

- GLM 4.5V e Qwen 2.5-VL: Principais Diferenças Arquiteturais
- GLM 4.5V e Qwen 2.5-VL: Comparação de Benchmarks
- Pontos Fortes e Fracos do GLM 4.5V e Qwen 2.5-VL
- GLM 4.5V vs Qwen 2.5-VL: Qual é Melhor para Sumarização de Texto, Chatbot e PLN Baseado em Imagem?
- Novita AI: Provedor de API GLM 4.5V Mais Custo-Efetivo e Estável
- Construa uma Ferramenta Simples de Reconhecimento de Imagem usando MCP e GLM
GLM 4.5V e Qwen 2.5-VL são dois modelos de visão-linguagem (VLMs) de código aberto de ponta que surgiram recentemente da comunidade de IA da China. Ambos os modelos visam avançar o estado da arte em IA multimodal, combinando compreensão de linguagem natural com análise de conteúdo visual. Neste post de blog, compararemos GLM 4.5V e Qwen 2.5-VL em várias dimensões importantes para desenvolvedores.
GLM 4.5V e Qwen 2.5-VL: Principais Diferenças Arquiteturais
| Característica | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Tipo de Arquitetura | Mistura de Especialistas (MoE), 355B parâmetros totais, ~32B ativos por token (Air: 106B total / 12B ativos) | Transformer Denso, todos os 72B parâmetros ativos para cada token |
| Eficiência vs Capacidade | Alta capacidade com menor custo de inferência devido à ativação parcial de especialistas | Estável, mas alto custo computacional, todos os parâmetros usados por entrada |
| Codificador de Visão | Vision Transformer (ViT)-based, implementação padrão | ViT com Window Attention, RMSNorm e SwiGLU para processamento de alta resolução mais eficiente |
| Comprimento de Contexto | Até 128K tokens (131K em algumas configurações) | Até 32K tokens |
GLM 4.5V e Qwen 2.5-VL: Dados de Treinamento
1. Escala de Dados
| Categoria | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Tokens de Texto | ~23 trilhões de tokens no total – 15T gerais – 8T raciocínio/codificação/tarefas de agente |
Estimado ~18T+ tokens para variante 72B (baseado na escala das séries Qwen anteriores) |
2. Tipos de Dados
| Categoria | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Texto | Texto multilíngue, código, texto da web, prompts de raciocínio, dados de tarefas de agente | Texto multilíngue geral, instruções, possivelmente prompts alinhados por preferência |
| Dados Visuais | Pares imagem-texto limpos + com novas legendas Diagramas acadêmicos, gráficos, imagens matemáticas Capturas de tela de GUI, PDFs, notas manuscritas, OCR multilíngue |
Dados visuais amplos Inclui formulários escaneados, faturas, apresentações, rótulos de caixas delimitadoras, texto OCR |
| Dados de Vídeo | Vídeos longos com supervisão de raciocínio | Vídeos com resolução dinâmica e amostragem de quadros |
3. Capacidades Extras e Técnicas de Treinamento
| Categoria | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Suporte a Raciocínio | Treinado com prompts de cadeia de pensamento thinking... response entrelaçados com tarefas visuais |
Raciocínio é interno; nenhuma exposição explícita de cadeia de pensamento |
| Abordagem de Fine-Tuning | Aprendizagem por Reforço com Amostragem Curricular (RLCS) em vários domínios: STEM, GUI, vídeos, documentos | Fine-tuning do tipo RLHF/RLAIF (não totalmente divulgado), aplicado ao modelo de 32B, provavelmente herdado no 72B |
| Capacidades Multimodais | Treinado para tarefas de agente: raciocinar sobre imagens, executar ações (ex.: interação com GUI, uso de ferramentas) | Forte em saídas estruturadas: OCR em JSON, análise de layout (QwenVL HTML), detecção de objetos com coordenadas |
Em resumo, o treinamento do GLM 4.5V enfatizou qualidade e raciocínio (dados curados + raciocínio explícito + RL multi-domínio), enquanto o treinamento do Qwen 2.5-VL enfatizou amplitude e visão (ampla cobertura de dados + treinamento visual dinâmico + algum alinhamento RL).
GLM 4.5V e Qwen 2.5-VL: Comparação de Latência de Inferência
GLM 4.5V usa uma arquitetura Mistura de Especialistas (MoE), o que significa que apenas uma pequena parte (~12B parâmetros) está ativa por token durante a inferência, apesar do tamanho total do modelo ser superior a 100B.
Esse design permite que ele funcione de forma mais eficiente, oferecendo velocidades semelhantes a um modelo denso de 12B–20B, em vez de se comportar como um modelo denso de 72B+ em termos de latência e taxa de transferência.
O GLM 4.5V lida com contextos longos (até 128K tokens) com menor crescimento de latência, tornando-o particularmente adequado para tarefas que envolvem documentos extensos ou conversas de múltiplas voltas.
O GLM suporta um modo especial /nothink, que desativa o raciocínio passo a passo quando não é necessário, permitindo saídas mais rápidas e concisas.
No geral, o GLM 4.5V oferece excelente eficiência e escalabilidade de inferência para contextos longos, mas requer hardware potente e implantação inteligente para alcançar seu potencial máximo.
GLM 4.5V e Qwen 2.5-VL: Comparação de Benchmarks
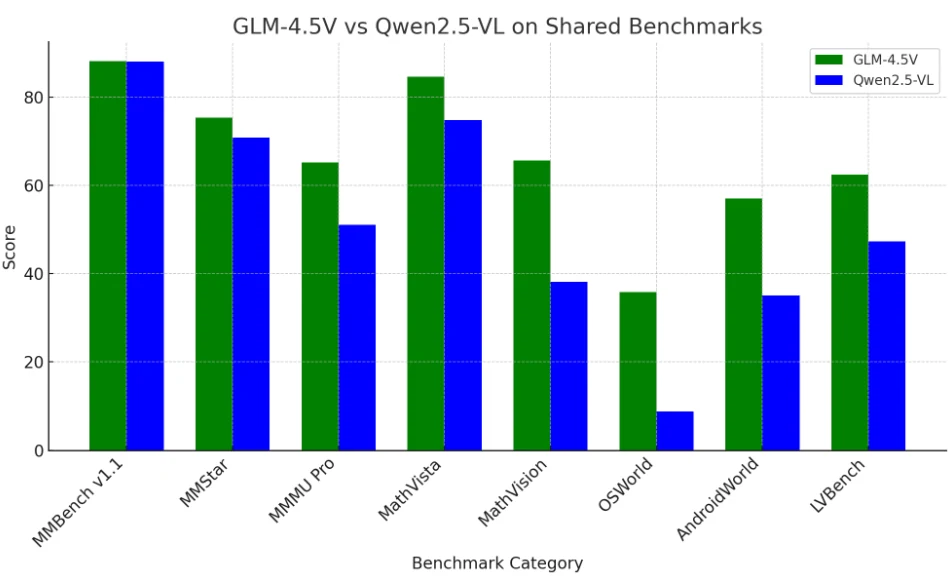
O GLM-4.5V atualmente lidera no desempenho geral de benchmarks, particularmente em tarefas multimodais complexas e de contexto longo,
mas o Qwen2.5-VL permanece altamente competitivo e foi anteriormente o benchmark a ser superado.
Ambos os modelos superam a maioria dos outros LLMs de código aberto e são fortes concorrentes mesmo contra gigantes de código fechado no espaço de visão-linguagem.
Pontos Fortes e Fracos do GLM 4.5V e Qwen 2.5-VL

Experimente GLM4.5V e Qwen 2.5VL Agora!
GLM 4.5V vs Qwen 2.5-VL: Qual é Melhor para Sumarização de Texto, Chatbot e PLN Baseado em Imagem?
Sumarização de Texto: GLM-4.5V vence
Para sumarizar documentos longos, relatórios ou conteúdo multimodal, o GLM-4.5V tem uma vantagem clara. Sua janela de contexto de 128K permite processar livros inteiros ou grandes registros de conversas sem truncamento. Ele pode sumarizar enquanto também analisa ou raciocina sobre o conteúdo, graças ao seu modo embutido de cadeia de pensamento.
O Qwen 2.5-VL também é excelente em sumarização, particularmente para artigos mais curtos ou documentos de comprimento padrão. Ele produz sumários limpos, concisos e bem formatados, e é mais rápido para tarefas de comprimento moderado. No entanto, para sumarização pesada, especialmente envolvendo texto + imagem, o GLM é mais capaz.
Chatbots: Depende das necessidades
Para chatbots que exigem raciocínio profundo, memória longa e conclusão de tarefas passo a passo, o GLM-4.5V é mais poderoso. Ele suporta uso de ferramentas e conversas longas sem esquecer o contexto. Seu raciocínio estruturado (com modo thinking) permite lidar melhor com consultas complexas.
Para chatbots visuais, especialmente aqueles que envolvem capturas de tela, imagens ou análise de layout, o Qwen 2.5-VL se destaca. Ele entende bem as imagens, fornece respostas estruturadas (por exemplo, em JSON) e suporta diálogo visual de múltiplas voltas. Também é ligeiramente mais alinhado “pronto para uso” para interação suave e educada.
Tarefas de PLN Baseadas em Imagem: Qwen2.5-VL lidera
Para tarefas que envolvem extrair dados estruturados de imagens, como OCR, compreensão de formulários ou reconhecimento de layout, o Qwen 2.5-VL é o modelo mais forte.
- Ele suporta detecção de caixas delimitadoras, gera layouts estruturados em HTML ou JSON e pode analisar documentos visuais complexos.
- Seu OCR multilíngue e capacidade de raciocinar sobre o conteúdo da imagem o tornam altamente prático para PLN visual voltado para negócios.
O GLM-4.5V também pode lidar com essas tarefas, mas tipicamente descreve o conteúdo visual em texto livre, em vez de formatos estruturados, o que pode exigir mais pós-processamento.
Novita AI: Provedor de API GLM 4.5V Mais Custo-Efetivo e Estável
A API GLM-4.5V da Novita AI oferece contexto de 65,5K, com entrada precificada a $0,60/1K tokens, saída a $1,80/1K tokens, e suporte a chamada de função e saídas estruturadas.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente GLM4.5V e Qwen 2.5VL Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.

Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entre na página “Settings” e copie a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Construa uma Ferramenta Simples de Reconhecimento de Imagem usando MCP e GLM
Se você deseja aproveitar as capacidades do GLM — como construir uma ferramenta simples de reconhecimento de imagem para demonstrar sua integração de reconhecimento visual e raciocínio — você pode usar a funcionalidade MCP suportada pela Novita AI. Abaixo está o código de exemplo:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Se você quiser obter os detalhes, confira este artigo: How to Build Your First MCP Server with Novita AI!
Após comparar esses modelos, fica claro que tanto o GLM 4.5V quanto o Qwen 2.5-VL são extremamente poderosos. O modelo “melhor” realmente depende do caso de uso específico e das restrições. Concluiremos com um breve FAQ abordando algumas perguntas práticas restantes:
Quais são as principais melhorias arquiteturais no GLM-4.5V?
Apenas as versões menores (≤13B) podem rodar em uma única GPU; os modelos de tamanho completo exigem configurações multi-GPU ou inferência em nuvem.
Esses modelos suportam idiomas além do inglês e chinês?
Seu ponto forte principal é inglês e chinês, mas eles podem lidar com alguns outros idiomas com qualidade variável.
Posso fazer fine-tuning desses modelos para minha tarefa?
Sim, ambos podem ser ajustados ou adaptados usando técnicas como LoRA, mas modelos grandes exigem poder computacional significativo.
Novita AI é a plataforma completa em nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas custo-efetivas que você precisa. Elimine infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



