

- O que é o Qwen3-VL-30B-A3B?
- Principais recursos e melhorias
- Arquitetura e especificações do modelo
- Qwen3-VL-30B-A3B-Instruct vs Qwen3-VL-30B-A3B-Thinking
- Benchmark de desempenho
- Capacidades principais
- Aplicações no mundo real
- Começando a usar o Qwen3-VL-30B-A3B na plataforma Novita AI
- Experimente o Qwen3-VL-30B-A3B hoje
O Qwen3-VL-30B-A3B processa imagens, documentos e vídeos juntamente com texto usando 30 bilhões de parâmetros. O modelo lida com tudo, desde OCR em 32 idiomas até análise de vídeos de várias horas com contexto de 256K.
A Novita AI hospeda duas variantes. A Instruct entrega respostas rápidas e diretas. A Thinking exibe seu processo de raciocínio para tarefas complexas. Acesse ambas pelo playground ou pela API.
Teste a demonstração do Qwen3-VL-30B-A3B
O que é o Qwen3-VL-30B-A3B?
O Qwen3-VL-30B-A3B é desenvolvido pela equipe Qwen da Alibaba Cloud. O modelo utiliza a arquitetura MoE (Mixture-of-Experts) com 30,5 bilhões de parâmetros totais e 3,3 bilhões ativados. Esse design entrega desempenho forte enquanto mantém os custos controlados.
O modelo fica entre as variantes menores do Qwen3-VL e o modelo principal Qwen3-VL-235B-A22B, equilibrando capacidade e eficiência. Enquanto o modelo de 235B se destaca nas tarefas de raciocínio mais exigentes, a variante de 30B oferece capacidades semelhantes a custo menor e velocidades de inferência mais rápidas.
Principais atualizações incluem:
- Contexto nativo de 256K, expansível para 1M de tokens
- Suporte a OCR em 32 idiomas (aumento de 19 para 32)
- Baseamento espacial 2D e 3D
- Capacidades de interação com GUI
- Geração de código a partir de entradas visuais
- Compreensão de vídeo com indexação por segundo
Duas variantes atendem a necessidades diferentes. A Instruct é otimizada para velocidade. A Thinking lida com raciocínios complexos.
Principais recursos e melhorias
Capacidades de agente visual
O modelo reconhece elementos de interface e completa tarefas em GUIs de PC e dispositivos móveis. Ele entende a função dos botões e como navegar por aplicativos.
Codificação visual
Mostre uma captura de tela para o Qwen3-VL e obtenha código funcional. O modelo gera diagramas Draw.io, HTML, CSS e JavaScript a partir de imagens e vídeos.
Percepção espacial
O modelo julga posições de objetos, pontos de vista e oclusões. Ele fornece baseamento 2D e habilita o baseamento 3D para raciocínio espacial e aplicações de IA incorporada.
Contexto estendido para vídeos longos
O contexto nativo de 256K se expande para 1M de tokens. O modelo lida com livros e vídeos de várias horas com recall completo. A indexação por segundo permite consultar momentos específicos.
OCR avançado
O OCR agora suporta 32 idiomas. O modelo funciona em baixa luminosidade, lida com desfoque e inclinação, lê caracteres raros e antigos, e analisa documentos longos preservando a estrutura.
Raciocínio em STEM e matemática
O modelo se destaca em análise causal e respostas baseadas em evidências para problemas de ciência, tecnologia, engenharia e matemática.
Reconhecimento aprimorado
O pré-treinamento mais amplo permite que o modelo reconheça celebridades, personagens de anime, produtos, pontos turísticos, plantas e animais.
Arquitetura e especificações do modelo
Arquitetura: Qwen3VLMoeForConditionalGeneration com codificador de visão baseado em ViT integrado
Especificações principais:
- Parâmetros totais: 30,5B
- Parâmetros ativados: 3,3B
- Comprimento de contexto: 256K tokens (nativo), expansível para 1M
- Formatos suportados: JPEG, PNG, WebP, BMP, vídeo
Três inovações arquitetônicas:
Interleaved-MRoPE aloca frequência completa ao longo do tempo, largura e altura por meio de embeddings posicionais. Isso melhora o raciocínio em vídeos de longo horizonte.
DeepStack funde recursos de ViT de múltiplos níveis para capturar detalhes finos e aprimorar o alinhamento entre imagem e texto.
Alinhamento Texto-Timestamp fornece localização precisa de eventos baseada em carimbo de data/hora para um modelamento temporal de vídeo mais forte.
Qwen3-VL-30B-A3B-Instruct vs Qwen3-VL-30B-A3B-Thinking
Instruct: rápido e direto
A variante Instruct responde imediatamente sem exibir seu processo. Ela é otimizada para velocidade e throughput.
Casos de uso:
- Classificação de imagens em tempo real
- OCR de documentos e extração de texto
- Moderação de conteúdo em larga escala
- Chamadas de API de alto volume
- Perguntas e respostas visuais simples
Thinking: raciocínio detalhado
A variante Thinking exibe uma análise passo a passo antes de responder. Ela divide problemas complexos em etapas lógicas, de forma semelhante ao funcionamento da variante Thinking do modelo maior Qwen3-VL-235B-A22B.
Casos de uso:
- Problemas de matemática a partir de imagens
- Raciocínio visual de múltiplas etapas
- Análise de documentos científicos
- Aplicações educacionais
- Tarefas que exigem explicabilidade
Escolha a Instruct para a maioria das cargas de trabalho de produção. Mude para a Thinking quando precisar de raciocínio transparente ou lidar com tarefas analíticas complexas.
Benchmark de desempenho
Resultados da variante Thinking
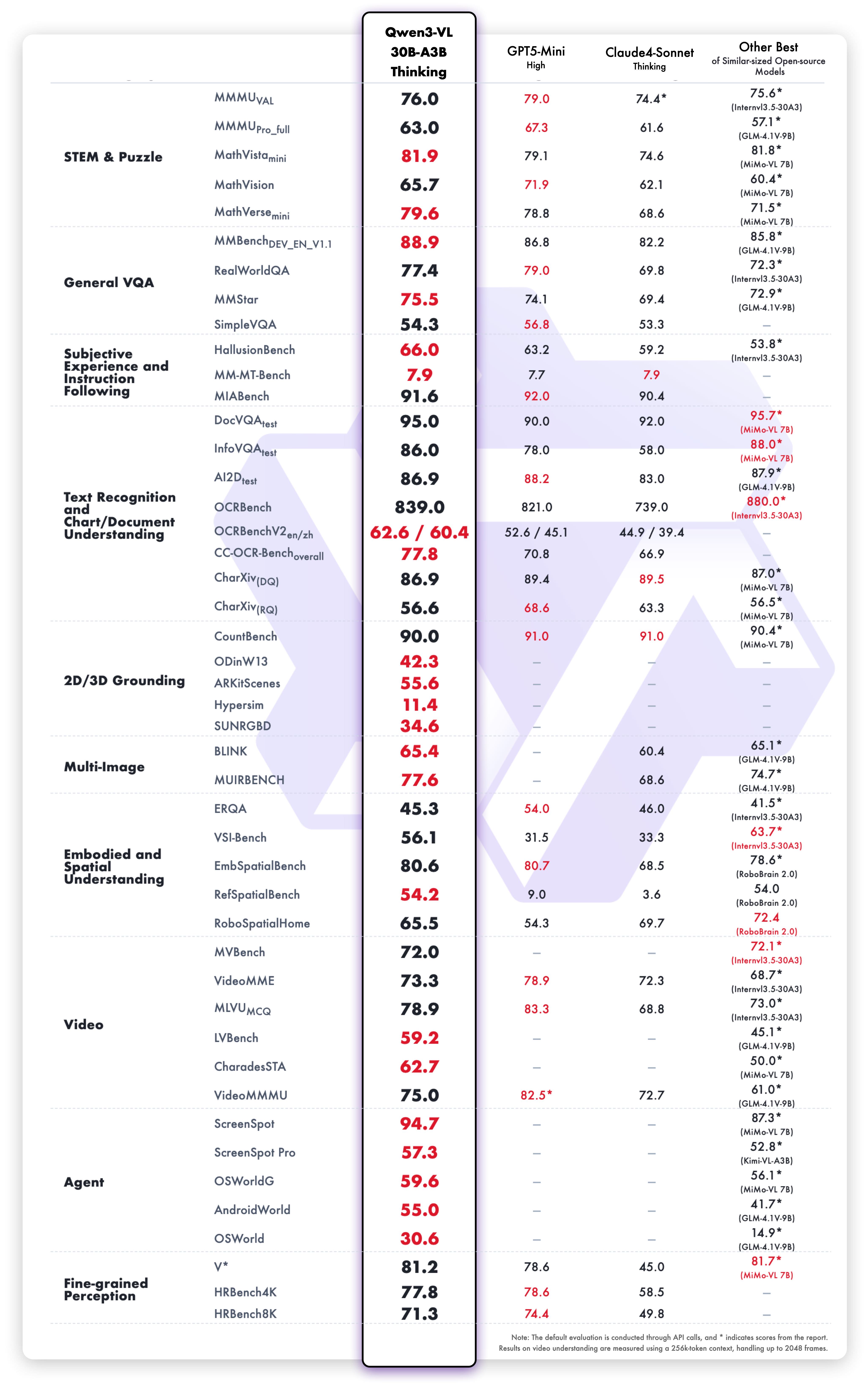
Desempenho forte em:
- Raciocínio matemático: MathVista, MathVerse, GeoQA
- Perguntas e respostas visuais: VQAv2, GQA, TextVQA
- Documentos: DocVQA, InfoVQA, ChartQA
- Visão geral: MMMU, MMBench, Seed-Bench
- Vídeo: Raciocínio temporal e perguntas e respostas sobre vídeos
O raciocínio de cadeia de pensamento lida com problemas de múltiplas etapas, dividindo-os em estágios lógicos.
Resultados da variante Instruct
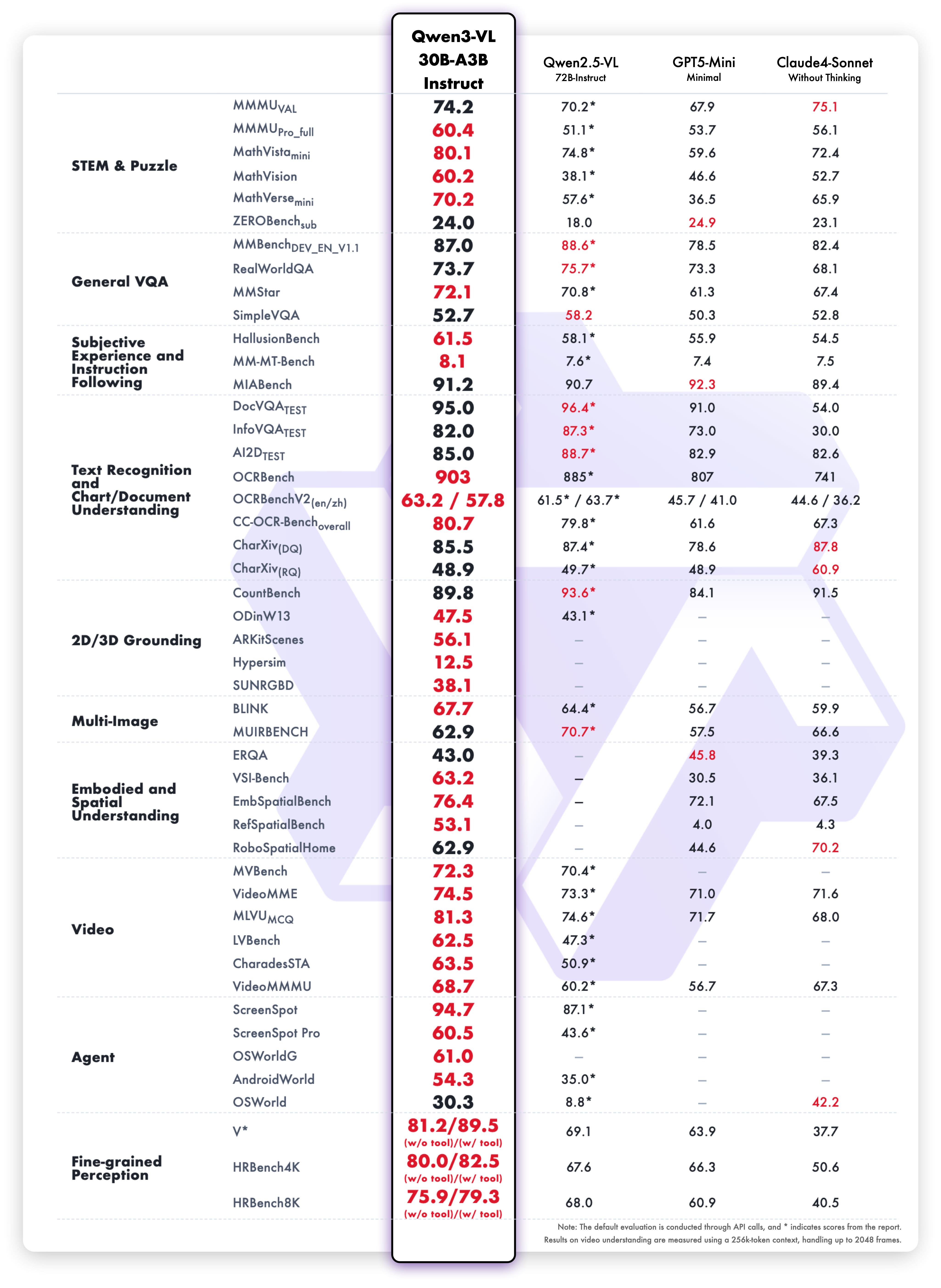
Desempenho equilibrado:
- Visão e linguagem: Benchmark de compreensão multimodal
- Tarefas de texto: Compreensão de leitura e linguagem
- OCR: Precisão na extração de texto
- Velocidade: Latência menor sem sacrificar a qualidade
- Idiomas: Suporte a múltiplos idiomas
A variante Instruct oferece inferência mais rápida mantendo a precisão. Isso a torna ideal quando a velocidade é importante.
Qual escolher
- Thinking: Raciocínio detalhado, problemas de matemática, IA explicável
- Instruct: Respostas rápidas, alto throughput, perguntas e respostas diretas
A arquitetura MoE permite que ambas as variantes competam com modelos maiores a custo menor.
Capacidades principais
Compreensão visual
O modelo gera descrições que vão de legendas curtas a análises detalhadas. Ele identifica objetos, pessoas, cenários, relações espaciais e conceitos abstratos.
Processamento de documentos
O OCR em 32 idiomas funciona em condições desafiadoras: baixa luminosidade, desfoque, inclinação. O modelo lê caracteres raros, escritas antigas e jargões técnicos preservando a estrutura do documento.
Formatos suportados:
- Documentos digitalizados e PDFs
- Recibos e faturas
- Formulários e tabelas
- Gráficos e diagramas
- Layouts de múltiplas colunas
Perguntas e respostas visuais
Faça perguntas específicas e obtenha respostas contextuais sobre:
- Contagem e atributos de objetos
- Relações espaciais
- Ações e atividades
- Composição de cenários
- Conceitos abstratos
Matemática e ciências
A variante Thinking resolve problemas a partir de imagens. Ela lê equações, interpreta diagramas e exibe soluções para geometria, álgebra e problemas de palavras.
Análise de vídeo
O contexto de 256K (expansível para 1M de tokens) lida com vídeos de várias horas. A indexação por segundo rastreia eventos ao longo do tempo.
Interação com GUI
O modelo reconhece elementos de interface, entende suas funções e completa tarefas. Isso possibilita a automação de fluxos de trabalho visuais.
Código a partir de elementos visuais
Gere diagramas Draw.io, HTML, CSS e JavaScript a partir de imagens e vídeos. Mostre um mockup de interface e obtenha código funcional.
Raciocínio espacial
Baseamento 2D e 3D para tarefas espaciais. O modelo julga posições, pontos de vista e oclusões.
Aplicações no mundo real
E-commerce
Gere descrições de produtos a partir de fotos. Extraia atributos de cor, tamanho e material. Marque o inventário automaticamente. Associe consultas de clientes a imagens de produtos.
Saúde
Processe formulários e relatórios médicos. Extraia dados estruturados de documentos clínicos. Leia imagens de receitas. Interprete anotações manuscritas e formulários estruturados.
Educação
Ajude alunos a resolver lições de casa a partir de fotos de livros didáticos. Explique diagramas, gráficos e ilustrações científicas. Corrija tarefas visuais. A variante Thinking fornece soluções passo a passo.
Finanças
Processe faturas, recibos e demonstrações financeiras. Extraia itens de linha, totais, datas e informações de fornecedores. O suporte a 32 idiomas lida com tipos de documentos diversos.
Atendimento ao cliente
Responda perguntas sobre manuais de produtos analisando diagramas. Solucione problemas a partir de fotos de clientes. As capacidades de agente visual guiam os usuários por interfaces.
Moderação de conteúdo
Filtre imagens enviadas por usuários em busca de violações de políticas. Entenda o contexto além da detecção de objetos. Lide com casos extremos que exigem raciocínio visual.
Pesquisa
Analise diagramas científicos. Interprete gráficos. Extraia dados de artigos de pesquisa. O modelo se destaca em STEM e matemática com análise causal.
Começando a usar o Qwen3-VL-30B-A3B na plataforma Novita AI
A Novita AI oferece múltiplos caminhos para acessar o Qwen3-VL-30B-A3B, adaptados a diferentes níveis de conhecimento técnico e casos de uso. Seja você explorando capacidades de IA ou construindo aplicações de produção, a plataforma fornece as ferramentas necessárias.
Use o playground (disponível agora, sem necessidade de codificação)
- Acesso instantâneo: Cadastre-se e comece a experimentar o Qwen3-VL-30B-A3B em segundos.
- Interface interativa: Teste prompts com suas imagens e visualize as saídas em tempo real.
- Comparação de modelos: Compare as variantes Instruct e Thinking do Qwen3-VL-30B-A3B para seu caso de uso específico.
O playground permite testar vários prompts e ver resultados imediatos sem nenhuma configuração técnica. Perfeito para prototipagem, teste de ideias e compreensão das capacidades do modelo antes da implementação completa.
Integre via API (ativo e pronto para desenvolvedores)
Conecte o Qwen3-VL-30B-A3B a suas aplicações com a API REST unificada da Novita AI.
Opção 1: Integração direta via API
Exemplo em Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Opção 2: Fluxos de trabalho multiagente com o OpenAI Agents SDK
Construa sistemas multiagente sofisticados usando as capacidades avançadas do Qwen3-VL-30B-A3B:
- Integração plug-and-play: Insira o Qwen3-VL-30B-A3B em qualquer fluxo de trabalho do OpenAI Agents.
- Capacidades avançadas de agente: Suporte a transferências, roteamento e integração de ferramentas com compreensão visual.
- Arquitetura escalável: Projete agentes que combinem as capacidades multimodais do Qwen3-VL-30B-A3B com outros modelos especializados.
Opção 3: Conecte-se com plataformas de terceiros
- Ferramentas de desenvolvimento: Integre com IDEs populares e ambientes de desenvolvimento como Cursor, Trae, Qwen Code e Cline por meio de APIs compatíveis com OpenAI e APIs compatíveis com Anthropic.
- Frameworks de orquestração: Conecte-se com LangChain, Dify, CrewAI, Langflow e outras plataformas de orquestração de IA usando conectores oficiais.
- Integração com Hugging Face: A Novita AI atua como provedor oficial de inferência do Hugging Face, garantindo ampla compatibilidade com o ecossistema.
Experimente o Qwen3-VL-30B-A3B hoje
O Qwen3-VL-30B-A3B oferece OCR em 32 idiomas, compreensão de vídeo com contexto de 256K, raciocínio espacial e interação com GUI. Ambas as variantes, Instruct e Thinking, oferecem desempenho pronto para produção para processamento de documentos, perguntas e respostas visuais e raciocínio multimodal complexo.
Comece a experimentar o Qwen3-VL-30B-A3B no Playground da Novita AI.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma forma fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



