

Qwen3-VL-235B-A22B is now available on the Novita AI platform, bringing the most powerful vision-language model in the Qwen series to developers through our optimized infrastructure. This generation delivers comprehensive upgrades across the board: superior text understanding and generation, deeper visual perception and reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
Available in both Instruct and reasoning-enhanced Thinking editions, Qwen3-VL-235B-A22B offers flexible, on-demand deployment for diverse applications. Whether you’re developing visual AI applications, building automation solutions, or exploring advanced multimodal capabilities, Qwen3-VL-235B-A22B on Novita AI provides the tools you need with developer-friendly integration.
What is Qwen3-VL-235B-A22B?
Qwen3-VL-235B-A22B represents the most powerful vision-language model in the Qwen series to date. This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment. The model represents a significant advancement in multimodal AI capabilities, combining advanced visual understanding with sophisticated reasoning abilities.
Both variants leverage the same core architecture but are optimized for different use cases - the Instruct edition for direct task completion and interactive applications, while the Thinking edition provides enhanced reasoning capabilities for complex problem-solving scenarios.
Key Enhancement
Visual Agent: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks. This breakthrough capability enables the model to directly interact with graphical user interfaces, making it possible to automate complex workflows and build sophisticated AI agents that can navigate and control software applications.
Visual Coding Boost: Generates Draw.io/HTML/CSS/JS from images/videos. The model can analyze visual designs and mockups to automatically generate corresponding code, dramatically accelerating development workflows and enabling AI-assisted coding from visual inputs.
Advanced Spatial Perception: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI. This enhancement makes the model particularly valuable for robotics, autonomous systems, and applications requiring sophisticated spatial understanding.
Long Context & Video Understanding: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing. This capability enables comprehensive analysis of extensive documents and lengthy video content while maintaining context throughout the entire sequence.
Enhanced Multimodal Reasoning: Excels in STEM/Math—causal analysis and logical, evidence-based answers. The model demonstrates superior performance in scientific and mathematical reasoning tasks, providing detailed analytical responses based on visual and textual information.
Upgraded Visual Recognition: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc. This comprehensive recognition capability ensures robust performance across diverse visual content types and domains.
Expanded OCR: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing. The enhanced optical character recognition capabilities make the model highly effective for document processing and text extraction tasks.
Text Understanding on par with pure LLMs: Seamless text–vision fusion for lossless, unified comprehension. The model achieves text processing capabilities comparable to dedicated language models while maintaining superior multimodal understanding.
Model Architecture Updates
Interleaved-MRoPE
Interleaved-MRoPE: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning. This architectural innovation significantly improves the model’s ability to process and understand temporal sequences in video content.
DeepStack Feature Fusion
DeepStack: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment. The DeepStack architecture ensures optimal integration between visual and textual information, improving overall multimodal performance.
Text-Timestamp Alignment
Text–Timestamp Alignment: Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling. This advanced approach enables more accurate temporal understanding and event localization in video content.
Available Model Variants
Qwen3-VL-235B-A22B-Instruct
This is the weight repository for Qwen3-VL-235B-A22B-Instruct. The Instruct variant is optimized for direct task completion and interactive applications, providing immediate responses to user queries and commands.
This model excels in scenarios requiring rapid, accurate responses to multimodal inputs.
Qwen3-VL-235B-A22B-Thinking
This is the weight repository for Qwen3-VL-235B-A22B-Thinking. The Thinking variant incorporates enhanced reasoning capabilities, making it ideal for complex problem-solving tasks that require detailed analysis and step-by-step reasoning.
This model is particularly valuable for applications requiring deep analytical thinking and comprehensive evaluation.
Performance Benchmarks
Qwen3-VL-235B-A22B demonstrates exceptional performance across multiple domains in both Instruct and Thinking variants, showcasing significant improvements in vision-language understanding and reasoning capabilities.
Thinking Variant Performance
The Qwen3-VL-235B-A22B-Thinking model shows outstanding results across vision-language benchmarks:
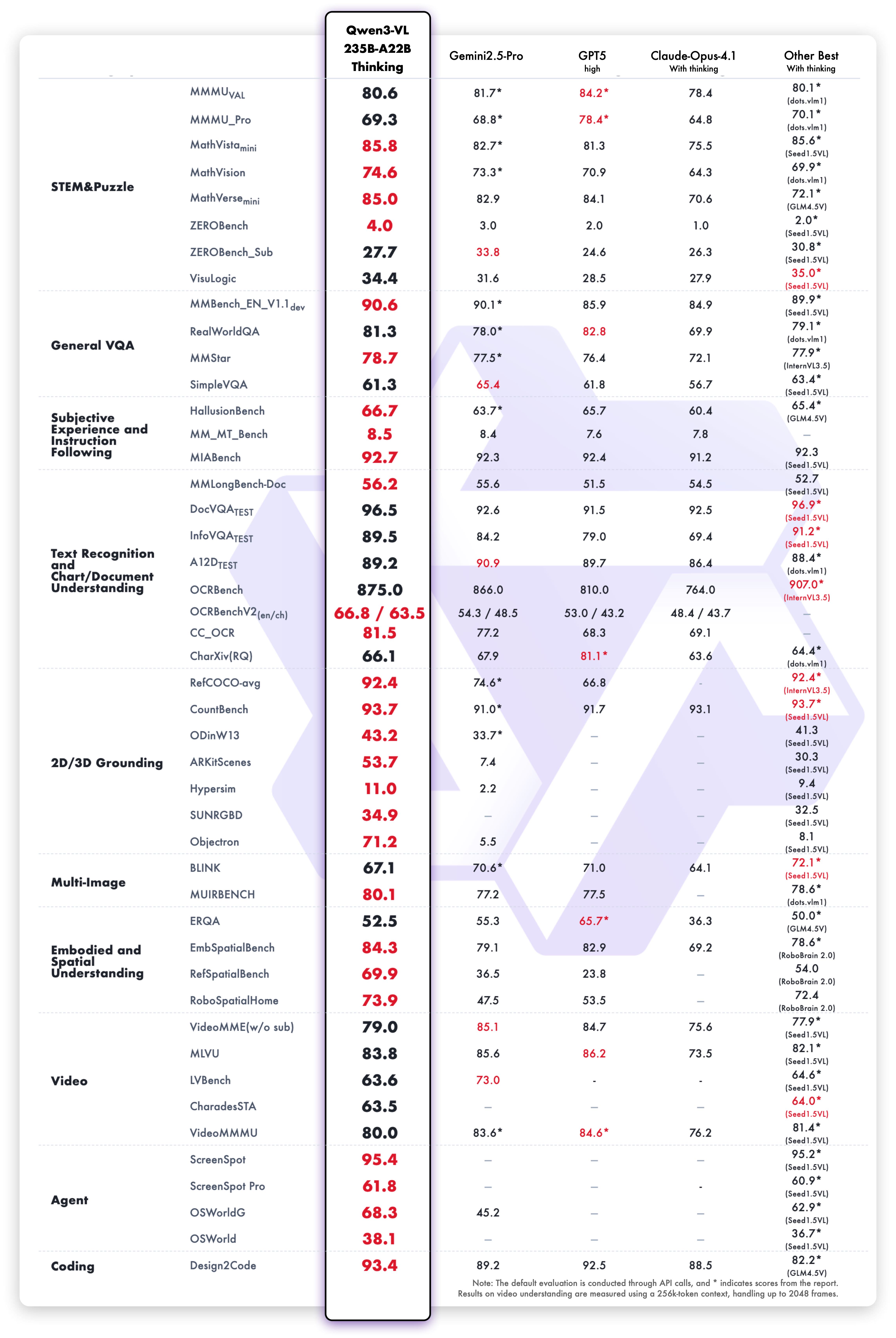
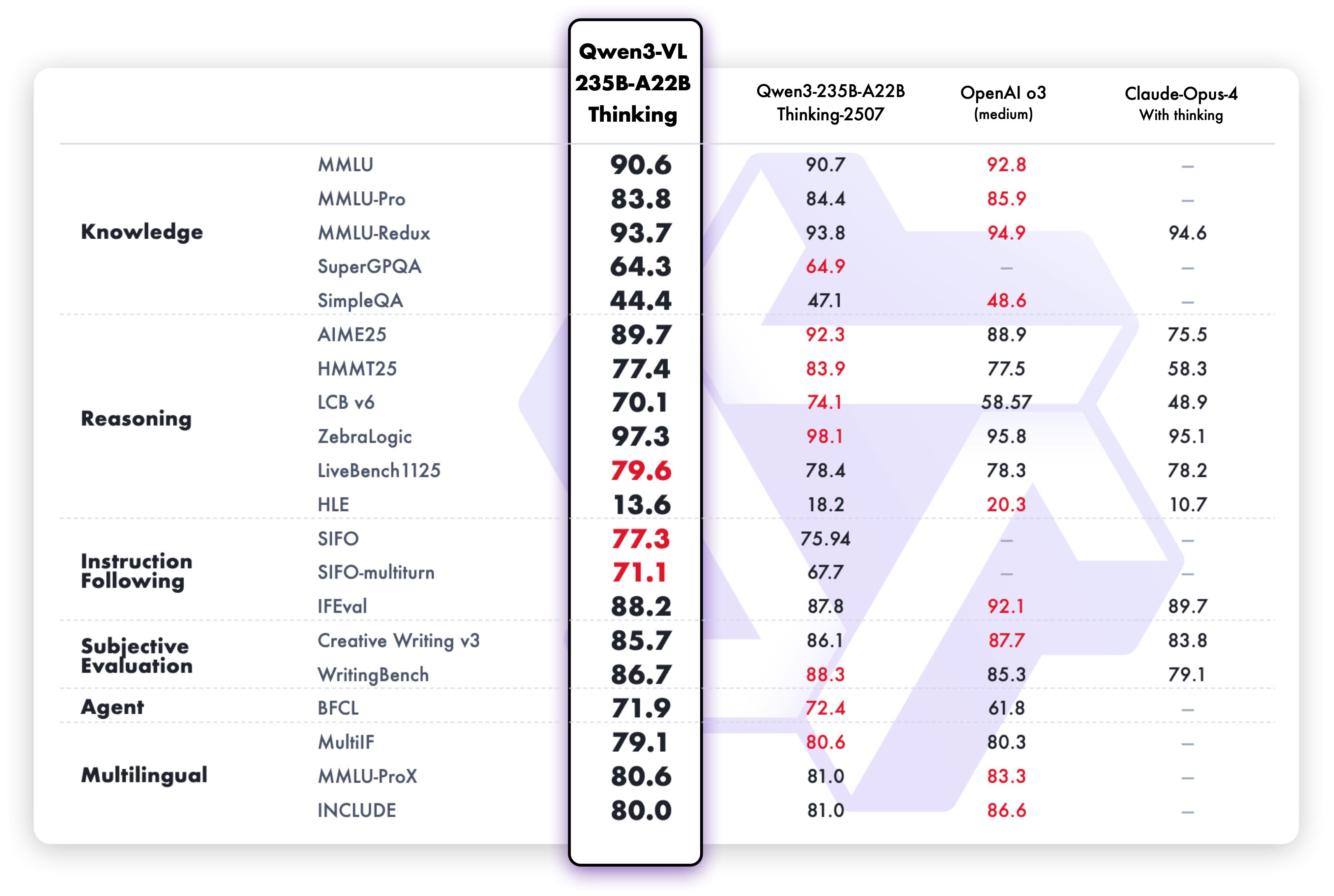
Text reasoning capabilities of the Thinking variant demonstrate superior performance:
Instruct Variant Performance
The Qwen3-VL-235B-A22B-Instruct model achieves competitive results across vision-language evaluation metrics:
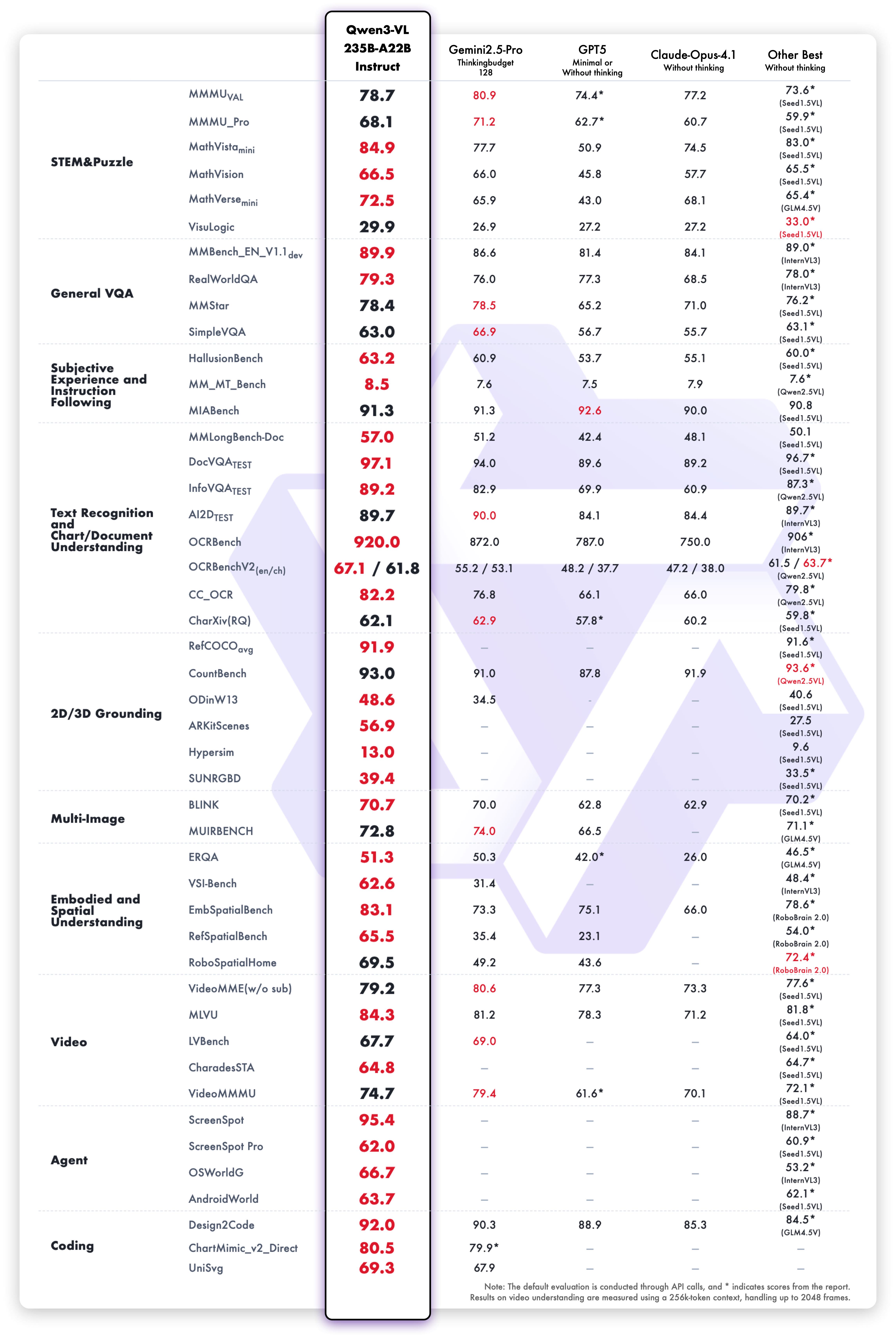
Text understanding and generation performance of the Instruct variant:
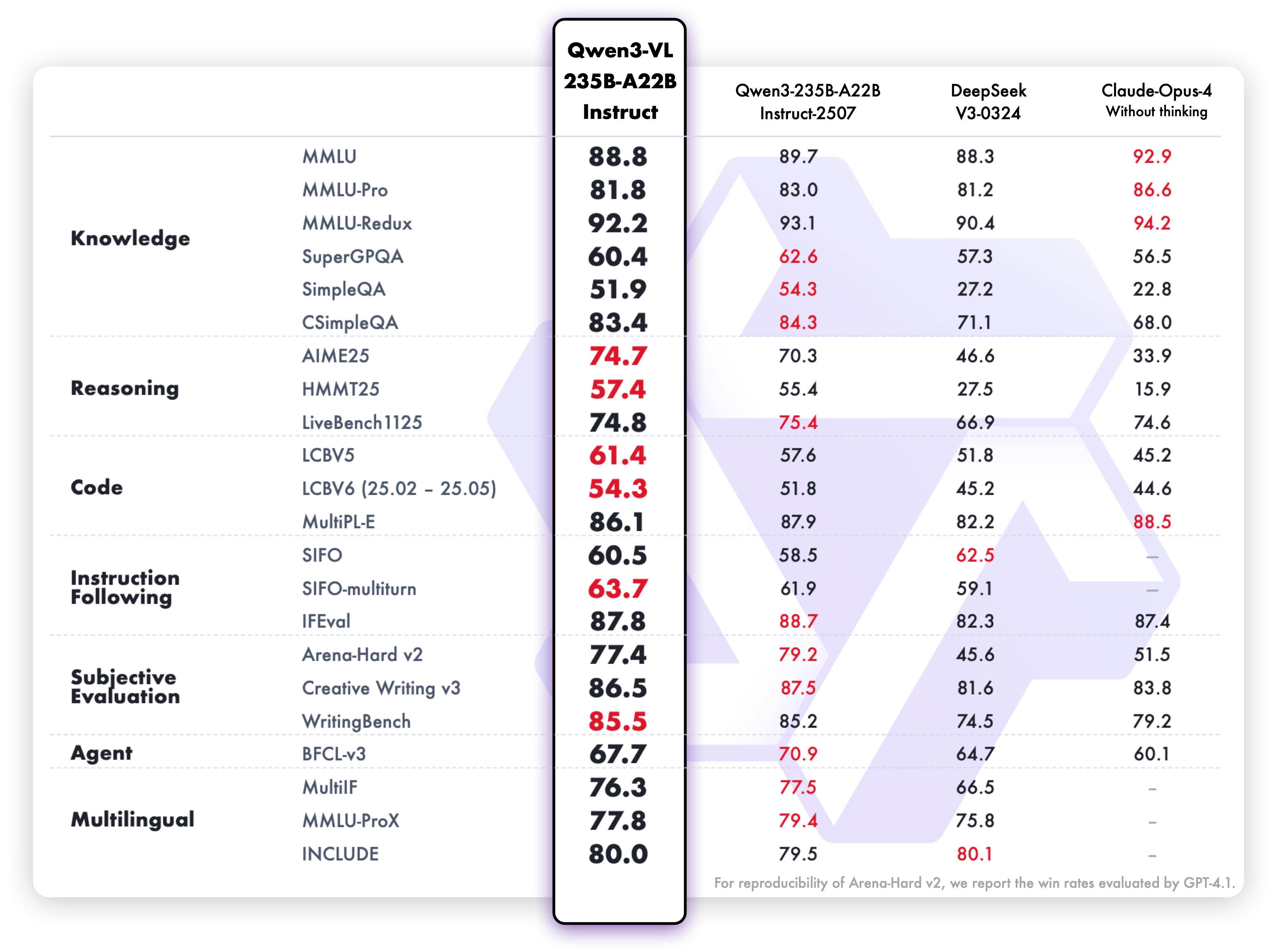
These benchmark results highlight the model’s exceptional capabilities in multimodal understanding, reasoning, and text generation across diverse evaluation criteria. Both variants demonstrate strong performance in their respective areas, making them highly effective for their intended use cases.
Getting Started with Qwen3-VL-235B-A22B on Novita AI Platform
Accessing Qwen3-VL-235B-A22B through Novita AI offers multiple pathways tailored to different technical expertise levels and use cases. Whether you’re a business user exploring AI capabilities or a developer building production applications, Novita AI provides the tools you need.
Use the Playground (Available Now – No Coding Required)
- Instant Access: Sign up and start experimenting with Qwen3-VL-235B-A22B models in seconds
- Interactive Interface: Test prompts and visualize outputs in real-time
- Model Comparison: Compare Qwen3-VL-235B-A22B with other leading models for your specific use case
The playground enables you to test various prompts and see immediate results without any technical setup. Perfect for prototyping, testing ideas, and understanding model capabilities before full implementation.
Integrate via API (Live and Ready – For Developers)
Connect Qwen3-VL-235B-A22B to your applications with Novita AI’s unified REST API.
Option 1: Direct API Integration (Python Example)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build sophisticated multi-agent systems leveraging Qwen3-VL-235B-A22B’s advanced capabilities:
- Plug-and-Play Integration: Use Qwen3-VL-235B-A22B in any OpenAI Agents workflow
- Advanced Agent Capabilities: Support for handoffs, routing, and tool integration with visual understanding
- Scalable Architecture: Design agents that leverage Qwen3-VL-235B-A22B’s multimodal capabilities
Option 3: Connect with Third-Party Platforms
Development Tools: Seamlessly integrate with popular IDEs and development environments like Cursor, Trae, Qwen Code and Cline through OpenAI-compatible APIs and Anthropic-compatible APIs.
Orchestration Frameworks: Connect with LangChain, Dify, CrewAI, Langflow, and other AI orchestration platforms using official connectors.
Hugging Face Integration: Novita AI serves as an official inference provider of Hugging Face, ensuring broad ecosystem compatibility.
Use Cases and Applications
Visual Agent Development
Leverage the visual agent capabilities to build applications that can interact with GUIs, automate workflows, and complete complex tasks through visual understanding.
Visual Coding and Development
Utilize the visual coding enhancement to generate HTML, CSS, JavaScript, and Draw.io diagrams from visual inputs, accelerating development workflows.
Document and Video Analysis
Take advantage of the 256K context length and enhanced OCR capabilities for comprehensive document processing and video content analysis.
STEM and Educational Applications
Apply the enhanced multimodal reasoning for educational technology, scientific analysis, and mathematical problem-solving applications.
Spatial Reasoning Applications
Implement the advanced spatial perception capabilities for robotics, autonomous systems, and applications requiring 3D understanding.
Conclusion
Qwen3-VL-235B-A22B on Novita AI delivers the most advanced vision-language capabilities available today, with both Instruct and Thinking variants providing flexible deployment options for diverse applications. The comprehensive enhancements in visual perception, reasoning, and agent capabilities, combined with extended context and superior multimodal understanding, make this the definitive choice for cutting-edge AI development.
Start exploring Qwen3-VL-235B-A22B’s revolutionary capabilities on Novita AI today and experience the future of vision-language AI with our developer-friendly platform and seamless integration options.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



