

يعالج نموذج Qwen3-VL-30B-A3B الصور والمستندات والفيديو إلى جانب النص باستخدام 30 مليار معامل. يتعامل النموذج مع كل شيء بدءًا من التعرف الضوئي على الحروف (OCR) لـ 32 لغة وصولًا إلى تحليل الفيديو لساعات طويلة بسياق يصل إلى 256K توكن.
تستضيف منصة Novita AI متغيرين للنموذج. يوفر متغير Instruct استجابات سريعة ومباشرة. يعرض متغير Thinking عملية استدلاله للمهام المعقدة. يمكنك الوصول إلى كلا المتغيرين عبر مساحة التجربة أو واجهة برمجة التطبيقات (API).
جرب نسخة تجريبية من Qwen3-VL-30B-A3B
ما هو نموذج Qwen3-VL-30B-A3B؟
ينتمي نموذج Qwen3-VL-30B-A3B إلى فريق Qwen التابع لشركة Alibaba Cloud. يعمل النموذج على بنية MoE (خليط الخبراء) بإجمالي 30.5 مليار معامل، مع تنشيط 3.3 مليار معامل فقط في كل مرة. يقدم هذا التصميم أداءً قويًا مع الحفاظ على تكاليف معقولة.
يقع هذا النموذج بين متغيرات Qwen3-VL الأصغر والنموذج الرائد Qwen3-VL-235B-A22B، حيث يوفر توازنًا بين القدرة والكفاءة. بينما يتفوق نموذج 235B في مهام الاستدلال الأكثر تطلبًا، يقدم متغير 30B قدرات مماثلة بتكلفة أقل وسرعات استدلال أسرع.
أبرز التحسينات تشمل:
- سياق أصلي يصل إلى 256K توكن، قابل للتوسعة حتى 1 مليون توكن
- دعم للتعرف الضوئي على الحروف (OCR) لـ 32 لغة (ارتفاعًا من 19 لغة سابقًا)
- تثبيت مكاني ثنائي وثلاثي الأبعاد
- قدرات على التفاعل مع واجهات المستخدم الرسومية (GUI)
- توليد الأكواد من المدخلات البصرية
- فهم الفيديو مع فهرسة على مستوى الثانية
يخدم متغيران احتياجات مختلفة. متغير Instruct مخصص للسرعة، بينما يتعامل متغير Thinking مع الاستدلالات المعقدة.
أبرز الميزات والتحسينات
قدرات الوكيل البصري
يتعرف النموذج على عناصر الواجهة ويُكمل المهام على واجهات المستخدم الرسومية لأجهزة الكمبيوتر الشخصية والأجهزة المحمولة. يفهم وظيفة الأزرار وكيفية التنقل بين التطبيقات.
البرمجة البصرية
أعرض لـ Qwen3-VL لقطة شاشة واحصل على كود قابل للعمل. يولد النموذج رسومات Draw.io وHTML وCSS وJavaScript من الصور والفيديوهات.
الإدراك المكاني
يقدر النموذج مواضع الأشياء وزوايا النظر والاحتجابات. يوفر تثبيتًا مكانيًا ثنائي الأبعاد ويمكن التثبيت المكاني ثلاثي الأبعاد لمهام الاستدلال المكاني وتطبيقات الذكاء الاصطناعي المادي (المدمج في الأجسام).
سياق موسع للفيديوهات الطويلة
يتوسع السياق الأصلي البالغ 256K توكن حتى 1 مليون توكن. يتعامل النموذج مع الكتب والفيديوهات التي تصل مدتها إلى ساعات مع استدعاء كامل للمحتوى. تتيح لك الفهرسة على مستوى الثانية الاستعلام عن لحظات محددة.
التعرف الضوئي المتقدم على الحروف (OCR)
يدعم التعرف الضوئي على الحروف (OCR) الآن 32 لغة. يعمل النموذج في الإضاءة المنخفضة، ويتعامل مع التمويه والانحراف، ويقرأ الأحرف النادرة والقديمة، ويحلل المستندات الطويلة مع الحفاظ على بنيتها.
استدلال العلوم والتكنولوجيا والهندسة والرياضيات (STEM)
يتفوق النموذج في التحليل السببي والإجابات المستندة إلى الأدلة لمشاكل العلوم والتكنولوجيا والهندسة والرياضيات.
تعرف محسّن
تتيح مرحلة ما قبل التدريب الأوسع للنموذج التعرف على المشاهير وشخصيات الأنيمي والمنتجات والمعالم النباتية والحيوانات.
بنية النموذج والمواصفات
البنية: Qwen3VLMoeForConditionalGeneration مع مشفر بصري مدمج يعتمد على تقنية ViT
المواصفات الأساسية:
- إجمالي المعاملات: 30.5B
- المعاملات المنشطة: 3.3B
- طول السياق: 256K توكن (أصلي)، قابل للتوسعة حتى 1M
- الصيغ المدعومة: JPEG, PNG, WebP, BMP, فيديو
ثلاث ابتكارات معمارية: Interleaved-MRoPE يخصص التردد الكامل عبر الزمن والعرض والارتفاع من خلال التضمينات الموضعية. هذا يحسن من استدلال الفيديو على المدى الطويل.
DeepStack يدمج ميزات ViT متعددة المستويات لالتقاط التفاصيل الدقيقة وتحسين محاذاة الصورة والنص.
Text-Timestamp Alignment يوفر تحديدًا دقيقًا للأحداث مرتبطًا بالطابع الزمني لنمذجة زمنية أقوى للفيديو.
مقارنة بين متغير Qwen3-VL-30B-A3B-Instruct ومتغير Qwen3-VL-30B-A3B-Thinking
Instruct: سريع ومباشر
يقدم متغير Instruct استجابات فورية دون عرض عمله. تم تحسينه لتحقيق السرعة والإنتاجية العالية.
حالات الاستخدام:
- تصنيف الصور في الوقت الفعلي
- التعرف الضوئي على الحروف (OCR) للمستندات واستخراج النصوص
- إشراف على المحتوى على نطاق واسع
- استدعاءات لواجهة برمجة التطبيقات (API) بكميات كبيرة
- أسئلة وأجوبة بصرية بسيطة
Thinking: استدلال مفصل
يعرض متغير Thinking تحليلًا خطوة بخطوة قبل تقديم الإجابة. يقسم المشاكل المعقدة إلى خطوات منطقية، على غرار طريقة عمل متغير Thinking الأكبر Qwen3-VL-235B-A22B.
حالات الاستخدام:
- مسائل رياضية من الصور
- استدلال بصري متعدد الخطوات
- تحليل المستندات العلمية
- تطبيقات تعليمية
- مهام تتطلب إمكانية التفسير
اختر متغير Instruct لمعظم أحمال العمل الإنتاجية. قم بالتبديل إلى متغير Thinking عندما تحتاج إلى استدلال شفاف أو تتعامل مع مهام تحليلية معقدة.
معايير الأداء
نتائج متغير Thinking
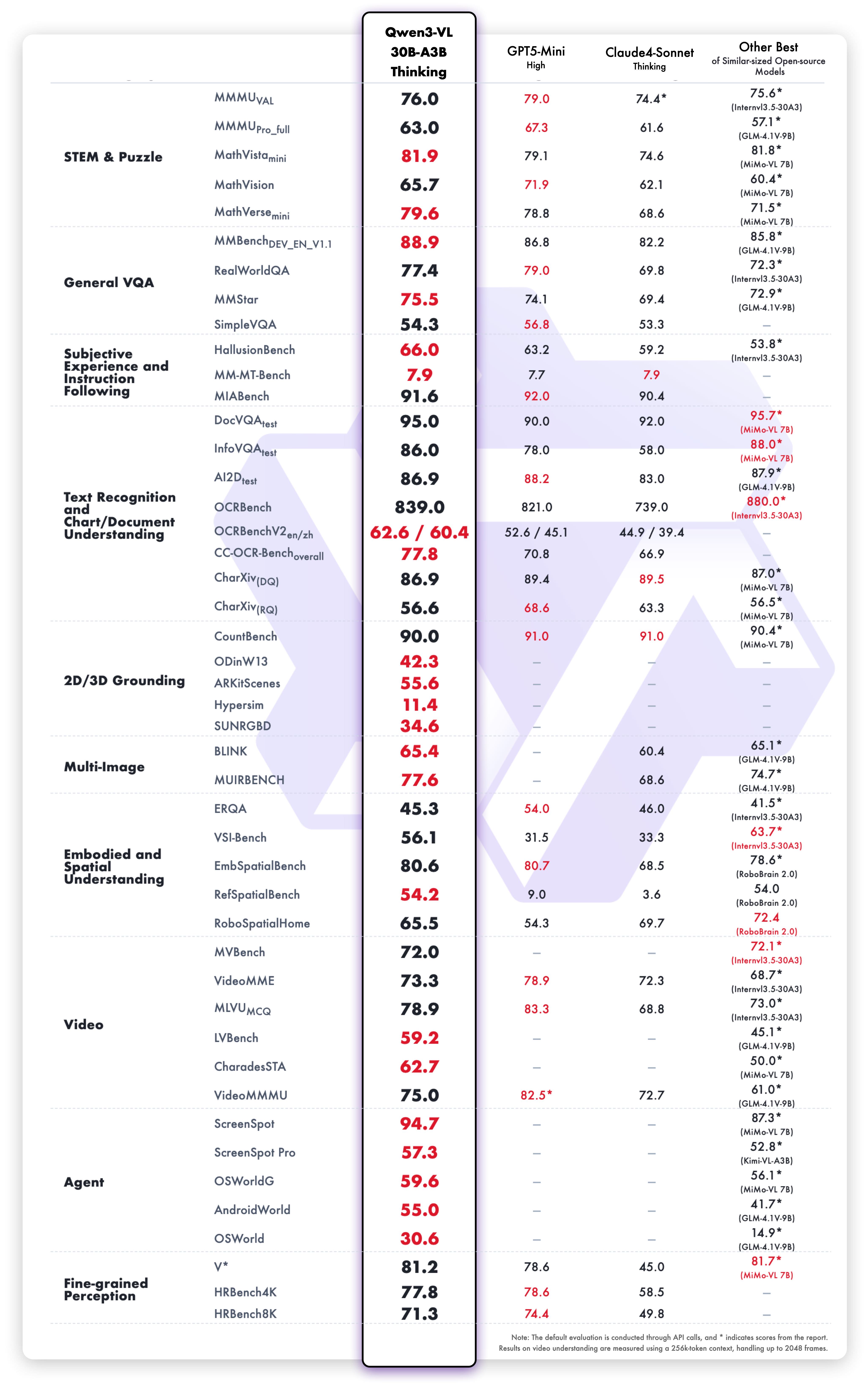
أداء قوي في المجالات التالية:
- استدلال رياضي: MathVista, MathVerse, GeoQA
- أسئلة وأجوبة بصرية: VQAv2, GQA, TextVQA
- المستندات: DocVQA, InfoVQA, ChartQA
- رؤية عامة: MMMU, MMBench, Seed-Bench
- الفيديو: استدلال زمني وأسئلة وأجوبة حول الفيديو
يتعامل استدلال السلسلة الفكرية مع المشاكل متعددة الخطوات عن طريق تقسيمها إلى مراحل منطقية.
نتائج متغير Instruct
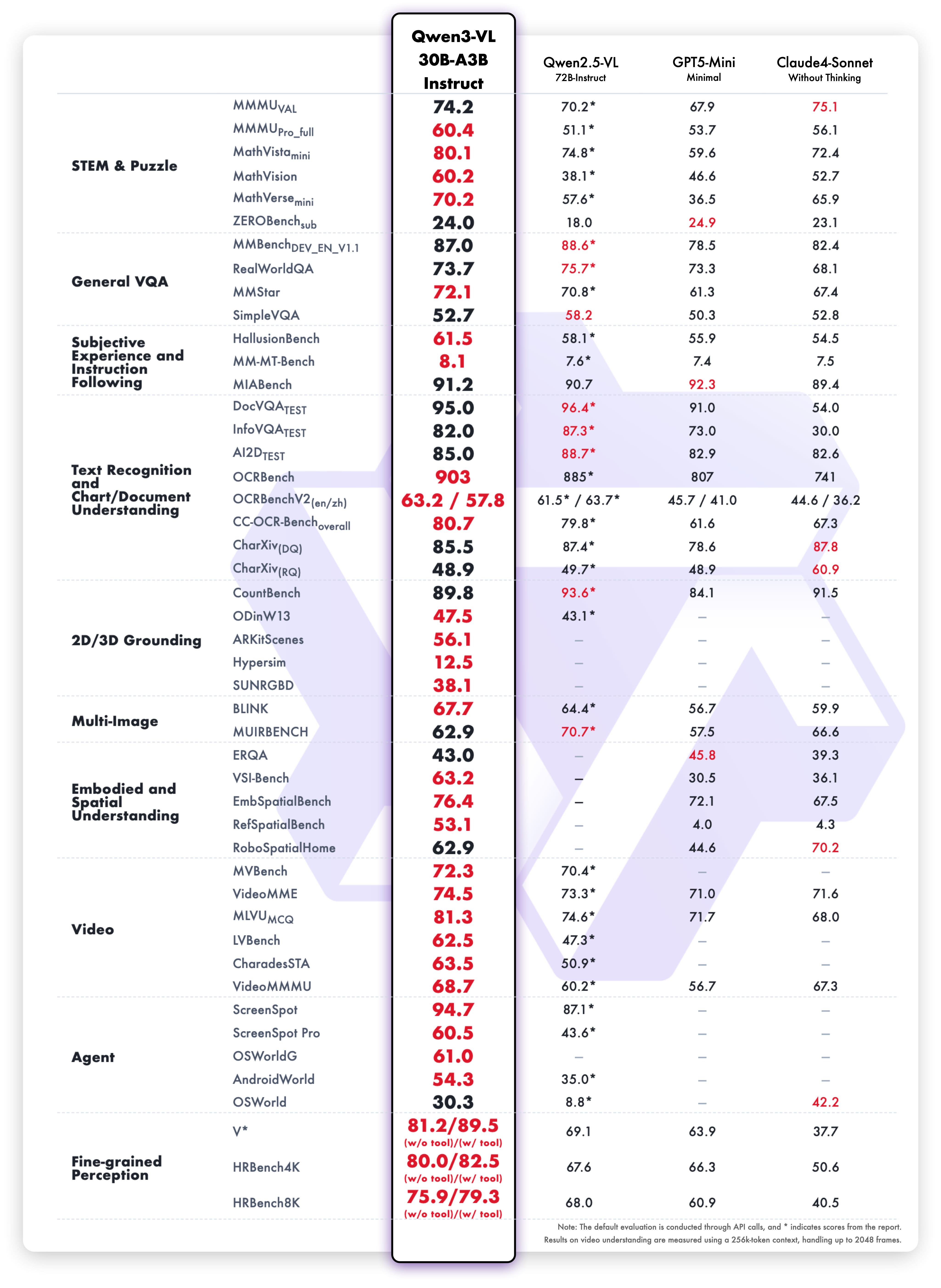
أداء متوازن:
- الرؤية واللغة: معايير الفهم متعدد الوسائط
- مهام النص: الفهم القرائي واللغة
- التعرف الضوئي على الحروف (OCR): دقة استخراج النصوص
- السرعة: زمن استجابة أقل دون التضحية بالجودة
- اللغات: دعم للغات متعددة
يقدم متغير Instruct استدلالًا أسرع مع الحفاظ على الدقة. هذا يجعله مثاليًا عندما تكون السرعة أولوية.
أي متغير تختار
- Thinking: استدلال مفصل، مسائل رياضية، ذكاء اصطناعي قابل للتفسير
- Instruct: استجابات سريعة، إنتاجية عالية، أسئلة وأجوبة مباشرة
تتيح بنية MoE لكلا المتغيرين المنافسة مع النماذج الأكبر بتكلفة أقل.
القدرات الأساسية
الفهم البصري
يولد النموذج أوصافًا بدءًا من العناوين القصيرة وصولًا إلى التحليلات التفصيلية. يتعرف على الأشياء والأشخاص والمشاهد والعلاقات المكانية والمفاهيم المجردة.
معالجة المستندات
يعمل التعرف الضوئي على الحروف (OCR) لـ 32 لغة في ظروف صعبة: إضاءة منخفضة، تمويه، انحراف. يقرأ النموذج الأحرف النادرة والخطوط القديمة والمصطلحات التقنية مع الحفاظ على بنية المستند.
الصيغ المدعومة:
- مستندات ممسوحة ضوئيًا وملفات PDF
- إيصالات وفواتير
- نماذج وجداول
- رسوم بيانية ومخططات
- تخطيطات متعددة الأعمدة
أسئلة وأجوبة بصرية
اطرح أسئلة محددة واحصل على إجابات في سياقها حول:
- عدد الأشياء وسماتها
- العلاقات المكانية
- الإجراءات والأنشطة
- تكوين المشهد
- المفاهيم المجردة
الرياضيات والعلوم
يحل متغير Thinking المشاكل من الصور. يقرأ المعادلات ويُفسر المخططات ويعرض حلولًا لمشاكل الهندسة والجبر والمسائل اللفظية.
تحليل الفيديو
سياق يصل إلى 256K توكن (قابل للتوسعة حتى 1 مليون توكن) يتعامل مع الفيديوهات التي تصل مدتها إلى ساعات. تتتبع الفهرسة على مستوى الثانية الأحداث عبر الزمن.
التفاعل مع واجهات المستخدم الرسومية (GUI)
يتعرف النموذج على عناصر الواجهة ويفهم وظائفها ويُكمل المهام. هذا يتيح أتمتة سير العمل البصري.
توليد الأكواد من المدخلات البصرية
قم بتوليد رسومات Draw.io وHTML وCSS وJavaScript من الصور والفيديوهات. أعرض نموذجًا أوليًا لواجهة المستخدم واحصل على كود قابل للعمل.
الاستدلال المكاني
تثبيت مكاني ثنائي وثلاثي الأبعاد للمهام المكانية. يقدر النموذج المواضع وزوايا النظر والاحتجابات.
تطبيقات واقعية
التجارة الإلكترونية
توليد أوصاف للمنتجات من الصور. استخراج سمات اللون والحجم والمادة. وضع علامات تلقائية على المخزون. مطابقة استعلامات العملاء مع صور المنتجات.
الرعاية الصحية
معالجة النماذج والتقارير الطبية. استخراج بيانات منظمة من المستندات السريرية. قراءة صور الوصفات الطبية. تفسير الملاحظات المكتوبة بخط اليد والنماذج المنظمة.
التعليم
مساعدة الطلاب على حل واجباتهم المنزلية من صور الكتب المدرسية. شرح المخططات والرسوم البيانية والرسوم العلمية. تصحيح الواجبات البصرية. يقدم متغير Thinking حلولًا خطوة بخطوة.
المالية
معالجة الفواتير والإيصالات والكشوفات المالية. استخراج بنود الفواتير والمجاميع والتواريخ ومعلومات البائعين. يدعم 32 لغة للتعامل مع أنواع المستندات المتنوعة.
دعم العملاء
الإجابة على الأسئلة حول أدلة المنتجات عن طريق تحليل المخططات. استكشاف الأخطاء وإصلاحها من صور العملاء. تتيح قدرات الوكيل البصري توجيه المستخدمين عبر الواجهات.
إشراف على المحتوى
فحص الصور التي يرفعها المستخدمون للكشف عن انتهاكات السياسات. فهم السياق beyond الكشف عن الأشياء. التعامل مع الحالات الحدية التي تتطلب استدلالًا بصريًا.
البحث العلمي
تحليل المخططات العلمية. تفسير الرسوم البيانية. استخراج البيانات من أوراق البحث. يتفوق النموذج في مجالات STEM والرياضيات مع التحليل السببي.
ابدأ استخدام نموذج Qwen3-VL-30B-A3B على منصة Novita AI
تقدم منصة Novita AI مسارات متعددة للوصول إلى نموذج Qwen3-VL-30B-A3B، مصممة لتناسب مستويات الخبرة التقنية المختلفة وحالات الاستخدام. سواء كنت تستكشف قدرات الذكاء الاصطناعي أو تبني تطبيقات إنتاجية، توفر المنصة الأدوات التي تحتاجها.
استخدم مساحة التجربة (متاحة الآن، لا تتطلب برمجة)
وصول فوري: سجل حسابك وابدأ التجربة مع Qwen3-VL-30B-A3B في ثوانٍ.
واجهة تفاعلية: اختبر الأوامر مع صورك وشاهد المخرجات في الوقت الفعلي.
مقارنة النماذج: قارن بين متغيري Instruct وThinking من Qwen3-VL-30B-A3B لحالة الاستخدام الخاصة بك.
تتيح لك مساحة التجربة اختبار أوامر مختلفة ورؤية نتائج فورية دون أي إعداد تقني. مثالية للنماذج الأولية، واختبار الأفكار، وفهم قدرات النموذج قبل التنفيذ الكامل.
التكامل عبر واجهة برمجة التطبيقات (API) (متاحة الآن وجاهزة للمطورين)
اربط نموذج Qwen3-VL-30B-A3B بتطبيقاتك باستخدام واجهة برمجة التطبيقات REST الموحدة من Novita AI.
الخيار 1: تكامل مباشر عبر واجهة برمجة التطبيقات (API)
مثال بلغة بايثون:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
الخيار 2: سير عمل متعدد الوكلاء باستخدام حزمة OpenAI Agents SDK
ابنِ أنظمة متعددة الوكلاء متطورة باستخدام القدرات المتقدمة لنموذج Qwen3-VL-30B-A3B: تكامل جاهز للاستخدام: أضف نموذج Qwen3-VL-30B-A3B إلى أي سير عمل لوكلاء OpenAI. قدرات متقدمة للوكلاء: دعم لعمليات التسليم والتوجيه وتكامل الأدوات مع الفهم البصري. بنية قابلة للتوسعة: صمم وكلاء يجمعون بين القدرات متعددة الوسائط لنموذج Qwen3-VL-30B-A3B والنماذج المتخصصة الأخرى.
الخيار 3: الاتصال بالمنصات الخارجية
أدوات التطوير: تكامل مع بيئات التطوير المتكاملة (IDEs) الشائعة مثل Cursor وTrae وQwen Code وCline عبر واجهات برمجة التطبيقات المتوافقة مع OpenAI وواجهات برمجة التطبيقات المتوافقة مع Anthropic. أطر تنسيق سير العمل: الاتصال بـ LangChain وDify وCrewAI وLangflow ومنصات تنسيق الذكاء الاصطناعي الأخرى باستخدام موصلات رسمية. تكامل مع منصة Hugging Face: تعمل Novita AI كموفر استدلال رسمي لمنصة Hugging Face، مما يضمن توافقًا واسعًا مع النظام البيئي.
جرب نموذج Qwen3-VL-30B-A3B اليوم
يقدم نموذج Qwen3-VL-30B-A3B تعرفًا ضوئيًا على الحروف (OCR) لـ 32 لغة، وفهمًا للفيديو بسياق 256K توكن، واستدلالًا مكانيًا، وتفاعلًا مع واجهات المستخدم الرسومية. يوفر كلا المتغيرين Instruct وThinking أداءً جاهزًا للإنتاج لمعالجة المستندات والأسئلة والأجوبة البصرية والاستدلال متعدد الوسائط المعقد.
ابدأ التجربة مع نموذج Qwen3-VL-30B-A3B في مساحة تجربة Novita AI.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.



