

- GLM 4.5V and Qwen 2.5-VL: Key Architectural Differences
- GLM 4.5V and Qwen 2.5-VL: Benchmark Comparison
- Strengths and Weaknesses of GLM 4.5V and Qwen 2.5-VL
- GLM 4.5V vs Qwen 2.5-VL: Which is Better for Text Summarization, Chatbot,Image-Based NLP?
- Novita AI: More Cost-Effectvely and Stable GLM 4.5V API Provider
- Build a Simple Image Recognition Tool using MCP and GLM.
GLM 4.5V and Qwen 2.5-VL are two cutting-edge open-source vision-language models (VLMs) that have recently emerged from China’s AI community. Both models aim to push the state of the art in multimodal AI, combining natural language understanding with visual content analysis. In this blog post, we’ll compare GLM 4.5V and Qwen 2.5-VL across several dimensions important to developers
GLM 4.5V and Qwen 2.5-VL: Key Architectural Differences
| Feature | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Architecture Type | Mixture-of-Experts (MoE), 355B total params, ~32B active per token (Air: 106B total / 12B active) | Dense Transformer, all 72B parameters active for each token |
| Efficiency vs Capacity | High capacity with lower inference cost due to partial expert activation | Stable but high computational cost, all parameters used per input |
| Vision Encoder | Vision Transformer (ViT)-based, standard implementation | ViT with Window Attention, RMSNorm, and SwiGLU for more efficient high-resolution processing |
| Context Length | Up to 128K tokens (131K in some configs) | Up to 32K tokens |
GLM 4.5V and Qwen 2.5-VL: Training Data
1. Data Scale
| Category | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Text Tokens | ~23 trillion tokens total – 15T general – 8T reasoning/coding/agent tasks | Estimated ~18T+ tokens for 72B variant (based on scaling from earlier Qwen series) |
2.Data Types
| Category | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Text | Multilingual text, code, web text, reasoning prompts, agent-task data | General multilingual text, instructions, possibly preference-aligned prompts |
| Visual Data | Cleaned + re-captioned image-text pairs Academic diagrams, charts, math images GUI screenshots, PDFs, handwritten notes, multilingual OCR | Broad vision data Includes scanned forms, invoices, presentations, bounding box labels, OCR text |
| Video Data | Long-form videos with reasoning supervision | Videos with dynamic resolution and frame sampling |
3.Extra Capabilities & Training Techniques
| Category | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Reasoning Support | Trained with <think>...</think> chain-of-thought prompts interwoven with visual tasks | Reasoning is internal; no explicit chain-of-thought exposure |
| Fine-Tuning Approach | Reinforcement Learning with Curriculum Sampling (RLCS) across multiple domains: STEM, GUI, videos, documents | RLHF/RLAIF-like fine-tuning (not fully disclosed), applied to at least the 32B model, likely inherited in 72B |
| Multimodal Capabilities | Trained for agent tasks: reasoning over images, taking action (e.g., GUI interaction, tool usage) | Strong on structured outputs: OCR in JSON, layout parsing (QwenVL HTML), object detection with coordinates |
In summary, GLM 4.5V’s training emphasized quality and reasoning (curated data + explicit reasoning + multi-domain RL), whereas Qwen 2.5-VL’s training emphasized breadth and vision (broad data coverage + dynamic visual training + some RL alignment).
GLM 4.5v and Qwen 2.5-VL: Inference Latency Comparison
GLM 4.5V uses a Mixture-of-Experts (MoE) architecture, meaning only a small portion (~12B parameters) is active per token during inference, despite the model’s total size being over 100B.
This design allows it to run more efficiently, delivering speeds similar to a 12B–20B dense model, rather than behaving like a 72B+ dense model in terms of latency and throughput.
GLM 4.5V handles long contexts (up to 128K tokens) with lower latency growth, making it particularly suitable for tasks involving lengthy documents or multi-turn conversations.
GLM supports a special /nothink mode, which disables step-by-step reasoning when it’s not needed, enabling faster and more concise outputs.
Overall, GLM 4.5V offers excellent long-context inference efficiency and scalability, but requires strong hardware and smart deployment to achieve its full potential.
GLM 4.5V and Qwen 2.5-VL: Benchmark Comparison
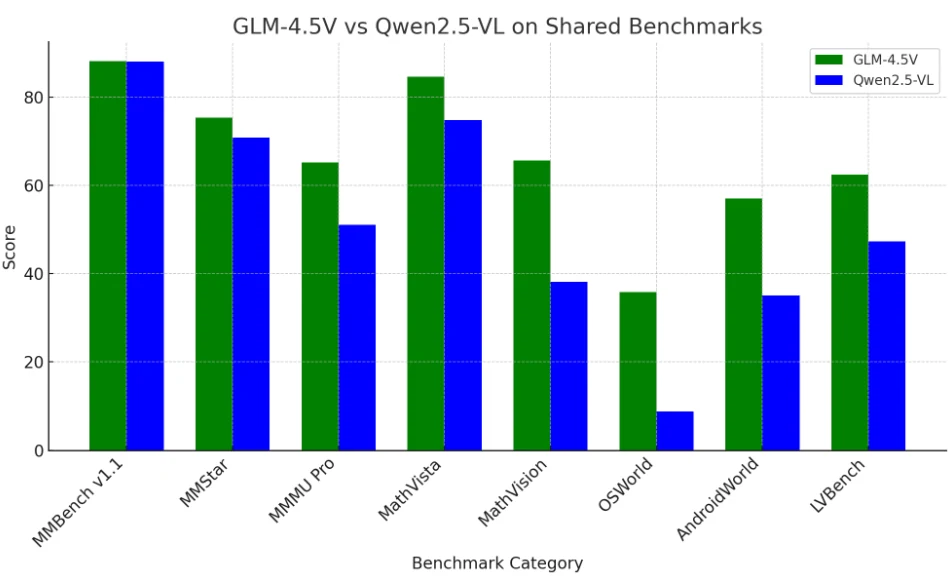
GLM-4.5V currently leads in overall benchmark performance, particularly in complex and long-context multimodal tasks,
but Qwen2.5-VL remains highly competitive and was previously the benchmark to beat.
Both models outperform most other open-source LLMs and are strong contenders even against closed-source giants in the vision-language space.
Strengths and Weaknesses of GLM 4.5V and Qwen 2.5-VL

Try GLM4.5V and Qwen 2.5VL Now!
GLM 4.5V vs Qwen 2.5-VL: Which is Better for Text Summarization, Chatbot,Image-Based NLP?
Text Summarization: GLM-4.5V wins
For summarizing long documents, reports, or multimodal content, GLM-4.5V has a clear edge. Its 128K context window allows it to handle entire books or large conversation logs without truncation. It can summarize while also analyzing or reasoning through the content, thanks to its built-in chain-of-thought mode.
Qwen 2.5-VL is also excellent at summarization, particularly for shorter articles or standard-length documents. It produces clean, concise, well-formatted summaries, and is faster for moderate-length tasks. However, for heavy-duty summarization, especially involving text + image, GLM is more capable.
Chatbots: Depends on needs
For chatbots requiring deep reasoning, long memory, and step-by-step task completion, GLM-4.5V is more powerful. It supports tool use and long conversations without forgetting context. Its structured reasoning (with <think> mode) enables better handling of complex queries.
For visual chatbots, especially those involving screenshots, images, or layout parsing, Qwen 2.5-VL excels. It understands images well, provides structured answers (e.g., in JSON), and supports multi-turn visual dialogue. It’s also slightly more aligned “out of the box” for smooth, polite interaction.
Image-Based NLP Tasks: Qwen2.5-VL leads
For tasks that involve extracting structured data from images, such as OCR, form understanding, or layout recognition, Qwen 2.5-VL is the stronger model.
- It supports bounding box detection, outputs structured layouts in HTML or JSON, and can parse complex visual documents.
- Its multi-language OCR and ability to reason over image content make it highly practical for business-facing visual NLP.
GLM-4.5V can also handle these tasks, but typically describes visual content in freeform text rather than structured formats, which may require more post-processing.
Novita AI: More Cost-Effectvely and Stable GLM 4.5V API Provider
Novita AI’s GLM-4.5V API offers 65.5K context, with input priced at $0.60/1K tokens, output at $1.80/1K tokens, and function calling and structured outputs supported.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Try GLM4.5V and Qwen 2.5VL Now!
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.

Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Build a Simple Image Recognition Tool using MCP and GLM.
If you want to leverage the capabilities of GLM—such as building a simple image recognition tool to demonstrate its integration of visual recognition and reasoning—you can use the MCP functionality supported by Novita AI. Below is the sample code:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")If you want to get the details, you can check out this article: How to Build Your First MCP Server with Novita AI!
Having compared these models, it’s clear both GLM 4.5V and Qwen 2.5-VL are extremely powerful. The “better” model truly depends on the specific use-case and constraints. We’ll conclude with a brief FAQ addressing some remaining practical questions:
What are the key architectural improvements in GLM-4.5V?
Only the smaller versions (≤13B) can run on a single GPU; the full-size models require multi-GPU setups or cloud inference.
Do these models support languages beyond English and Chinese?
Their core strength is in English and Chinese, but they can handle some other languages with variable quality.
Can I fine-tune these models for my task?
Yes, both can be fine-tuned or adapted using techniques like LoRA, but large models require significant compute.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



