

- Qu'est-ce que Qwen3-VL-30B-A3B ?
- Fonctionnalités et améliorations clés
- Architecture et spécifications du modèle
- Comparaison de Qwen3-VL-30B-A3B-Instruct et Qwen3-VL-30B-A3B-Thinking
- Benchmarks de performance
- Capacités principales
- Applications concrètes
- Démarrage avec Qwen3-VL-30B-A3B sur la plateforme Novita AI
- Essayez Qwen3-VL-30B-A3B dès aujourd'hui
Qwen3-VL-30B-A3B traite des images, des documents et des vidéos en même temps que du texte, grâce à 30 milliards de paramètres. Le modèle prend en charge toutes les tâches, de l’OCR dans 32 langues à l’analyse de vidéos de plusieurs heures avec un contexte de 256K.
Novita AI héberge deux variantes. La variante Instruct fournit des réponses rapides et directes. La variante Thinking affiche son processus de raisonnement pour les tâches complexes. Vous pouvez accéder aux deux via le playground ou l’API.
Essayer la démo de Qwen3-VL-30B-A3B
Qu’est-ce que Qwen3-VL-30B-A3B ?
Qwen3-VL-30B-A3B est développé par l’équipe Qwen d’Alibaba Cloud. Le modèle repose sur une architecture MoE (Mixture-of-Experts, ou mélange d’experts) avec 30,5 milliards de paramètres au total et 3,3 milliards activés. Cette conception offre des performances élevées tout en maîtrisant les coûts.
Le modèle se positionne entre les variantes plus petites de Qwen3-VL et le modèle phare Qwen3-VL-235B-A22B, offrant un équilibre entre capacités et efficacité. Là où le modèle 235B excelle sur les tâches de raisonnement les plus exigeantes, la variante 30B propose des capacités similaires à un coût plus faible et avec des vitesses d’inférence plus rapides.
Les principales améliorations incluent :
- Contexte natif de 256K, extensible à 1 million de tokens
- Prise en charge de l’OCR dans 32 langues (contre 19 précédemment)
- Ancrage spatial 2D et 3D
- Capacités d’interaction avec les interfaces graphiques (GUI)
- Génération de code à partir d’entrées visuelles
- Compréhension vidéo avec indexation au niveau de la seconde
Deux variantes répondent à des besoins différents. La variante Instruct est optimisée pour la vitesse. La variante Thinking prend en charge les raisonnements complexes.
Fonctionnalités et améliorations clés
Capacités d’agent visuel
Le modèle reconnaît les éléments des interfaces et accomplit des tâches sur des GUI PC et mobiles. Il comprend la fonction des boutons et la manière de naviguer dans les applications.
Codage visuel
Montrez une capture d’écran à Qwen3-VL et obtenez du code fonctionnel. Le modèle génère des diagrammes Draw.io, du HTML, du CSS et du JavaScript à partir d’images et de vidéos.
Perception spatiale
Le modèle évalue les positions des objets, les points de vue et les occultations. Il propose un ancrage 2D et permet un ancrage 3D pour les tâches de raisonnement spatial et les applications d’IA incarnée.
Contexte étendu pour les vidéos longues
Le contexte natif de 256K est extensible à 1 million de tokens. Le modèle traite des livres et des vidéos de plusieurs heures avec une restitution complète des informations. L’indexation au niveau de la seconde vous permet d’interroger des moments précis.
OCR avancé
L’OCR prend désormais en charge 32 langues. Le modèle fonctionne en faible luminosité, gère le flou et l’inclinaison, lit des caractères rares et anciens, et analyse des documents longs tout en préservant leur structure.
Raisonnement STEM et mathématiques
Le modèle excelle dans l’analyse causale et les réponses fondées sur des preuves pour les problèmes de sciences, technologie, ingénierie et mathématiques.
Reconnaissance améliorée
Un pré-entraînement plus large permet au modèle de reconnaître des célébrités, des personnages d’anime, des produits, des monuments, des plantes et des animaux.
Architecture et spécifications du modèle
Architecture : Qwen3VLMoeForConditionalGeneration avec encodeur visuel à base de ViT intégré
Spécifications principales :
- Paramètres totaux : 30,5 milliards
- Paramètres activés : 3,3 milliards
- Longueur de contexte : 256K tokens (native), extensible à 1 million
- Formats pris en charge : JPEG, PNG, WebP, BMP, vidéo
Trois innovations architecturales :
Interleaved-MRoPE alloue l’ensemble des fréquences sur le temps, la largeur et la hauteur via des embeddings positionnels. Cela améliore le raisonnement sur des vidéos de longue durée.
DeepStack fusionne des caractéristiques ViT multi-niveaux pour capturer les détails fins et améliorer l’alignement image-texte.
Text-Timestamp Alignment fournit une localisation précise des événements basée sur des horodatages pour un modèle temporel vidéo plus robuste.
Comparaison de Qwen3-VL-30B-A3B-Instruct et Qwen3-VL-30B-A3B-Thinking
Instruct : rapide et direct
La variante Instruct répond immédiatement sans afficher son raisonnement. Elle est optimisée pour la vitesse et le débit.
Cas d’usage :
- Classification d’images en temps réel
- OCR de documents et extraction de texte
- Modération de contenu à grande échelle
- Appels API à haut volume
- Questions-réponses visuelles simples
Thinking : raisonnement détaillé
La variante Thinking affiche une analyse étape par étape avant de répondre. Elle décompose les problèmes complexes en étapes logiques, de la même manière que fonctionne la variante Thinking du modèle plus grand Qwen3-VL-235B-A22B.
Cas d’usage :
- Problèmes de mathématiques à partir d’images
- Raisonnement visuel multi-étapes
- Analyse de documents scientifiques
- Applications éducatives
- Tâches nécessitant de l’explicabilité
Choisissez la variante Instruct pour la plupart des charges de travail en production. Passez à la variante Thinking lorsque vous avez besoin d’un raisonnement transparent ou que vous traitez des tâches analytiques complexes.
Benchmarks de performance
Résultats de la variante Thinking
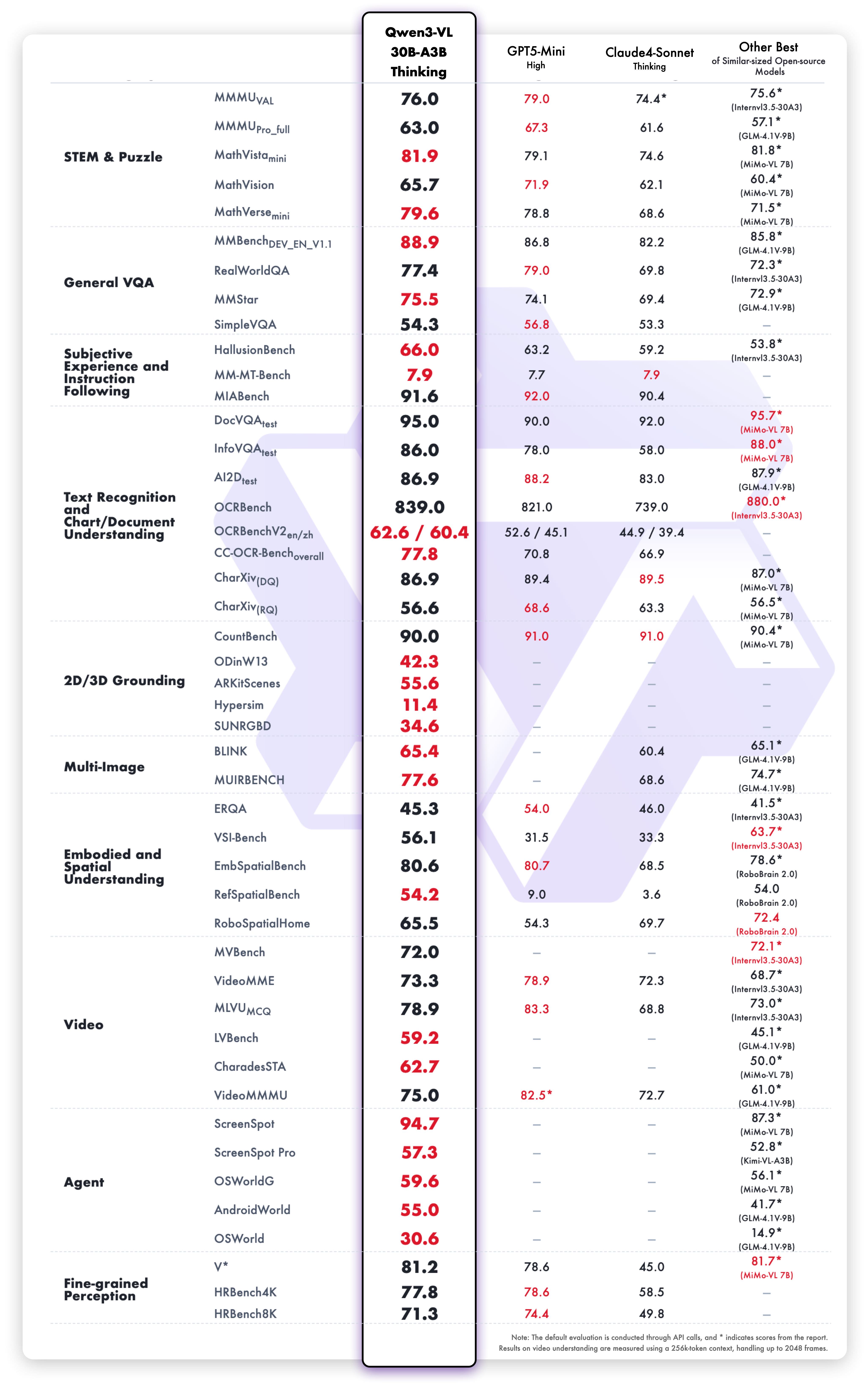
De bonnes performances sur l’ensemble des benchmarks suivants :
- Raisonnement mathématique : MathVista, MathVerse, GeoQA
- Questions-réponses visuelles : VQAv2, GQA, TextVQA
- Documents : DocVQA, InfoVQA, ChartQA
- Vision générale : MMMU, MMBench, Seed-Bench
- Vidéo : Raisonnement temporel et questions-réponses sur vidéo
Le raisonnement par chaîne de pensée (chain-of-thought) traite les problèmes multi-étapes en les décomposant en étapes logiques.
Résultats de la variante Instruct
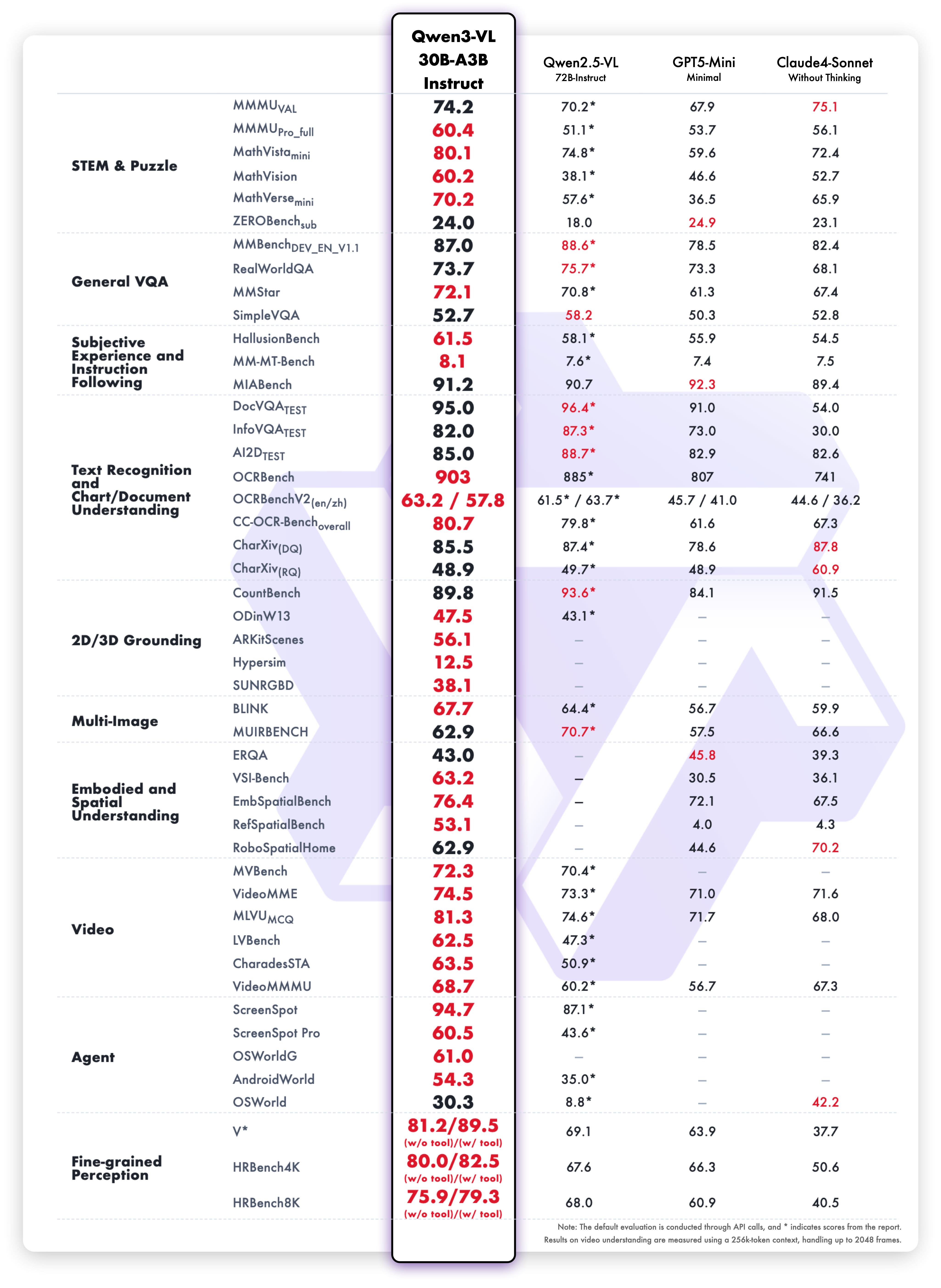
Performances équilibrées :
- Vision-langage : Benchmarks de compréhension multimodale
- Tâches textuelles : Compréhension de lecture et langage
- OCR : Précision de l’extraction de texte
- Vitesse : Latence plus faible sans sacrifice de la qualité
- Langues : Prise en charge de plusieurs langues
La variante Instruct offre une inférence plus rapide tout en maintenant la précision. Elle est donc idéale lorsque la vitesse est un critère important.
Quel modèle choisir ?
- Thinking : Raisonnement détaillé, problèmes de mathématiques, IA explicable
- Instruct : Réponses rapides, haut débit, questions-réponses simples
L’architecture MoE permet aux deux variantes de rivaliser avec des modèles plus grands à un coût plus faible.
Capacités principales
Compréhension visuelle
Le modèle génère des descriptions allant de légendes courtes à des analyses détaillées. Il identifie des objets, des personnes, des scènes, des relations spatiales et des concepts abstraits.
Traitement de documents
L’OCR dans 32 langues fonctionne dans des conditions difficiles : faible luminosité, flou, inclinaison. Le modèle lit des caractères rares, des écritures anciennes et du jargon technique tout en préservant la structure du document.
Formats pris en charge :
- Documents numérisés et PDF
- Reçus et factures
- Formulaires et tableaux
- Graphiques et diagrammes
- Mises en page à plusieurs colonnes
Questions-réponses visuelles
Posez des questions spécifiques et obtenez des réponses contextuelles sur :
- Le nombre et les attributs des objets
- Les relations spatiales
- Les actions et les activités
- La composition des scènes
- Les concepts abstraits
Mathématiques et sciences
La variante Thinking résout des problèmes à partir d’images. Elle lit des équations, interprète des diagrammes et présente des solutions pour des problèmes de géométrie, d’algèbre et des problèmes écrits.
Analyse vidéo
Le contexte de 256K (extensible à 1 million de tokens) prend en charge des vidéos de plusieurs heures. L’indexation au niveau de la seconde suit les événements dans le temps.
Interaction avec les interfaces graphiques
Le modèle reconnaît les éléments des interfaces, comprend leurs fonctions et accomplit des tâches. Cela permet l’automatisation de flux de travail visuels.
Code à partir d’éléments visuels
Générez des diagrammes Draw.io, du HTML, du CSS et du JavaScript à partir d’images et de vidéos. Montrez une maquette d’interface et obtenez du code fonctionnel.
Raisonnement spatial
Ancrage 2D et ancrage 3D pour les tâches spatiales. Le modèle évalue les positions, les points de vue et les occultations.
Applications concrètes
E-commerce
Générez des descriptions de produits à partir de photos. Extrayez les attributs de couleur, de taille et de matériau. Étiquetez automatiquement les stocks. Associez les requêtes des clients aux images de produits.
Santé
Traitez des formulaires et des rapports médicaux. Extrayez des données structurées de documents cliniques. Lisez des images d’ordonnances. Interprétez des notes manuscrites et des formulaires structurés.
Éducation
Aidez les élèves à résoudre leurs devoirs à partir de photos de manuels. Expliquez des diagrammes, des graphiques et des illustrations scientifiques. Corrigez des devoirs visuels. La variante Thinking fournit des solutions étape par étape.
Finance
Traitez des factures, des reçus et des états financiers. Extrayez les lignes de dépenses, les totaux, les dates et les informations sur les fournisseurs. La prise en charge de 32 langues permet de traiter des types de documents variés.
Support client
Répondez à des questions sur des manuels de produits en analysant des diagrammes. Résolvez des problèmes à partir de photos envoyées par les clients. Les capacités d’agent visuel guident les utilisateurs dans les interfaces.
Modération de contenu
Contrôlez les images téléchargées par les utilisateurs pour détecter des violations de politique. Comprenez le contexte au-delà de la détection d’objets. Traitez les cas limites nécessitant un raisonnement visuel.
Recherche
Analysez des diagrammes scientifiques. Interprétez des graphiques. Extrayez des données d’articles de recherche. Le modèle excelle dans les domaines STEM et les mathématiques grâce à l’analyse causale.
Démarrage avec Qwen3-VL-30B-A3B sur la plateforme Novita AI
Novita AI propose plusieurs voies d’accès à Qwen3-VL-30B-A3B, adaptées à différents niveaux d’expertise technique et cas d’usage. Que vous exploriez les capacités de l’IA ou que vous construisiez des applications en production, la plateforme met à disposition les outils dont vous avez besoin.
Utiliser le playground (disponible immédiatement, aucun code requis)
Accès instantané : Inscrivez-vous et commencez à expérimenter avec Qwen3-VL-30B-A3B en quelques secondes. Interface interactive : Testez des prompts avec vos images et visualisez les résultats en temps réel. Comparaison de modèles : Comparez les variantes Instruct et Thinking de Qwen3-VL-30B-A3B pour votre cas d’usage spécifique.
Le playground vous permet de tester différents prompts et d’obtenir des résultats immédiats sans aucune configuration technique. Il est parfait pour le prototypage, le test d’idées et la compréhension des capacités du modèle avant une mise en œuvre complète.
Intégration via API (disponible et prête pour les développeurs)
Connectez Qwen3-VL-30B-A3B à vos applications grâce à l’API REST unifiée de Novita AI.
Option 1 : Intégration API directe
Exemple Python :
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2 : Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents sophistiqués en utilisant les capacités avancées de Qwen3-VL-30B-A3B : Intégration plug-and-play : Intégrez Qwen3-VL-30B-A3B dans tout flux de travail OpenAI Agents. Capacités d’agents avancées : Prise en charge des transferts, du routage et de l’intégration d’outils avec compréhension visuelle. Architecture évolutive : Concevez des agents qui combinent les capacités multimodales de Qwen3-VL-30B-A3B avec d’autres modèles spécialisés.
Option 3 : Connexion avec des plateformes tierces
Outils de développement : Intégrez-vous avec des IDE et des environnements de développement populaires comme Cursor, Trae, Qwen Code et Cline via des API compatibles OpenAI et des API compatibles Anthropic. Frameworks d’orchestration : Connectez-vous à LangChain, Dify, CrewAI, Langflow et autres plateformes d’orchestration IA à l’aide de connecteurs officiels. Intégration Hugging Face : Novita AI est un fournisseur d’inférence officiel de Hugging Face, garantissant une compatibilité large avec l’écosystème.
Essayez Qwen3-VL-30B-A3B dès aujourd’hui
Qwen3-VL-30B-A3B propose de l’OCR dans 32 langues, une compréhension vidéo avec contexte de 256K, du raisonnement spatial et de l’interaction avec les interfaces graphiques. Les deux variantes, Instruct et Thinking, offrent des performances prêtes pour la production pour le traitement de documents, les questions-réponses visuelles et les raisonnements multimodaux complexes.
Commencez à expérimenter avec Qwen3-VL-30B-A3B dans le Playground Novita AI.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle vos projets.



