

- GLM 4.5V و Qwen 2.5-VL: الاختلافات المعمارية الرئيسية
- GLM 4.5V و Qwen 2.5-VL: مقارنة المعايير
- نقاط القوة والضعف لـ GLM 4.5V و Qwen 2.5-VL
- GLM 4.5V مقابل Qwen 2.5-VL: أيهما أفضل لتلخيص النصوص، روبوتات المحادثة، معالجة اللغة الطبيعية المستندة إلى الصور؟
- Novita AI: مزود واجهة برمجة تطبيقات GLM 4.5V الأكثر فعالية من حيث التكلفة واستقراراً
- بناء أداة بسيطة للتعرف على الصور باستخدام MCP و GLM.
GLM 4.5V و Qwen 2.5-VL هما نموذجان مفتوحان متطوران للرؤية واللغة (VLM) ظهرا مؤخراً من مجتمع الذكاء الاصطناعي في الصين. يهدف كلا النموذجين إلى دفع حدود ما هو ممكن في الذكاء الاصطناعي متعدد الوسائط، من خلال الجمع بين فهم اللغة الطبيعية وتحليل المحتوى البصري. في هذه التدوينة، سنقارن بين GLM 4.5V و Qwen 2.5-VL عبر عدة أبعاد مهمة للمطورين.
GLM 4.5V و Qwen 2.5-VL: الاختلافات المعمارية الرئيسية
| الميزة | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| نوع البنية | خبراء مختلطون (MoE)، 355B معلمة إجمالاً، ~32B نشطة لكل رمز (Air: 106B إجمالاً / 12B نشطة) | محول كثيف (Dense Transformer)، جميع معلمات 72B نشطة لكل رمز |
| الكفاءة مقابل السعة | سعة عالية بتكلفة استدلال أقل بفضل تنشيط الخبراء الجزئي | مستقر ولكن بتكلفة حسابية عالية، جميع المعلمات مستخدمة لكل إدخال |
| مشفر الرؤية | محول الرؤية (ViT)، تطبيق قياسي | ViT مع انتباه النافذة (Window Attention)، RMSNorm، و SwiGLU لمعالجة عالية الدقة أكثر كفاءة |
| طول السياق | حتى 128 ألف رمز (131 ألف في بعض الإعدادات) | حتى 32 ألف رمز |
GLM 4.5V و Qwen 2.5-VL: بيانات التدريب
1. حجم البيانات
| الفئة | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| رموز النص | ~23 تريليون رمز إجمالاً – 15 تريليون عام – 8 تريليون للاستدلال/البرمجة/المهام الوكيلة |
تقديرياً ~18 تريليون+ رمز لمتغير 72B (بناءً على التوسع من سلسلة Qwen السابقة) |
2. أنواع البيانات
| الفئة | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| النص | نصوص متعددة اللغات، كود، نصوص ويب، مطالبات استدلال، بيانات مهام وكيلة | نصوص متعددة اللغات عامة، تعليمات، ربما مطالبات محاذاة التفضيلات |
| البيانات البصرية | أزواج صور-نص منقحة ومعاد تعليقها رسوم بيانية أكاديمية، مخططات، صور رياضية لقطات شاشة لواجهات المستخدم، ملفات PDF، ملاحظات مكتوبة بخط اليد، OCR متعدد اللغات |
بيانات بصرية واسعة تشمل نماذج ممسوحة ضوئياً، فواتير، عروض تقديمية، تسميات صناديق إحاطة، نصوص OCR |
| بيانات الفيديو | فيديوهات طويلة مع إشراف استدلالي | فيديوهات بدقة ديناميكية وأخذ عينات إطارات |
3. قدرات إضافية وتقنيات تدريب
| الفئة | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| دعم الاستدلال | مدرب على مطالبات سلسلة الأفكار thinking... response المتداخلة مع المهام البصرية |
الاستدلال داخلي؛ لا يوجد تعرض صريح لسلسلة الأفكار |
| نهج الضبط الدقيق | تعزيز التعلم بأخذ العينات المنهجية (RLCS) عبر مجالات متعددة: STEM، واجهات المستخدم، الفيديوهات، المستندات | ضبط دقيق مشابه لـ RLHF/RLAIF (غير معلن بالكامل)، طبق على الأقل على نموذج 32B، ومن المحتمل توريثه في 72B |
| القدرات متعددة الوسائط | مدرب للمهام الوكيلة: الاستدلال على الصور، اتخاذ إجراءات (مثل التفاعل مع واجهات المستخدم، استخدام الأدوات) | قوي على المخرجات المنظمة: OCR في JSON، تحليل التخطيط (QwenVL HTML)، اكتشاف الكائنات بالإحداثيات |
باختصار، ركز تدريب GLM 4.5V على الجودة والاستدلال (بيانات منقحة + استدلال صريح + تعزيز التعلم متعدد المجالات)، بينما ركز تدريب Qwen 2.5-VL على الشمولية والرؤية (تغطية بيانات واسعة + تدريب بصري ديناميكي + بعض محاذاة التعزيز).
GLM 4.5v و Qwen 2.5-VL: مقارنة زمن الاستدلال
يستخدم GLM 4.5V بنية الخبراء المختلطين (MoE)، مما يعني أن جزءاً صغيراً فقط (~12B معلمة) يكون نشطاً لكل رمز أثناء الاستدلال، على الرغم من أن الحجم الإجمالي للنموذج يتجاوز 100B.
يسمح هذا التصميم له بالعمل بكفاءة أكبر، مما يحقق سرعات مشابهة لنموذج كثيف 12B–20B، بدلاً من التصرف كنموذج كثيف 72B+ من حيث زمن الاستجابة والإنتاجية.
يتعامل GLM 4.5V مع السياقات الطويلة (حتى 128 ألف رمز) بنمو زمن استجابة أقل، مما يجعله مناسباً بشكل خاص للمهام التي تتضمن مستندات طويلة أو محادثات متعددة الأدوار.
يدعم GLM وضعاً خاصاً /nothink، يعطل الاستدلال خطوة بخطوة عندما لا يكون ضرورياً، مما يمكن من مخرجات أسرع وأكثر إيجازاً.
بشكل عام، يقدم GLM 4.5V كفاءة استدلال ممتازة للسياقات الطويلة وقابلية توسع جيدة، ولكنه يتطلب أجهزة قوية ونشراً ذكياً لتحقيق إمكاناته الكاملة.
GLM 4.5V و Qwen 2.5-VL: مقارنة المعايير
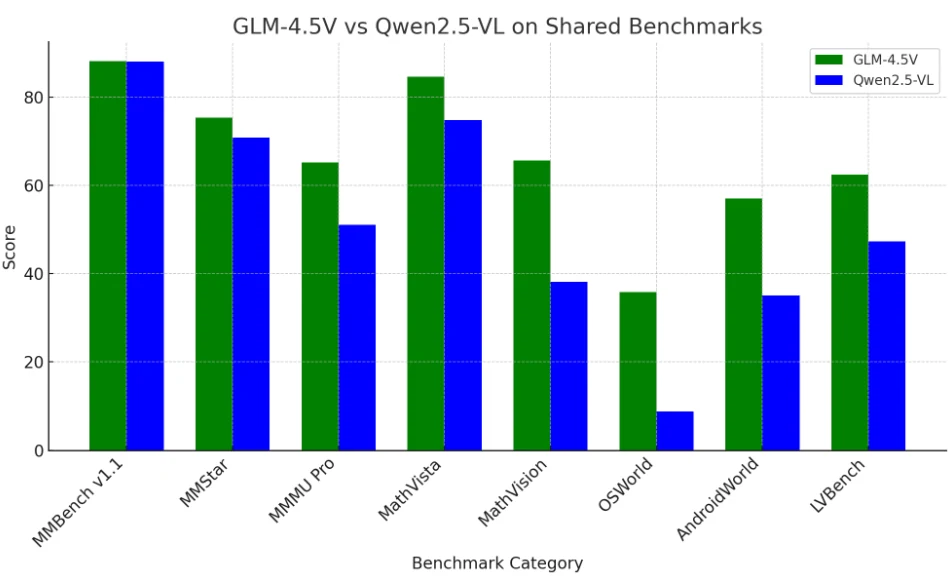
يتصدر GLM-4.5V حالياً أداء المعايير بشكل عام، خاصة في المهام متعددة الوسائط المعقدة والطويلة السياق،
لكن يظل Qwen2.5-VL تنافسياً للغاية وكان سابقاً المعيار الذي يجب التغلب عليه.
يتفوق كلا النموذجين على معظم نماذج LLM مفتوحة المصدر الأخرى، وهما منافسان قويان حتى ضد العمالقة مغلقي المصدر في مجال الرؤية واللغة.
نقاط القوة والضعف لـ GLM 4.5V و Qwen 2.5-VL

جرب GLM4.5V و Qwen 2.5VL الآن!
GLM 4.5V مقابل Qwen 2.5-VL: أيهما أفضل لتلخيص النصوص، روبوتات المحادثة، معالجة اللغة الطبيعية المستندة إلى الصور؟
تلخيص النصوص: يفوز GLM-4.5V
لتلخيص المستندات الطويلة أو التقارير أو المحتوى متعدد الوسائط، يتمتع GLM-4.5V بميزة واضحة. نافذة السياق البالغة 128 ألف رمز تسمح له بمعالجة كتب كاملة أو سجلات محادثة طويلة دون اقتطاع. يمكنه التلخيص مع التحليل أو الاستدلال على المحتوى في نفس الوقت، بفضل وضع سلسلة الأفكار المدمج.
Qwen 2.5-VL ممتاز أيضاً في التلخيص، خاصة للمقالات القصيرة أو المستندات ذات الطول القياسي. ينتج ملخصات نظيفة وموجزة ومنسقة جيداً، وهو أسرع للمهام ذات الطول المتوسط. ومع ذلك، بالنسبة للتلخيص الثقيل، خاصة الذي يتضمن نص + صورة، فإن GLM أكثر قدرة.
روبوتات المحادثة: يعتمد على الاحتياجات
بالنسبة لروبوتات المحادثة التي تتطلب استدلالاً عميقاً، ذاكرة طويلة، وإتمام مهام خطوة بخطوة، فإن GLM-4.5V أقوى. يدعم استخدام الأدوات والمحادثات الطويلة دون نسيان السياق. استدلاله المنظم (مع وضع thinking) يمكّن من معالجة أفضل للاستفسارات المعقدة.
بالنسبة لـ روبوتات المحادثة البصرية، خاصة تلك التي تتضمن لقطات شاشة، صور، أو تحليل تخطيط، يتفوق Qwen 2.5-VL. يفهم الصور جيداً، ويقدم إجابات منظمة (مثل JSON)، ويدعم الحوار البصري متعدد الأدوار. كما أنه أكثر توافقاً “خارج الصندوق” للتفاعل السلس والمهذب.
مهام معالجة اللغة الطبيعية المستندة إلى الصور: يتصدر Qwen2.5-VL
بالنسبة للمهام التي تتضمن استخراج بيانات منظمة من الصور، مثل OCR، فهم النماذج، أو التعرف على التخطيط، فإن Qwen 2.5-VL هو النموذج الأقوى.
- يدعم اكتشاف صناديق الإحاطة، ويخرج تخطيطات منظمة بصيغة HTML أو JSON، ويمكنه تحليل المستندات البصرية المعقدة.
- OCR متعدد اللغات وقدرته على الاستدلال على محتوى الصورة تجعله عملياً جداً لمعالجة اللغة الطبيعية البصرية الموجهة للأعمال.
يمكن لـ GLM-4.5V أيضاً التعامل مع هذه المهام، لكنه عادةً ما يصف المحتوى البصري في نص حر بدلاً من صيغ منظمة، مما قد يتطلب معالجة لاحقة إضافية.
Novita AI: مزود واجهة برمجة تطبيقات GLM 4.5V الأكثر فعالية من حيث التكلفة واستقراراً
توفر واجهة برمجة تطبيقات GLM-4.5V من Novita AI سياقاً يصل إلى 65.5 ألف رمز، بسعر إدخال $0.60/1000 رمز، وإخراج $1.80/1000 رمز، مع دعم استدعاء الوظائف والمخرجات المنظمة.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرب GLM4.5V و Qwen 2.5VL الآن!
الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ نسختك التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.

الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنوفر لك مفتاح API جديد. ادخل إلى صفحة “الإعدادات” وانسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: قم بتثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام chat completions API لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
بناء أداة بسيطة للتعرف على الصور باستخدام MCP و GLM.
إذا كنت ترغب في الاستفادة من إمكانيات GLM—مثل بناء أداة بسيطة للتعرف على الصور لتوضيح تكامل التعرف البصري والاستدلال—يمكنك استخدام وظيفة MCP التي تدعمها Novita AI. فيما يلي نموذج الكود:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
إذا كنت تريد التفاصيل، يمكنك الاطلاع على هذه المقالة: كيفية بناء أول خادم MCP لك مع Novita AI!
بعد مقارنة هذه النماذج، من الواضح أن كلاً من GLM 4.5V و Qwen 2.5-VL قويان للغاية. النموذج “الأفضل” يعتمد حقاً على حالة الاستخدام والقيود المحددة. سنختتم بأسئلة شائعة قصيرة تتناول بعض الأسئلة العملية المتبقية:
ما هي التحسينات المعمارية الرئيسية في GLM-4.5V؟
فقط الإصدارات الأصغر (≤13B) يمكنها العمل على GPU واحد؛ النماذج بالحجم الكامل تتطلب إعدادات GPU متعددة أو استدلال سحابي.
هل تدعم هذه النماذج لغات أخرى غير الإنجليزية والصينية؟
قوتها الأساسية تكمن في الإنجليزية والصينية، لكنها تستطيع التعامل مع بعض اللغات الأخرى بجودة متفاوتة.
هل يمكنني ضبط هذه النماذج بدقة لمهمتي؟
نعم، يمكن ضبط كليهما بدقة أو تكييفهما باستخدام تقنيات مثل LoRA، ولكن النماذج الكبيرة تتطلب قدرة حسابية كبيرة.
Novita AI هي المنصة السحابية الشاملة التي تمكّن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيل GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، وابدأ مجاناً، واجعل رؤيتك للذكاء الاصطناعي حقيقة.



