

- Was ist Qwen3-VL-30B-A3B?
- Hauptfunktionen und Verbesserungen
- Modellarchitektur und Spezifikationen
- Qwen3-VL-30B-A3B-Instruct vs Qwen3-VL-30B-A3B-Thinking
- Leistungs-Benchmarks
- Kernfunktionen
- Praxisanwendungen
- Erste Schritte mit Qwen3-VL-30B-A3B auf der Novita AI-Plattform
- Probieren Sie Qwen3-VL-30B-A3B noch heute aus
Qwen3-VL-30B-A3B verarbeitet Bilder, Dokumente und Videos neben Text mit 30 Milliarden Parametern. Das Modell bewältigt alles von OCR in 32 Sprachen bis hin zu stundenlangen Videoanalysen mit 256K Kontext.
Novita AI hostet zwei Varianten. Instruct liefert schnelle, direkte Antworten. Thinking zeigt seinen Schlussfolgerungsprozess für komplexe Aufgaben. Greifen Sie über den Playground oder die API auf beide zu.
Probieren Sie die Qwen3-VL-30B-A3B Demo aus
Was ist Qwen3-VL-30B-A3B?
Qwen3-VL-30B-A3B stammt vom Qwen-Team von Alibaba Cloud. Das Modell läuft auf MoE-Architektur (Mixture-of-Experts) mit 30,5 Milliarden Gesamtparametern und 3,3 Milliarden aktivierten. Dieses Design liefert starke Leistung bei gleichzeitig überschaubaren Kosten.
Das Modell positioniert sich zwischen den kleineren Qwen3-VL-Varianten und dem Flaggschiff Qwen3-VL-235B-A22B, und balanciert Fähigkeiten mit Effizienz. Während das 235B-Modell bei den anspruchsvollsten Schlussfolgerungsaufgaben glänzt, bietet die 30B-Variante ähnliche Fähigkeiten zu niedrigeren Kosten und schnelleren Inferenzgeschwindigkeiten.
Wichtige Upgrades umfassen:
- Natives 256K Kontext, erweiterbar auf 1M Token
- OCR-Unterstützung für 32 Sprachen (vorher 19)
- 2D- und 3D-räumliches Grounding
- GUI-Interaktionsfähigkeiten
- Codegenerierung aus visuellen Eingaben
- Videoverständnis mit Sekunden-indexierung
Zwei Varianten bedienen unterschiedliche Anforderungen: Instruct ist auf Geschwindigkeit ausgelegt, Thinking bewältigt komplexe Schlussfolgerungsaufgaben.
Hauptfunktionen und Verbesserungen
Visuelle Agent-Fähigkeiten
Das Modell erkennt Oberflächenelemente und führt Aufgaben auf PC- und mobilen GUIs aus. Es versteht, was Buttons tun und wie man durch Anwendungen navigiert.
Visuelle Codegenerierung
Zeigen Sie Qwen3-VL einen Screenshot und erhalten Sie funktionsfähigen Code. Das Modell generiert Draw.io-Diagramme, HTML, CSS und JavaScript aus Bildern und Videos.
Räumliche Wahrnehmung
Das Modell beurteilt Objektpositionen, Blickwinkel und Verdeckungen. Es bietet 2D-Grounding und ermöglicht 3D-Grounding für räumliche Schlussfolgerungen und Anwendungen im Bereich der embodied KI.
Erweiterter Kontext für lange Videos
Natives 256K Kontext, erweiterbar auf 1M Token. Das Modell verarbeitet Bücher und stundenlange Videos mit vollständigem Abruf. Die Sekunden-indexierung ermöglicht es Ihnen, bestimmte Momente abzufragen.
Fortschrittliche OCR
OCR unterstützt jetzt 32 Sprachen. Das Modell arbeitet bei schwachem Licht, verarbeitet Unschärfe und Neigung, liest seltene und alte Schriftzeichen und parsiert lange Dokumente unter Beibehaltung der Struktur.
STEM- und Mathematik-Schlussfolgerung
Das Modell glänzt bei Kausalanalyse und evidenzbasierten Antworten für Probleme aus Naturwissenschaften, Technik, Ingenieurwesen und Mathematik.
Erweiterte Erkennung
Breiteres Vortraining ermöglicht es dem Modell, Prominente, Anime-Charaktere, Produkte, Wahrzeichen, Pflanzen und Tiere zu erkennen.
Modellarchitektur und Spezifikationen
Architektur: Qwen3VLMoeForConditionalGeneration mit integriertem ViT-basiertem Vision-Encoder
Kernspezifikationen:
- Gesamtparameter: 30,5B
- Aktivierte Parameter: 3,3B
- Kontextlänge: 256K Token (nativ), erweiterbar auf 1M
- Unterstützte Formate: JPEG, PNG, WebP, BMP, Video
Drei architektonische Innovationen:
Interleaved-MRoPE weist volle Frequenz über Zeit, Breite und Höhe durch Positions-Einbettungen zu. Dies verbessert die Schlussfolgerung über lange Zeiträume bei Videos.
DeepStack fusioniert mehrstufige ViT-Funktionen, um feine Details zu erfassen und die Bild-Text-Ausrichtung zu schärfen.
Text-Timestamp Alignment bietet präzise, zeitstempelverankerte Ereignislokalisierung für stärkere zeitliche Videomodellierung.
Qwen3-VL-30B-A3B-Instruct vs Qwen3-VL-30B-A3B-Thinking
Instruct: Schnell und direkt
Die Instruct-Variante antwortet sofort, ohne ihren Arbeitsweg zu zeigen. Sie ist auf Geschwindigkeit und Durchsatz optimiert.
Anwendungsfälle:
- Echtzeit-Bildklassifizierung
- Dokument-OCR und Textextraktion
- Inhaltsmoderation im großen Maßstab
- Hochvolumige API-Aufrufe
- Einfache visuelle Q&A
Thinking: Detaillierte Schlussfolgerung
Die Thinking-Variante zeigt schrittweise Analysen vor der Antwort. Sie zerlegt komplexe Probleme in logische Schritte, ähnlich wie die größere Qwen3-VL-235B-A22B Thinking-Variante.
Anwendungsfälle:
- Mathematikprobleme aus Bildern
- Mehrstufige visuelle Schlussfolgerung
- Analyse wissenschaftlicher Dokumente
- Bildungsanwendungen
- Aufgaben, die Erklärbarkeit erfordern
Wählen Sie Instruct für die meisten Produktionsworkloads. Wechseln Sie zu Thinking, wenn Sie transparente Schlussfolgerungen benötigen oder komplexe analytische Aufgaben bearbeiten.
Leistungs-Benchmarks
Ergebnisse der Thinking-Variante
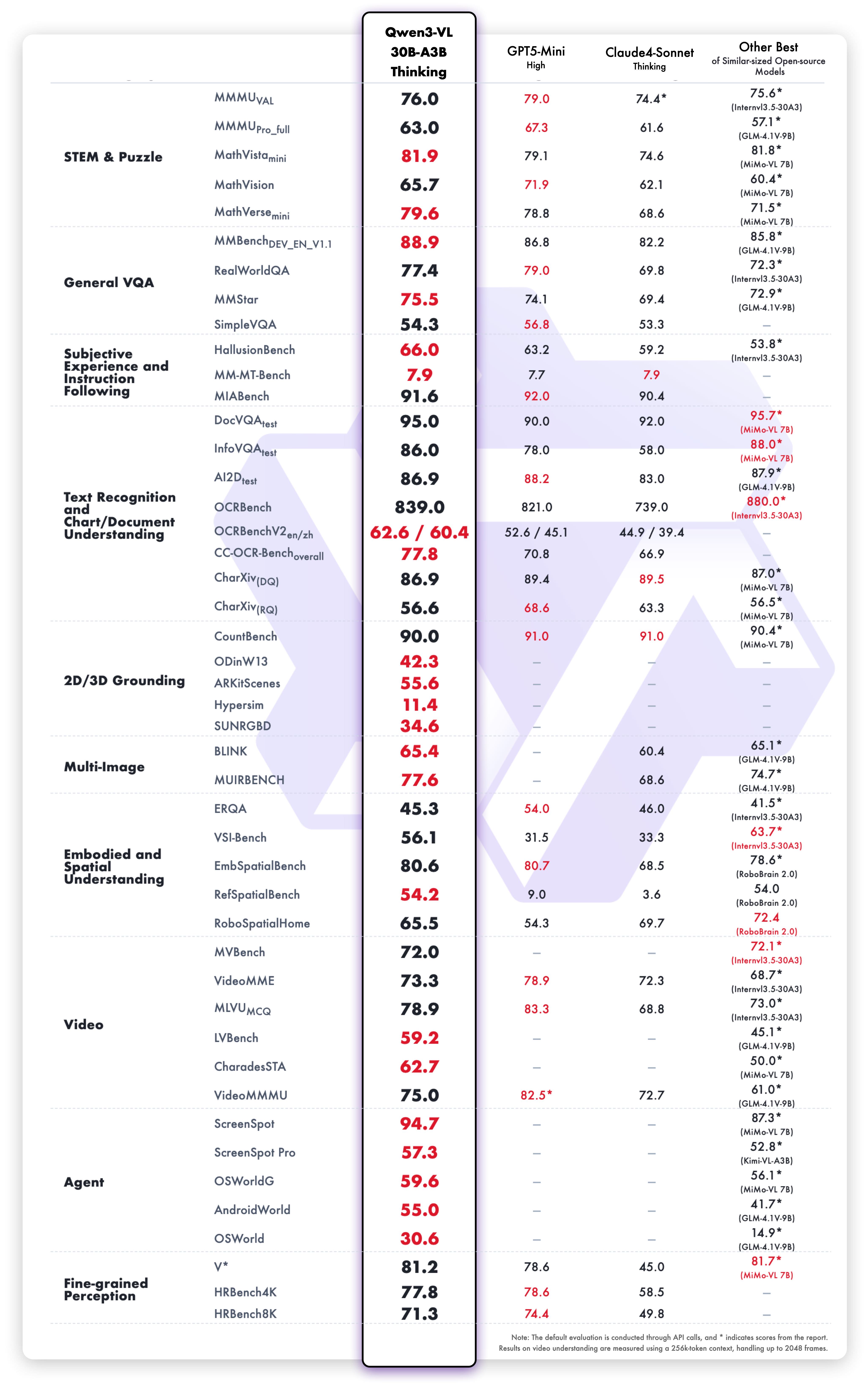
Starke Leistung in allen Bereichen:
- Mathematik-Schlussfolgerung: MathVista, MathVerse, GeoQA
- Visuelle Q&A: VQAv2, GQA, TextVQA
- Dokumente: DocVQA, InfoVQA, ChartQA
- Allgemeine Vision: MMMU, MMBench, Seed-Bench
- Video: Zeitliche Schlussfolgerung und Video-Q&A
Chain-of-Thought-Schlussfolgerung bewältigt mehrstufige Probleme, indem sie sie in logische Stufen zerlegt.
Ergebnisse der Instruct-Variante
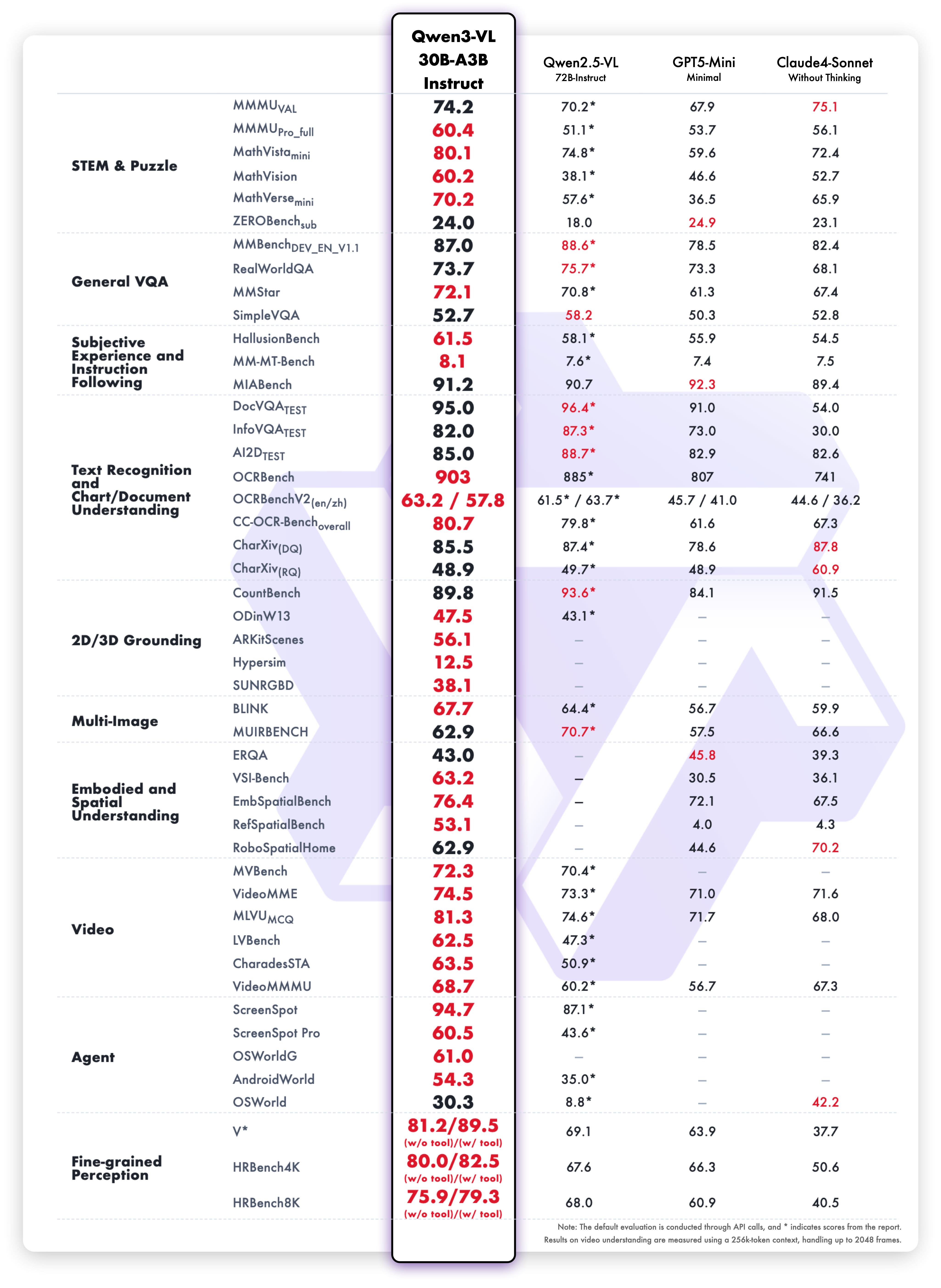
Ausgewogene Leistung:
- Vision-Language: Multimodale Verständnis-Benchmarks
- Textaufgaben: Leseverständnis und Sprache
- OCR: Textextraktionsgenauigkeit
- Geschwindigkeit: Niedrigere Latenz ohne Qualitätseinbußen
- Sprachen: Mehrsprachige Unterstützung
Die Instruct-Variante liefert schnellere Inferenz bei gleichbleibender Genauigkeit. Dies macht sie ideal, wenn Geschwindigkeit wichtig ist.
Welche Variante wählen?
- Thinking: Detaillierte Schlussfolgerung, Mathematikprobleme, erklärbare KI
- Instruct: Schnelle Antworten, hoher Durchsatz, einfache Q&A
Die MoE-Architektur ermöglicht es beiden Varianten, mit größeren Modellen zu niedrigeren Kosten zu konkurrieren.
Kernfunktionen
Visuelles Verständnis
Das Modell generiert Beschreibungen von kurzen Bildunterschriften bis hin zu detaillierten Analysen. Es identifiziert Objekte, Personen, Szenen, räumliche Beziehungen und abstrakte Konzepte.
Dokumentverarbeitung
32-sprachige OCR arbeitet unter anspruchsvollen Bedingungen: schwaches Licht, Unschärfe, Neigung. Das Modell liest seltene Schriftzeichen, alte Schriften und Fachjargon, während es die Dokumentstruktur beibehält.
Unterstützte Formate:
- Gescannte Dokumente und PDFs
- Quittungen und Rechnungen
- Formulare und Tabellen
- Diagramme und Schaubilder
- Mehrspaltige Layouts
Visuelle Q&A
Stellen Sie spezifische Fragen und erhalten Sie kontextbezogene Antworten zu:
- Objektanzahl und -attributen
- Räumlichen Beziehungen
- Aktionen und Aktivitäten
- Szenenzusammensetzung
- Abstrakten Konzepten
Mathematik und Naturwissenschaften
Die Thinking-Variante löst Probleme aus Bildern. Sie liest Gleichungen, interpretiert Diagramme und zeigt Lösungen für Geometrie, Algebra und Textaufgaben.
Videoanalyse
256K Kontext (erweiterbar auf 1M Token) verarbeitet stundenlange Videos. Die Sekunden-indexierung verfolgt Ereignisse über die Zeit hinweg.
GUI-Interaktion
Das Modell erkennt Oberflächenelemente, versteht deren Funktionen und führt Aufgaben aus. Dies ermöglicht visuelle Workflow-Automatisierung.
Code aus visuellen Eingaben
Generieren Sie Draw.io-Diagramme, HTML, CSS und JavaScript aus Bildern und Videos. Zeigen Sie ein UI-Mockup und erhalten Sie funktionsfähigen Code.
Räumliches Schlussfolgern
2D-Grounding und 3D-Grounding für räumliche Aufgaben. Das Modell beurteilt Positionen, Blickwinkel und Verdeckungen.
Praxisanwendungen
E-Commerce
Generieren Sie Produktbeschreibungen aus Fotos. Extrahieren Sie Farb-, Größen- und Materialattribute. Taggen Sie Inventar automatisch. Passen Sie Kundenanfragen an Produktbilder an.
Gesundheitswesen
Verarbeiten Sie medizinische Formulare und Berichte. Extrahieren Sie strukturierte Daten aus klinischen Dokumenten. Lesen Sie Rezeptbilder. Interpretieren Sie handschriftliche Notizen und strukturierte Formulare.
Bildung
Helfen Sie Schülern, Hausaufgaben aus Lehrbuchfotos zu lösen. Erklären Sie Diagramme, Schaubilder und wissenschaftliche Illustrationen. Benoten Sie visuelle Aufgaben. Die Thinking-Variante bietet schrittweise Lösungen.
Finanzwesen
Verarbeiten Sie Rechnungen, Quittungen und Finanzberichte. Extrahieren Sie Positionen, Summen, Daten und Lieferanteninformationen. 32-sprachige Unterstützung bewältigt vielfältige Dokumenttypen.
Kundensupport
Beantworten Sie Fragen zu Produkthandbüchern durch Analyse von Diagrammen. Beheben Sie Probleme anhand von Kundenfotos. Visuelle Agent-Fähigkeiten führen Benutzer durch Oberflächen.
Inhaltsmoderation
Prüfen Sie von Benutzern hochgeladene Bilder auf Richtlinienverstöße. Verstehen Sie Kontext jenseits von Objekterkennung. Bewältigen Sie Sonderfälle, die visuelles Schlussfolgern erfordern.
Forschung
Analysieren Sie wissenschaftliche Diagramme. Interpretieren Sie Schaubilder. Extrahieren Sie Daten aus Forschungsarbeiten. Das Modell glänzt bei STEM und Mathematik mit Kausalanalyse.
Erste Schritte mit Qwen3-VL-30B-A3B auf der Novita AI-Plattform
Novita AI bietet mehrere Zugriffsmöglichkeiten auf Qwen3-VL-30B-A3B, zugeschnitten auf unterschiedliche technische Kenntnisse und Anwendungsfälle. Egal, ob Sie KI-Funktionen erkunden oder Produktionsanwendungen entwickeln, die Plattform bietet Ihnen die benötigten Tools.
Nutzen Sie den Playground (jetzt verfügbar, kein Coding erforderlich)
Sofortiger Zugriff: Melden Sie sich an und beginnen Sie sofort mit dem Experimentieren mit Qwen3-VL-30B-A3B.
Interaktive Oberfläche: Testen Sie Prompts mit Ihren Bildern und visualisieren Sie Ausgaben in Echtzeit.
Modellvergleich: Vergleichen Sie die Qwen3-VL-30B-A3B Instruct- und Thinking-Varianten für Ihren spezifischen Anwendungsfall.
Der Playground ermöglicht es Ihnen, verschiedene Prompts zu testen und sofort Ergebnisse zu sehen, ohne technische Einrichtung. Perfekt für Prototyping, Testen von Ideen und Verstehen der Modellfunktionen vor der vollständigen Implementierung.
Integration über API (live und bereit für Entwickler)
Verbinden Sie Qwen3-VL-30B-A3B mit Ihren Anwendungen über Novita AIs einheitliche REST-API.
Option 1: Direkte API-Integration
Python-Beispiel:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2: Multi-Agent-Workflows mit OpenAI Agents SDK
Erstellen Sie anspruchsvolle Multi-Agent-Systeme mit den fortschrittlichen Fähigkeiten von Qwen3-VL-30B-A3B: Plug-and-Play-Integration: Integrieren Sie Qwen3-VL-30B-A3B in jeden OpenAI-Agents-Workflow. Erweiterte Agent-Fähigkeiten: Unterstützung für Übergaben, Routing und Tool-Integration mit visuellem Verständnis. Skalierbare Architektur: Entwerfen Sie Agenten, die die multimodalen Fähigkeiten von Qwen3-VL-30B-A3B mit anderen spezialisierten Modellen kombinieren.
Option 3: Verbindung mit Drittanbieterplattformen
Entwicklungstools: Integrieren Sie mit beliebten IDEs und Entwicklungsumgebungen wie Cursor, Trae, Qwen Code und Cline über OpenAI-kompatible APIs und Anthropic-kompatible APIs. Orchestrierungsframeworks: Verbinden Sie sich mit LangChain, Dify, CrewAI, Langflow und anderen KI-Orchestrierungsplattformen über offizielle Konnektoren. Hugging Face Integration: Novita AI ist offizieller Inferenzanbieter von Hugging Face und gewährleistet breite Ökosystemkompatibilität.
Probieren Sie Qwen3-VL-30B-A3B noch heute aus
Qwen3-VL-30B-A3B bietet 32-sprachige OCR, 256K Kontext-Videoverständnis, räumliches Schlussfolgern und GUI-Interaktion. Sowohl die Instruct- als auch die Thinking-Variante bieten produktionsreife Leistung für Dokumentverarbeitung, visuelle Q&A und komplexes multimodales Schlussfolgern.
Beginnen Sie mit dem Experimentieren mit Qwen3-VL-30B-A3B im Novita AI Playground.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bietet.



