

GLM 4.5V と Qwen 2.5-VL は、中国のAIコミュニティから最近登場した、最先端のオープンソース視覚言語モデル(VLM)です。両モデルは、自然言語理解と視覚コンテンツ分析を組み合わせ、マルチモーダルAIの最先端を目指しています。このブログ記事では、開発者にとって重要な複数の側面から GLM 4.5V と Qwen 2.5-VL を比較します。
GLM 4.5V と Qwen 2.5-VL:主要なアーキテクチャの違い
| 特徴 | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| アーキテクチャタイプ | Mixture-of-Experts (MoE)、総パラメータ355B、トークンあたり約32Bアクティブ(Air版:総106B / アクティブ12B) | デンストランスフォーマー、全72Bパラメータが各トークンでアクティブ |
| 効率性と容量 | 部分的なエキスパート活性化により、高容量でありながら推論コストが低い | 安定しているが計算コストが高く、入力ごとに全パラメータを使用 |
| 視覚エンコーダ | Vision Transformer (ViT) ベース、標準実装 | Window Attention、RMSNorm、SwiGLU を採用したViTで、高解像度処理を効率化 |
| コンテキスト長 | 最大128Kトークン(一部構成では131K) | 最大32Kトークン |
GLM 4.5V と Qwen 2.5-VL:トレーニングデータ
1. データ規模
| カテゴリ | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| テキストトークン | 合計約23兆トークン – 汎用15T – 推論/コード/エージェントタスク8T |
72Bバリアントで推定18T+ トークン (Qwenシリーズからのスケーリングに基づく) |
2. データタイプ
| カテゴリ | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| テキスト | 多言語テキスト、コード、ウェブテキスト、推論プロンプト、エージェントタスクデータ | 汎用多言語テキスト、指示、おそらく嗜好調整済みプロンプト |
| 視覚データ | クリーニング+再キャプション済み画像テキストペア 学術図表、チャート、数式画像 GUIスクリーンショット、PDF、手書きメモ、多言語OCR |
広範な視覚データ スキャンされたフォーム、請求書、プレゼンテーション、バウンディングボックスラベル、OCRテキストを含む |
| 動画データ | 推論教師ありの長尺動画 | 動的解像度とフレームサンプリングを適用した動画 |
3. 追加機能とトレーニング手法
| カテゴリ | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| 推論サポート | thinking... response チェイン・オブ・ソートプロンプトを視覚タスクに織り交ぜてトレーニング |
推論は内部的に行われ、明示的なチェイン・オブ・ソートはなし |
| ファインチューニング手法 | STEM、GUI、動画、文書など複数領域でのReinforcement Learning with Curriculum Sampling (RLCS) | RLHF/RLAIFライクなファインチューニング(完全開示されていない)、少なくとも32Bモデルに適用、72Bでも継承されている可能性あり |
| マルチモーダル機能 | エージェントタスク向けにトレーニング:画像の推論、アクション実行(GUI操作、ツール使用など) | 構造化出力に強み:JSON形式のOCR、レイアウト解析(QwenVL HTML)、座標付き物体検出 |
まとめると、GLM 4.5V のトレーニングは ** 品質と推論 (厳選データ+明示的推論+マルチドメインRL)に重点を置いており、一方 Qwen 2.5-VL は ** 幅広さと視覚(広範なデータカバレッジ+動的視覚トレーニング+一部RL調整)に重点を置いています。
GLM 4.5V と Qwen 2.5-VL:推論レイテンシ比較
GLM 4.5V は Mixture-of-Experts (MoE) アーキテクチャ を採用しており、モデル全体のサイズは100B以上ですが、推論時にはトークンあたり小さな部分(約12Bパラメータ)だけがアクティブになります。
この設計により、より効率的に動作 し、レイテンシとスループットの点で12B~20Bのデンスモデルと同様の速度を実現します。72B以上のデンスモデルとして振る舞うことはありません。
GLM 4.5V は長いコンテキスト(最大128Kトークン)を低レイテンシで扱える ため、長文書やマルチターン会話を含むタスクに特に適しています。
GLM は特別な /nothink モード をサポートしており、段階的な推論が不要な場合にそれを無効にすることで、より高速で簡潔な出力が可能です。
全体的に、GLM 4.5V は優れた長文脈推論効率とスケーラビリティを提供 しますが、その潜在能力を最大限に引き出すには強力なハードウェアとスマートなデプロイが必要です。
GLM 4.5V と Qwen 2.5-VL:ベンチマーク比較
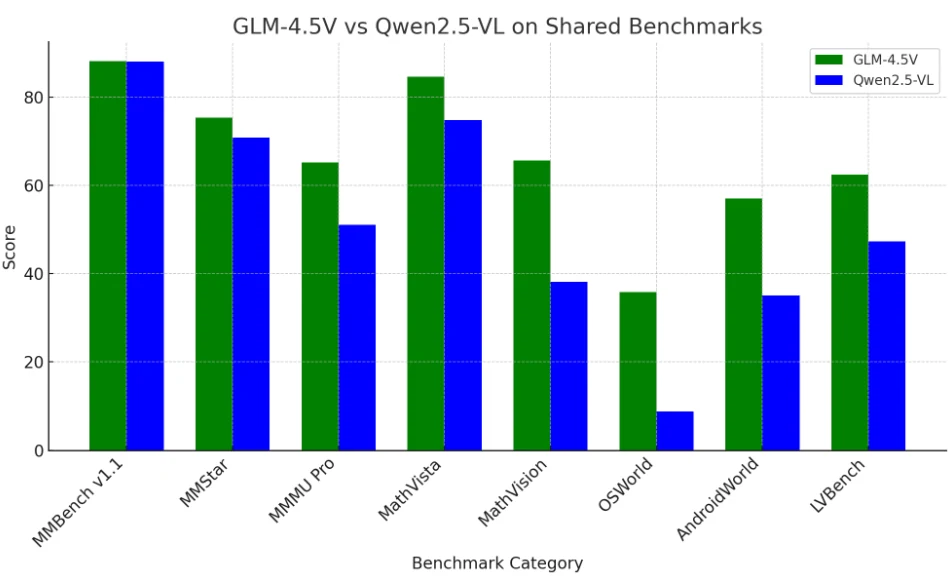
GLM-4.5V は現在、特に複雑で長文脈のマルチモーダルタスクにおいて全体的なベンチマーク性能でリードしていますが、Qwen2.5-VL も非常に競争力があり、かつては打ち負かすべき基準でした。
両モデルは他のほとんどのオープンソースLLMを凌駕しており、視覚言語分野ではクローズドソースの巨人に対しても強力な競争相手です。
GLM 4.5V と Qwen 2.5-VL の長所と短所

GLM 4.5V vs Qwen 2.5-VL:テキスト要約、チャットボット、画像ベースNLPにはどちらが適しているか?
テキスト要約:GLM-4.5V の勝利
長文書、レポート、マルチモーダルコンテンツの要約に関して、GLM-4.5V は明らかに優位です。128K のコンテキストウィンドウにより、切り詰めずに書籍全体や大規模な会話ログを処理できます。内蔵のチェイン・オブ・ソートモードにより、要約と同時にコンテンツの分析や推論も行えます。
Qwen 2.5-VL も要約に優れており、特に短めの記事や標準的な長さの文書で優れた性能を発揮します。クリーンで簡潔、よくフォーマットされた要約を生成し、中程度の長さのタスクでは高速です。ただし、特にテキスト+画像を含むヘビーデューティな要約には、GLM の方が適しています。
チャットボット:ニーズによる
**深い推論、長い記憶、段階的なタスク完了 ** が必要なチャットボットには、GLM-4.5V の方が強力です。ツールの使用や、コンテキストを忘れずに行える長い会話をサポートします。構造化された推論( thinking モード)により、複雑なクエリ をより適切に処理できます。
視覚チャットボット 、特に スクリーンショット、画像、レイアウト解析 を扱う場合は、Qwen 2.5-VL が優れています。画像を適切に理解し、構造化された回答(例:JSON)を提供し、 マルチターン視覚対話をサポートします。また、スムーズで丁寧な対話のために「箱から出してすぐに」より調整されている傾向があります。
画像ベースNLPタスク:Qwen2.5-VL がリード
画像から構造化データを抽出するタスク(OCR、フォーム理解、レイアウト認識など)では、Qwen 2.5-VL の方が強力なモデルです。
- バウンディングボックス検出 をサポートし、HTML や JSON での構造化レイアウト出力、複雑な視覚文書の解析が可能です。
- 多言語OCR と画像コンテンツの推論能力により、ビジネス向けの視覚NLPに非常に実用的です。
GLM-4.5V もこれらのタスクを処理できますが、典型的には視覚コンテンツを自由形式のテキストで記述するため、構造化フォーマットで出力するわけではなく、追加の後処理が必要になる場合があります。
Novita AI:よりコスト効率が高く安定した GLM 4.5V API プロバイダー
Novita AI の GLM-4.5V API は65.5Kコンテキストを提供し、入力価格は $0.60/1K トークン、出力価格は $1.80/1K トークン、関数呼び出しと構造化出力に対応しています。
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために無料トライアルを開始します。

ステップ4:APIキーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像に示されているように API キーをコピーします。

ステップ5:API をインストール
プログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。
インストール後、開発環境に必要なライブラリをインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。以下は Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # または False
max_tokens = 32768
system_content = "役立つアシスタントとして振る舞ってください"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "こんにちは!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
MCP と GLM を利用した簡単な画像認識ツールの構築
GLM の機能を活用して、視覚認識と推論の統合を実演する簡単な画像認識ツールを構築したい場合は、Novita AI がサポートする MCP 機能を使用できます。以下がサンプルコードです。
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
Novita API から利用可能なすべてのモデルを一覧表示します。
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\n"
text += f"Model description: {model['description']}\n"
text += f"Model type: {model['model_type']}\n\n"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
モデルIDとメッセージを指定して、Novita API から応答を取得します。
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
GLM-4.1V-9B-Thinking を使用して画像に関する質問に回答します。
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# stdio トランスポートを使用して実行
mcp.run(transport="stdio")
詳細については、こちらの記事をご確認ください:Novita AI で最初のMCPサーバーを構築する方法
これら2つのモデルを比較した結果、GLM 4.5V と Qwen 2.5-VL はどちらも非常に強力であることが明らかです。「より良い」モデルは実際に特定のユースケースと制約に依存します。最後に、残る実践的な質問に答える簡単なFAQを掲載します。
GLM-4.5V の主要なアーキテクチャ改善点は何ですか?
小型バージョン(≤13B)のみが単一GPUで実行可能で、フルサイズモデルにはマルチGPUセットアップまたはクラウド推論が必要です。
これらのモデルは英語と中国語以外の言語をサポートしていますか?
中核的な強みは英語と中国語ですが、他の言語も品質にばらつきはあるものの処理できます。
自分のタスクに合わせてこれらのモデルをファインチューニングできますか?
はい、両モデルとも LoRA などの手法を使用してファインチューニングまたは適応が可能ですが、大規模モデルにはかなりの計算リソースが必要です。
Novita AI は、AI の野望を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で始めて、AI ビジョンを現実にしましょう。



