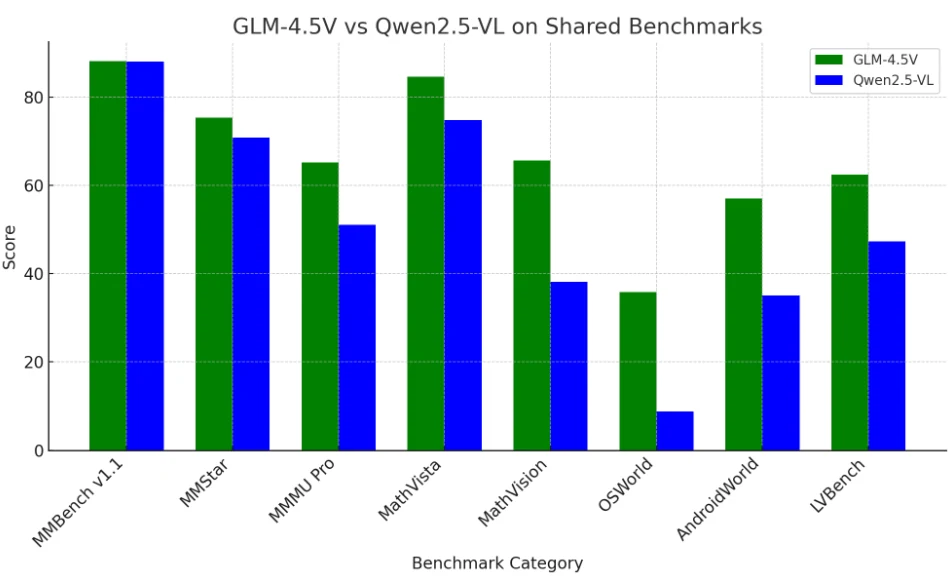
GLM-4.5V est actuellement en tête des performances globales des benchmarks, en particulier dans les tâches multimodales complexes et à long contexte,
mais Qwen2.5-VL reste très compétitif et était auparavant la référence à battre.
Les deux modèles surpassent la plupart des autres LLM open source et sont de sérieux concurrents même face aux géants propriétaires dans le domaine de la vision-langage.
Forces et faiblesses de GLM 4.5V et Qwen 2.5-VL

Essayez GLM4.5V et Qwen 2.5VL maintenant !
GLM 4.5V vs Qwen 2.5-VL : lequel est le meilleur pour le résumé de texte, le chatbot, le NLP basé sur l’image ?
Résumé de texte : GLM-4.5V gagne
Pour résumer de longs documents, rapports ou contenus multimodaux, GLM-4.5V a un net avantage. Sa fenêtre de contexte de 128K lui permet de traiter des livres entiers ou de grands logs de conversation sans troncature. Il peut résumer tout en analysant ou en raisonnant sur le contenu, grâce à son mode chain-of-thought intégré.
Qwen 2.5-VL est également excellent pour le résumé, en particulier pour les articles plus courts ou les documents de longueur standard. Il produit des résumés clairs, concis et bien formatés, et est plus rapide pour les tâches de longueur modérée. Cependant, pour un résumé intensif, surtout impliquant texte + image, GLM est plus capable.
Chatbots : Cela dépend des besoins
Pour les chatbots nécessitant un raisonnement approfondi, une longue mémoire et une exécution progressive des tâches, GLM-4.5V est plus puissant. Il prend en charge l’utilisation d’outils et les longues conversations sans oublier le contexte. Son raisonnement structuré (avec le mode penser) permet une meilleure gestion des requêtes complexes.
Pour les chatbots visuels, surtout ceux impliquant des captures d’écran, des images ou l’analyse de mise en page, Qwen 2.5-VL excelle. Il comprend bien les images, fournit des réponses structurées (ex. en JSON) et prend en charge le dialogue visuel multi-tours. Il est également légèrement plus aligné « prêt à l’emploi » pour une interaction fluide et polie.
Tâches NLP basées sur l’image : Qwen2.5-VL mène
Pour les tâches qui impliquent l’extraction de données structurées à partir d’images, comme l’OCR, la compréhension de formulaires ou la reconnaissance de mise en page, Qwen 2.5-VL est le modèle le plus performant.
- Il prend en charge la détection de boîtes englobantes, produit des mises en page structurées en HTML ou JSON, et peut analyser des documents visuels complexes.
- Son OCR multilingue et sa capacité à raisonner sur le contenu d’une image le rendent très pratique pour le NLP visuel orienté entreprise.
GLM-4.5V peut également gérer ces tâches, mais décrit généralement le contenu visuel sous forme de texte libre plutôt que dans des formats structurés, ce qui peut nécessiter plus de post-traitement.
Novita AI : fournisseur d’API GLM 4.5V plus rentable et stable
L’API GLM-4.5V de Novita AI offre un contexte de 65,5K, avec un prix d’entrée à 0,60 $/1K tokens, une sortie à 1,80 $/1K tokens, et prend en charge l’appel de fonctions et les sorties structurées.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez GLM4.5V et Qwen 2.5VL maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page Settings, vous pouvez copier la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Créez un outil simple de reconnaissance d’images avec MCP et GLM.
Si vous souhaitez exploiter les capacités de GLM—par exemple pour construire un outil simple de reconnaissance d’images démontrant son intégration de la reconnaissance visuelle et du raisonnement—vous pouvez utiliser la fonctionnalité MCP prise en charge par Novita AI. Voici le code d’exemple :
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Si vous souhaitez obtenir les détails, vous pouvez consulter cet article : Comment créer votre premier serveur MCP avec Novita AI !
Après avoir comparé ces modèles, il est clair que GLM 4.5V et Qwen 2.5-VL sont extrêmement puissants. Le modèle « meilleur » dépend vraiment du cas d’utilisation et des contraintes spécifiques. Nous conclurons par une brève FAQ répondant à quelques questions pratiques restantes :
Quelles sont les principales améliorations architecturales de GLM-4.5V ?
Seules les versions plus petites (≤13B) peuvent fonctionner sur un seul GPU ; les modèles de taille réelle nécessitent des configurations multi-GPU ou une inférence dans le cloud.
Ces modèles prennent-ils en charge d’autres langues que l’anglais et le chinois ?
Leur point fort est l’anglais et le chinois, mais ils peuvent traiter d’autres langues avec une qualité variable.
Puis-je effectuer un fine-tuning de ces modèles pour ma tâche ?
Oui, les deux peuvent être affinés ou adaptés à l’aide de techniques comme LoRA, mais les grands modèles nécessitent des ressources de calcul importantes.
Novita AI est la plateforme cloud tout-en-un qui stimule vos ambitions en IA. API intégrées, serverless, GPU Instance — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



