

- GLM 4.5V и Qwen 2.5-VL: ключевые архитектурные различия
- GLM 4.5V и Qwen 2.5-VL: сравнение бенчмарков
- Сильные и слабые стороны GLM 4.5V и Qwen 2.5-VL
- GLM 4.5V против Qwen 2.5-VL: что лучше для суммаризации текста, чат-ботов и NLP на основе изображений?
- Novita AI: более экономичный и стабильный API-провайдер GLM 4.5V
- Создайте простой инструмент распознавания изображений с помощью MCP и GLM.
GLM 4.5V и Qwen 2.5-VL — это две передовые открытые модели «зрение-язык» (VLM), недавно появившиеся в китайском AI-сообществе. Обе модели нацелены на продвижение современного уровня в мультимодальном ИИ, объединяя понимание естественного языка с анализом визуального контента. В этой статье мы сравним GLM 4.5V и Qwen 2.5-VL по нескольким ключевым для разработчиков параметрам.
GLM 4.5V и Qwen 2.5-VL: ключевые архитектурные различия
| Характеристика | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Тип архитектуры | Mixture-of-Experts (MoE), 355B параметров всего, ~32B активных на токен (Air: 106B всего / 12B активных) | Плотный Transformer, все 72B параметров активны для каждого токена |
| Эффективность vs Ёмкость | Высокая ёмкость с меньшей стоимостью инференса благодаря частичной активации экспертов | Стабильная, но высокая вычислительная стоимость, все параметры используются на каждый вход |
| Визуальный энкодер | На основе Vision Transformer (ViT), стандартная реализация | ViT с Window Attention, RMSNorm и SwiGLU для более эффективной обработки высокого разрешения |
| Длина контекста | До 128K токенов (в некоторых конфигурациях 131K) | До 32K токенов |
GLM 4.5V и Qwen 2.5-VL: обучающие данные
1. Масштаб данных
| Категория | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Текстовые токены | ~23 триллиона токенов всего – 15T общих – 8T для рассуждений/кода/агентных задач |
Оценка ~18T+ токенов для варианта 72B (на основе масштабирования из более ранних серий Qwen) |
2. Типы данных
| Категория | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Текст | Многоязычный текст, код, веб-текст, промпты для рассуждений, данные для агентных задач | Общий многоязычный текст, инструкции, возможно, промпты с выравниванием предпочтений |
| Визуальные данные | Очищенные + повторно подписанные пары изображение-текст Академические схемы, диаграммы, математические изображения Скриншоты GUI, PDF, рукописные заметки, многоязычный OCR |
Широкие визуальные данные Включают отсканированные формы, счета, презентации, метки ограничивающих рамок, OCR-текст |
| Видеоданные | Длинные видео с контролем рассуждений | Видео с динамическим разрешением и сэмплированием кадров |
3. Дополнительные возможности и техники обучения
| Категория | GLM 4.5V | Qwen 2.5-VL |
|---|---|---|
| Поддержка рассуждений | Обучен с использованием промптов в стиле «цепочка мыслей» thinking... response, переплетённых с визуальными задачами |
Рассуждения внутренние; явное использование цепочки мыслей не раскрыто |
| Подход к точной настройке | Обучение с подкреплением с помощью Curriculum Sampling (RLCS) в нескольких доменах: STEM, GUI, видео, документы | RLHF/RLAIF-подобная тонкая настройка (не полностью раскрыта), применена как минимум к модели 32B, вероятно, унаследована в 72B |
| Мультимодальные возможности | Обучен для агентных задач: рассуждение на основе изображений, выполнение действий (например, взаимодействие с GUI, использование инструментов) | Сильные стороны в структурированных выводах: OCR в JSON, разбор макетов (QwenVL HTML), обнаружение объектов с координатами |
В целом, обучение GLM 4.5V делало упор на качество и рассуждения (курированные данные + явное рассуждение + многодоменное RL), тогда как обучение Qwen 2.5-VL — на широту и зрение (широкий охват данных + динамическое визуальное обучение + частичное RL-выравнивание).
GLM 4.5V и Qwen 2.5-VL: сравнение задержки инференса
GLM 4.5V использует архитектуру Mixture-of-Experts (MoE), что означает, что во время инференса активна лишь малая часть параметров (~12B) на каждый токен, несмотря на общий размер модели более 100B.
Такая конструкция позволяет ему работать более эффективно, обеспечивая скорость, аналогичную плотной модели размером 12–20B, а не 72B+ по задержке и пропускной способности.
GLM 4.5V обрабатывает длинные контексты (до 128K токенов) с меньшим ростом задержки, что делает его особенно подходящим для задач, связанных с длинными документами или многоповоротными диалогами.
GLM поддерживает специальный режим /nothink, который отключает пошаговые рассуждения, когда они не нужны, обеспечивая более быстрый и краткий вывод.
В целом, GLM 4.5V предлагает отличную эффективность инференса для длинных контекстов и масштабируемость, но требует мощного оборудования и грамотного развёртывания для достижения полного потенциала.
GLM 4.5V и Qwen 2.5-VL: сравнение бенчмарков
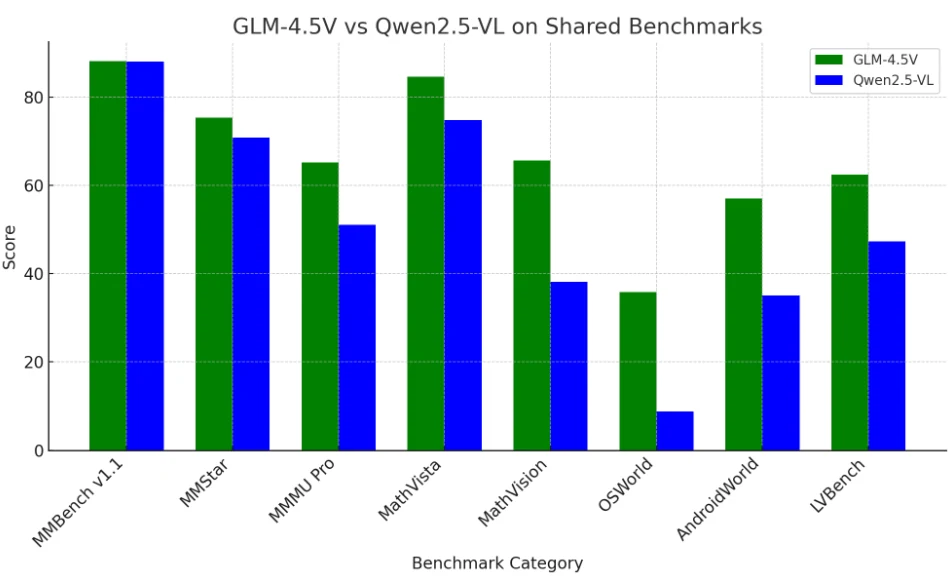
В настоящее время GLM-4.5V лидирует по общей производительности на бенчмарках, особенно в сложных и длинноконтекстных мультимодальных задачах,
но Qwen2.5-VL остаётся очень конкурентоспособным и ранее был эталоном, который нужно было превзойти.
Обе модели превосходят большинство других открытых LLM и являются сильными конкурентами даже для закрытых гигантов в области зрение-язык.
Сильные и слабые стороны GLM 4.5V и Qwen 2.5-VL

Попробуйте GLM4.5V и Qwen 2.5VL сейчас!
GLM 4.5V против Qwen 2.5-VL: что лучше для суммаризации текста, чат-ботов и NLP на основе изображений?
Суммаризация текста: побеждает GLM-4.5V
Для суммаризации длинных документов, отчётов или мультимодального контента GLM-4.5V имеет явное преимущество. Окно контекста в 128K позволяет обрабатывать целые книги или большие журналы диалогов без обрезания. Он может обобщать, одновременно анализируя или рассуждая о содержимом, благодаря встроенному режиму цепочки мыслей.
Qwen 2.5-VL также отлично справляется с суммаризацией, особенно для коротких статей или документов стандартной длины. Он выдаёт чистые, краткие, хорошо отформатированные сводки и быстрее для задач средней длины. Однако для задач с высокой нагрузкой, особенно включающих текст + изображение, GLM более способен.
Чат-боты: зависит от потребностей
Для чат-ботов, требующих глубоких рассуждений, длинной памяти и пошагового выполнения задач, GLM-4.5V более мощный. Он поддерживает использование инструментов и длинные диалоги без потери контекста. Его структурированные рассуждения (с режимом thinking) позволяют лучше справляться со сложными запросами.
Для визуальных чат-ботов, особенно связанных с скриншотами, изображениями или разбором макетов, Qwen 2.5-VL превосходит. Он хорошо понимает изображения, даёт структурированные ответы (например, в JSON) и поддерживает многоповоротный визуальный диалог. Кроме того, он немного более выровнен «из коробки» для плавного, вежливого взаимодействия.
NLP-задачи на основе изображений: лидирует Qwen2.5-VL
Для задач, связанных с извлечением структурированных данных из изображений, таких как OCR, понимание форм или распознавание макетов, Qwen 2.5-VL является более сильной моделью.
- Он поддерживает обнаружение ограничивающих рамок, выводит структурированные макеты в HTML или JSON и может анализировать сложные визуальные документы.
- Его многоязычный OCR и способность рассуждать о содержимом изображения делают его очень практичным для бизнес-ориентированного визуального NLP.
GLM-4.5V также может справляться с этими задачами, но обычно описывает визуальное содержимое в виде свободного текста, а не структурированных форматов, что может потребовать дополнительной постобработки.
Novita AI: более экономичный и стабильный API-провайдер GLM 4.5V
API GLM-4.5V от Novita AI предлагает контекст 65.5K, цена входа — $0.60/1K токенов, выхода — $1.80/1K токенов, поддерживается вызов функций и структурированный вывод.
Шаг 1: Войдите и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library.

Попробуйте GLM4.5V и Qwen 2.5VL сейчас!
Шаг 2: Выберите свою модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших задач.

Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.

Шаг 4: Получите свой API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдите на страницу «Settings» и скопируйте ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, подходящего для вашего языка программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим ключом, чтобы начать взаимодействие с Novita AI LLM. Вот пример использования chat completions API для Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Создайте простой инструмент распознавания изображений с помощью MCP и GLM.
Если вы хотите использовать возможности GLM, например, создать простой инструмент распознавания изображений, демонстрирующий интеграцию визуального распознавания и рассуждений, вы можете воспользоваться функциональностью MCP, поддерживаемой Novita AI. Пример кода ниже:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Если вы хотите узнать подробности, можете ознакомиться с этой статьёй: Как создать свой первый MCP-сервер с помощью Novita AI!
Сравнив эти модели, становится ясно, что и GLM 4.5V, и Qwen 2.5-VL чрезвычайно мощны. «Лучшая» модель действительно зависит от конкретного случая использования и ограничений. Мы завершим кратким разделом часто задаваемых вопросов, освещающим некоторые оставшиеся практические вопросы:
Каковы ключевые архитектурные улучшения в GLM-4.5V?
Только меньшие версии (≤13B) могут работать на одном GPU; полноразмерные модели требуют многопроцессорных конфигураций GPU или облачного инференса.
Поддерживают ли эти модели языки, кроме английского и китайского?
Их основная сила — в английском и китайском, но они могут обрабатывать некоторые другие языки с переменным качеством.
Могу ли я дообучить эти модели для своей задачи?
Да, обе модели можно дообучать или адаптировать с помощью таких техник, как LoRA, но большие модели требуют значительных вычислительных ресурсов.
Novita AI — это универсальная облачная платформа, которая даёт волю вашим AI-амбициям. Интегрированные API, Serverless, GPU Instance — экономичные инструменты, которые вам нужны. Устраните инфраструктуру, начните бесплатно и воплотите своё AI-видение в реальность.



