

- GLM 4.5V y Qwen 2.5-VL: Diferencias arquitectónicas clave
- GLM 4.5V y Qwen 2.5-VL: Comparación de benchmarks
- Fortalezas y debilidades de GLM 4.5V y Qwen 2.5-VL
- GLM 4.5V vs Qwen 2.5-VL: ¿Cuál es mejor para resúmenes de texto, chatbots y PNL basada en imágenes?
- Novita AI: Proveedor de API GLM 4.5V más rentable y estable
- Crea una herramienta simple de reconocimiento de imágenes usando MCP y GLM.
GLM 4.5V y Qwen 2.5-VL son dos modelos de visión-lenguaje (VLM) de código abierto de última generación que han surgido recientemente de la comunidad china de IA. Ambos modelos buscan impulsar el estado del arte en IA multimodal, combinando comprensión del lenguaje natural con análisis de contenido visual. En esta publicación, compararemos GLM 4.5V y Qwen 2.5-VL en varias dimensiones importantes para desarrolladores.
GLM 4.5V y Qwen 2.5-VL: Diferencias arquitectónicas clave
| Característica | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Tipo de arquitectura | Mixture-of-Experts (MoE), 355B parámetros totales, ~32B activos por token (Air: 106B total / 12B activos) | Transformer denso, todos los 72B parámetros activos por cada token |
| Eficiencia vs. Capacidad | Alta capacidad con menor costo de inferencia debido a la activación parcial de expertos | Estable pero alto costo computacional, todos los parámetros usados por entrada |
| Codificador visual | Vision Transformer (ViT), implementación estándar | ViT con Atención de Ventana, RMSNorm y SwiGLU para un procesamiento de alta resolución más eficiente |
| Longitud de contexto | Hasta 128K tokens (131K en algunas configuraciones) | Hasta 32K tokens |
GLM 4.5V y Qwen 2.5-VL: Datos de entrenamiento
1. Escala de datos
| Categoría | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Tokens de texto | ~23 billones de tokens en total – 15T general – 8T razonamiento/codificación/tareas de agente |
Estimado ~18T+ tokens para la variante 72B (basado en escalado de la serie Qwen anterior) |
2. Tipos de datos
| Categoría | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Texto | Texto multilingüe, código, texto web, prompts de razonamiento, datos de tareas de agente | Texto multilingüe general, instrucciones, posiblemente prompts alineados con preferencias |
| Datos visuales | Pares imagen-texto limpiados y re-etiquetados Diagramas académicos, gráficos, imágenes matemáticas Capturas de pantalla de GUI, PDFs, notas manuscritas, OCR multilingüe |
Datos visuales amplios Incluye formularios escaneados, facturas, presentaciones, etiquetas de bounding boxes, texto OCR |
| Datos de video | Videos largos con supervisión de razonamiento | Videos con resolución dinámica y muestreo de cuadros |
3. Capacidades adicionales y técnicas de entrenamiento
| Categoría | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Soporte de razonamiento | Entrenado con prompts de cadena de pensamiento thinking... response entrelazados con tareas visuales |
El razonamiento es interno; sin exposición explícita a cadenas de pensamiento |
| Enfoque de ajuste fino | Reinforcement Learning with Curriculum Sampling (RLCS) en múltiples dominios: STEM, GUI, videos, documentos | Ajuste fino tipo RLHF/RLAIF (no totalmente revelado), aplicado al menos al modelo 32B, probablemente heredado en 72B |
| Capacidades multimodales | Entrenado para tareas de agente: razonar sobre imágenes, tomar acción (ej. interacción con GUI, uso de herramientas) | Fuerte en salidas estructuradas: OCR en JSON, análisis de diseño (QwenVL HTML), detección de objetos con coordenadas |
En resumen, el entrenamiento de GLM 4.5V enfatizó la calidad y el razonamiento (datos curados + razonamiento explícito + RL multidominio), mientras que el entrenamiento de Qwen 2.5-VL enfatizó la amplitud y la visión (amplia cobertura de datos + entrenamiento visual dinámico + algo de alineación RL).
GLM 4.5V y Qwen 2.5-VL: Comparación de latencia de inferencia
GLM 4.5V utiliza una arquitectura Mixture-of-Experts (MoE), lo que significa que solo una pequeña porción (~12B parámetros) está activa por token durante la inferencia, a pesar de que el tamaño total del modelo supera los 100B.
Este diseño le permite ejecutarse de manera más eficiente, ofreciendo velocidades similares a un modelo denso de 12B–20B, en lugar de comportarse como un modelo denso de 72B+ en términos de latencia y rendimiento.
GLM 4.5V maneja contextos largos (hasta 128K tokens) con un menor crecimiento de latencia, lo que lo hace particularmente adecuado para tareas que involucran documentos extensos o conversaciones de múltiples turnos.
GLM admite un modo especial /nothink, que desactiva el razonamiento paso a paso cuando no es necesario, permitiendo salidas más rápidas y concisas.
En general, GLM 4.5V ofrece una excelente eficiencia y escalabilidad de inferencia en contextos largos, pero requiere hardware potente y un despliegue inteligente para alcanzar su máximo potencial.
GLM 4.5V y Qwen 2.5-VL: Comparación de benchmarks
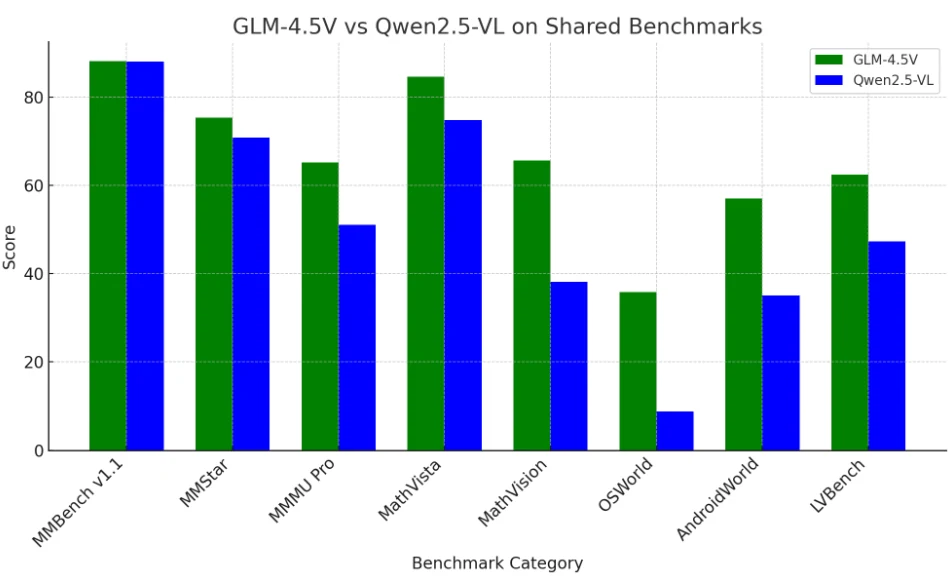
GLM-4.5V lidera actualmente en el rendimiento general de los benchmarks, particularmente en tareas multimodales complejas y de contexto largo,
pero Qwen2.5-VL sigue siendo altamente competitivo y anteriormente fue el benchmark a superar.
Ambos modelos superan a la mayoría de los LLM de código abierto y son fuertes contendientes incluso contra gigantes de código cerrado en el espacio de visión-lenguaje.
Fortalezas y debilidades de GLM 4.5V y Qwen 2.5-VL

¡Prueba GLM4.5V y Qwen 2.5VL ahora!
GLM 4.5V vs Qwen 2.5-VL: ¿Cuál es mejor para resúmenes de texto, chatbots y PNL basada en imágenes?
Resúmenes de texto: GLM-4.5V gana
Para resumir documentos largos, informes o contenido multimodal, GLM-4.5V tiene una clara ventaja. Su ventana de contexto de 128K le permite manejar libros completos o registros de conversaciones largas sin truncamiento. Puede resumir mientras también analiza o razona el contenido, gracias a su modo de cadena de pensamiento incorporado.
Qwen 2.5-VL también es excelente para resúmenes, particularmente para artículos cortos o documentos de longitud estándar. Produce resúmenes limpios, concisos y bien formateados, y es más rápido para tareas de longitud moderada. Sin embargo, para resúmenes pesados, especialmente aquellos que involucran texto + imagen, GLM es más capaz.
Chatbots: Depende de las necesidades
Para chatbots que requieren razonamiento profundo, memoria larga y finalización de tareas paso a paso, GLM-4.5V es más potente. Admite el uso de herramientas y conversaciones largas sin olvidar el contexto. Su razonamiento estructurado (con modo thinking) permite manejar mejor consultas complejas.
Para chatbots visuales, especialmente aquellos que involucran capturas de pantalla, imágenes o análisis de diseño, Qwen 2.5-VL sobresale. Entiende bien las imágenes, proporciona respuestas estructuradas (por ejemplo, en JSON) y admite diálogo visual de múltiples turnos. También está ligeramente más alineado “de fábrica” para una interacción fluida y educada.
Tareas de PNL basadas en imágenes: Qwen2.5-VL lidera
Para tareas que implican extraer datos estructurados de imágenes, como OCR, comprensión de formularios o reconocimiento de diseño, Qwen 2.5-VL es el modelo más fuerte.
- Admite detección de bounding boxes, genera diseños estructurados en HTML o JSON, y puede analizar documentos visuales complejos.
- Su OCR multilingüe y capacidad de razonar sobre el contenido de la imagen lo hacen muy práctico para PNL visual orientada a negocios.
GLM-4.5V también puede manejar estas tareas, pero típicamente describe el contenido visual en texto libre en lugar de formatos estructurados, lo que puede requerir más postprocesamiento.
Novita AI: Proveedor de API GLM 4.5V más rentable y estable
La API de GLM-4.5V de Novita AI ofrece un contexto de 65.5K, con entrada a $0.60/1K tokens, salida a $1.80/1K tokens, y admite llamadas a funciones y salidas estructuradas.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

¡Prueba GLM4.5V y Qwen 2.5VL ahora!
Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Crea una herramienta simple de reconocimiento de imágenes usando MCP y GLM.
Si deseas aprovechar las capacidades de GLM, como construir una herramienta simple de reconocimiento de imágenes para demostrar su integración de reconocimiento visual y razonamiento, puedes usar la funcionalidad MCP compatible con Novita AI. A continuación se muestra el código de ejemplo:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Si deseas obtener más detalles, puedes consultar este artículo: Cómo construir tu primer servidor MCP con Novita AI
Habiendo comparado estos modelos, está claro que tanto GLM 4.5V como Qwen 2.5-VL son extremadamente potentes. El modelo “mejor” realmente depende del caso de uso específico y las restricciones. Concluiremos con una breve sección de preguntas frecuentes que aborda algunas preguntas prácticas restantes:
¿Cuáles son las mejoras arquitectónicas clave en GLM-4.5V?
Solo las versiones más pequeñas (≤13B) pueden ejecutarse en una sola GPU; los modelos de tamaño completo requieren configuraciones de múltiples GPU o inferencia en la nube.
¿Estos modelos admiten idiomas además del inglés y el chino?
Su fortaleza principal está en inglés y chino, pero pueden manejar algunos otros idiomas con calidad variable.
¿Puedo ajustar estos modelos para mi tarea?
Sí, ambos se pueden ajustar o adaptar usando técnicas como LoRA, pero los modelos grandes requieren una capacidad de cómputo significativa.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, serverless, instancias de GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



