

- Что такое Qwen3-VL-30B-A3B?
- Ключевые особенности и улучшения
- Архитектура и спецификации модели
- Сравнение Qwen3-VL-30B-A3B-Instruct и Qwen3-VL-30B-A3B-Thinking
- Бенчмарки производительности
- Основные возможности
- Практические применения
- Начало работы с Qwen3-VL-30B-A3B на платформе Novita AI
- Попробуйте Qwen3-VL-30B-A3B уже сегодня
Qwen3-VL-30B-A3B обрабатывает изображения, документы и видео параллельно с текстом, используя 30 миллиардов параметров. Модель справляется с задачами от OCR на 32 языках до анализа видео длиной в несколько часов с контекстом 256K.
Novita AI предоставляет две вариации модели. Instruct выдаёт быстрые прямые ответы. Thinking демонстрирует процесс рассуждений для сложных задач. Доступ к обеим вариациям открывается через playground или API.
Попробуйте демо Qwen3-VL-30B-A3B
Что такое Qwen3-VL-30B-A3B?
Qwen3-VL-30B-A3B разработана командой Qwen из Alibaba Cloud. Модель построена на архитектуре MoE (Mixture-of-Experts, смесь экспертов) с общим количеством параметров 30,5 миллиарда, из которых активируется 3,3 миллиарда. Такая архитектура обеспечивает высокую производительность при сохранении контролируемой стоимости.
Модель занимает позицию между меньшими вариациями Qwen3-VL и флагманской Qwen3-VL-235B-A22B, балансируя между функциональностью и эффективностью. Если 235B-модель показывает лучшие результаты на самых сложных задачах на рассуждение, то 30B-вариация предоставляет аналогичные возможности при более низкой стоимости и более высокой скорости инференса.
Ключевые улучшения включают:
- Нативный контекст 256K, расширяемый до 1 млн токенов
- Поддержка OCR на 32 языках (увеличение с 19)
- 2D и 3D пространственная привязка
- Возможности взаимодействия с GUI
- Генерация кода на основе визуальных входных данных
- Понимание видео с индексацией на уровне секунд
Две вариации модели подходят для разных задач. Instruct оптимизирована для скорости. Thinking предназначена для сложных задач на рассуждение.
Ключевые особенности и улучшения
Возможности визуального агента
Модель распознаёт элементы интерфейса и выполняет задачи на ПК и мобильных GUI. Она понимает функцию кнопок и принципы навигации по приложениям.
Визуальное программирование
Покажите Qwen3-VL скриншот и получите готовый рабочий код. Модель генерирует диаграммы Draw.io, HTML, CSS и JavaScript на основе изображений и видео.
Пространственное восприятие
Модель определяет положение объектов, точки обзора и перекрытия. Она предоставляет 2D-привязку и поддерживает 3D-привязку для задач на пространственное рассуждение и приложений воплощённого ИИ.
Расширенный контекст для длинных видео
Нативный контекст 256K расширяется до 1 млн токенов. Модель обрабатывает книги и видео длиной в несколько часов с полным сохранением информации. Индексация на уровне секунд позволяет запрашивать отдельные моменты.
Продвинутый OCR
Теперь OCR поддерживает 32 языка. Модель работает в условиях низкой освещённости, справляется с размытием и наклоном, распознаёт редкие и древние символы, а также анализирует длинные документы с сохранением их структуры.
Рассуждение в области STEM и математики
Модель показывает отличные результаты в причинно-следственном анализе и ответах на основе доказательств для задач по естественным наукам, технологиям, инженерии и математике.
Улучшенное распознавание
Более широкое предобучение позволяет модели распознавать знаменитостей, персонажей аниме, товары, достопримечательности, растения и животных.
Архитектура и спецификации модели
Архитектура: Qwen3VLMoeForConditionalGeneration с интегрированным визуальным энкодером на основе ViT
Основные характеристики:
- Общее количество параметров: 30,5B
- Активируемых параметров: 3,3B
- Длина контекста: 256K токенов (нативная), расширяемая до 1 млн
- Поддерживаемые форматы: JPEG, PNG, WebP, BMP, видео
Три архитектурных инновации: Interleaved-MRoPE распределяет полную частоту по времени, ширине и высоте с помощью позиционных эмбеддингов. Это улучшает рассуждение на длинных видео.
DeepStack объединяет многоуровневые признаки ViT для захвата мелких деталей и улучшения согласованности изображения и текста.
Text-Timestamp Alignment обеспечивает точную локализацию событий по временным меткам для более точного временного моделирования видео.
Сравнение Qwen3-VL-30B-A3B-Instruct и Qwen3-VL-30B-A3B-Thinking
Instruct: быстрый и прямой
Вариация Instruct отвечает мгновенно, не показывая процесс работы. Она оптимизирована для скорости и пропускной способности.
Сценарии использования:
- Классификация изображений в реальном времени
- OCR документов и извлечение текста
- Модерация контента в большом объёме
- Высоконагруженные API-запросы
- Простые визуальные вопросы и ответы
Thinking: детальное рассуждение
Вариация Thinking показывает пошаговый анализ перед ответом. Она разбивает сложные проблемы на логические этапы, аналогично тому, как работает большая вариация Qwen3-VL-235B-A22B Thinking.
Сценарии использования:
- Математические задачи с изображений
- Многошаговое визуальное рассуждение
- Анализ научных документов
- Образовательные приложения
- Задачи, требующие объяснимости результатов
Выбирайте Instruct для большинства производственных рабочих нагрузок. Переключайтесь на Thinking, когда вам нужно прозрачное рассуждение или работа со сложными аналитическими задачами.
Бенчмарки производительности
Результаты вариации Thinking
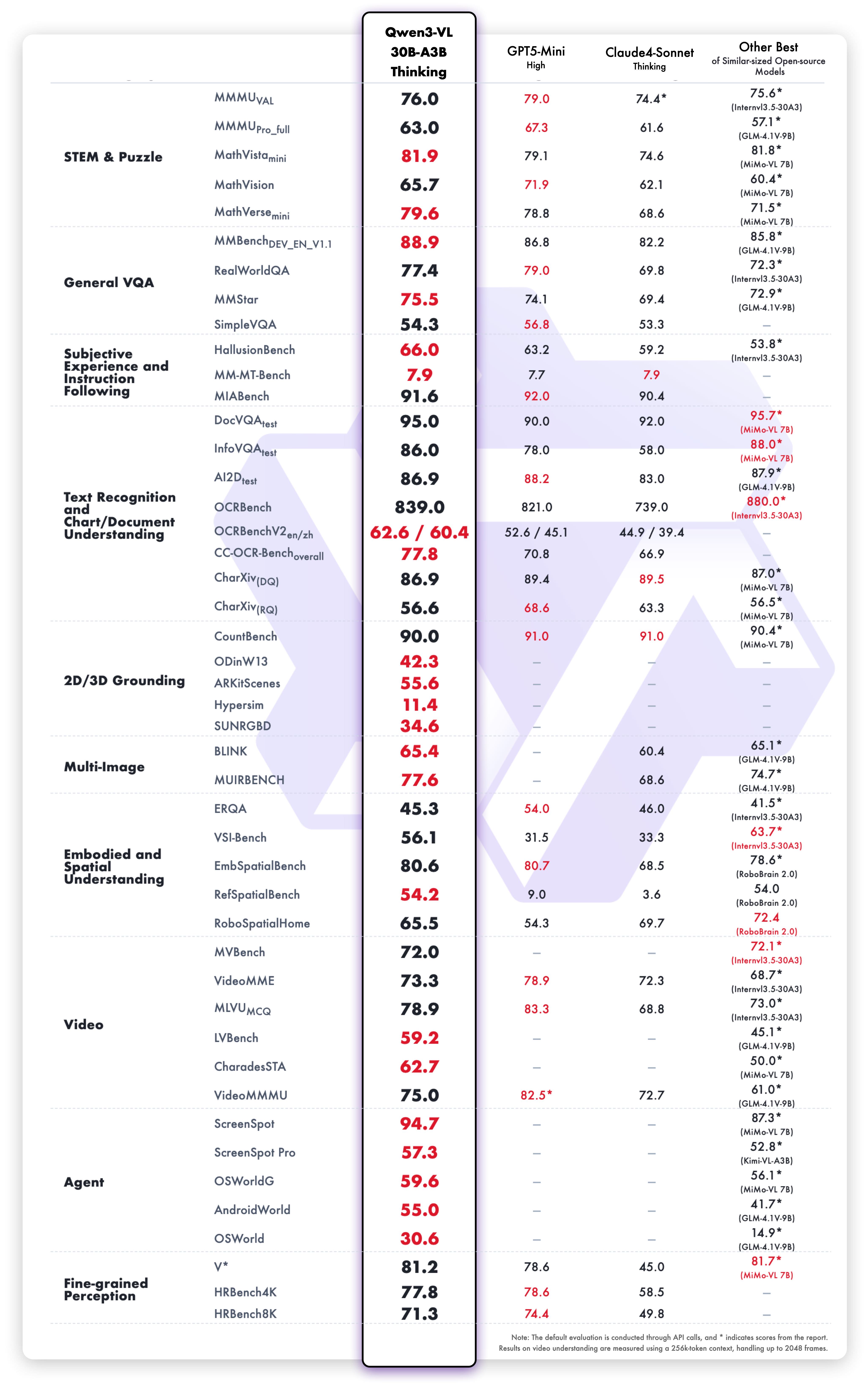
Высокие результаты по направлениям:
- Рассуждение в математике: MathVista, MathVerse, GeoQA
- Визуальные вопросы и ответы: VQAv2, GQA, TextVQA
- Документы: DocVQA, InfoVQA, ChartQA
- Общее зрение: MMMU, MMBench, Seed-Bench
- Видео: Временное рассуждение и вопросы по видео
Рассуждение по цепочке мыслей обрабатывает многошаговые задачи, разбивая их на логические этапы.
Результаты вариации Instruct
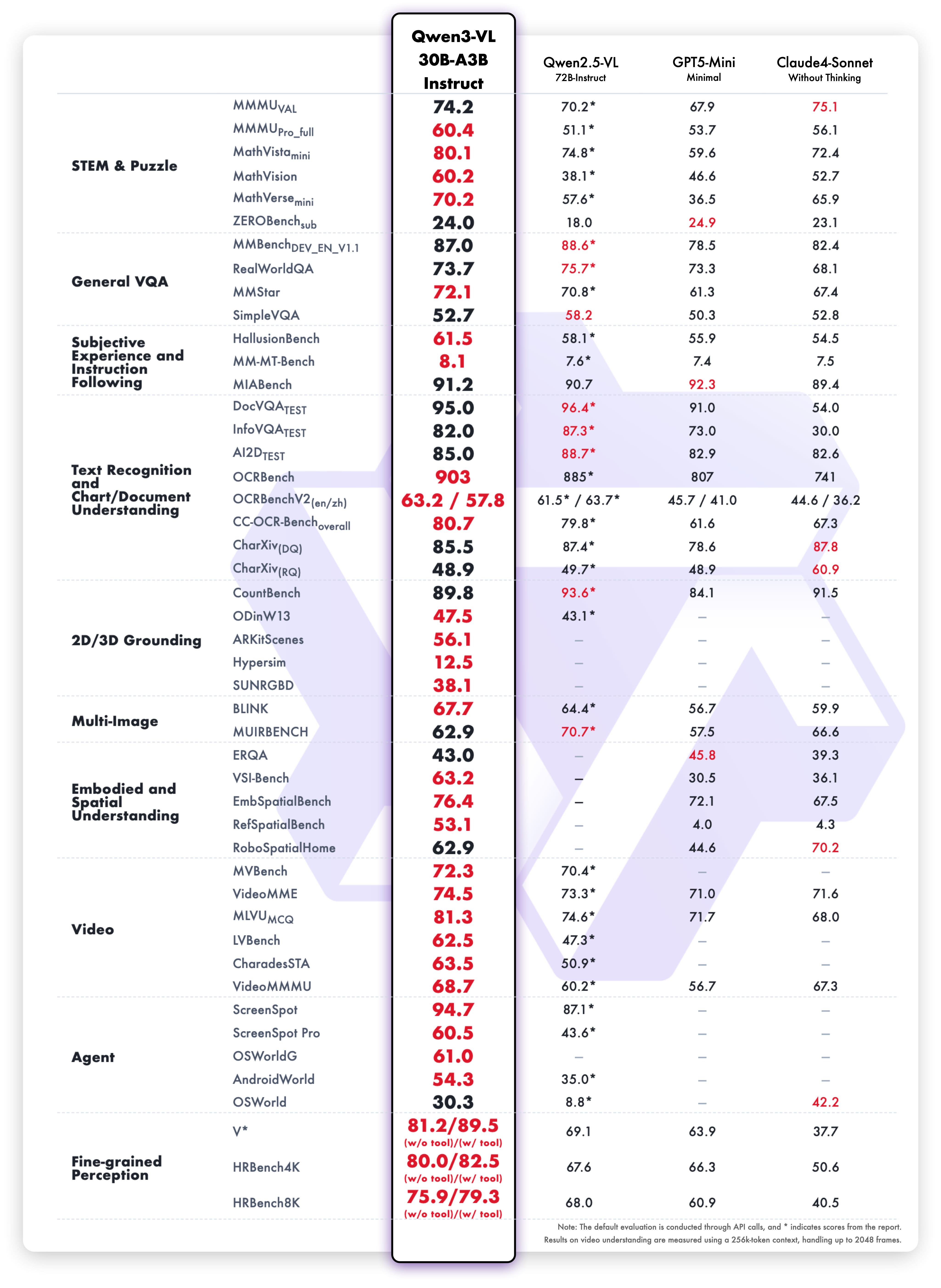
Сбалансированная производительность:
- Визуально-языковые задачи: Бенчмарки мультимодального понимания
- Текстовые задачи: Понимание прочитанного и язык
- OCR: Точность извлечения текста
- Скорость: Более низкая задержка без потери качества
- Языки: Поддержка множества языков
Вариация Instruct обеспечивает более быстрый инференс при сохранении точности. Это делает её идеальным выбором, когда важна скорость.
Как выбрать
- Thinking: Детальное рассуждение, математические задачи, объяснимый ИИ
- Instruct: Быстрые ответы, высокая пропускная способность, простые вопросы и ответы
Архитектура MoE позволяет обеим вариациям конкурировать с более крупными моделями при более низкой стоимости.
Основные возможности
Визуальное понимание
Модель генерирует описания от кратких подписей до детальных анализов. Она идентифицирует объекты, людей, сцены, пространственные отношения и абстрактные концепции.
Обработка документов
OCR на 32 языках работает в сложных условиях: при низкой освещённости, размытии, наклоне. Модель распознаёт редкие символы, древние письменности и технический жаргон, сохраняя структуру документа.
Поддерживаемые форматы:
- Отсканированные документы и PDF-файлы
- Чеки и счета
- Формы и таблицы
- Графики и диаграммы
- Многоколоночные макеты
Визуальные вопросы и ответы
Задавайте конкретные вопросы и получайте контекстуальные ответы о:
- Количестве и атрибутах объектов
- Пространственных отношениях
- Действиях и мероприятиях
- Композиции сцены
- Абстрактных концепциях
Математика и естественные науки
Вариация Thinking решает задачи с изображений. Она считывает уравнения, интерпретирует диаграммы и показывает решения для задач по геометрии, алгебре и текстовым задачам.
Анализ видео
Контекст 256K (расширяемый до 1 млн токенов) позволяет обрабатывать видео длиной в несколько часов. Индексация на уровне секунд отслеживает события во времени.
Взаимодействие с GUI
Модель распознаёт элементы интерфейса, понимает их функции и выполняет задачи. Это позволяет автоматизировать визуальные рабочие процессы.
Генерация кода из визуальных данных
Генерируйте диаграммы Draw.io, HTML, CSS и JavaScript на основе изображений и видео. Покажите макет интерфейса и получите готовый рабочий код.
Пространственное рассуждение
2D и 3D привязка для пространственных задач. Модель определяет положения, точки обзора и перекрытия.
Практические применения
Электронная коммерция
Генерируйте описания товаров на основе фотографий. Извлекайте атрибуты цвета, размера и материала. Автоматически помечайте товары на складе. Сопоставляйте запросы покупателей с изображениями товаров.
Здравоохранение
Обрабатывайте медицинские формы и отчёты. Извлекайте структурированные данные из клинических документов. Считывайте изображения рецептов. Интерпретируйте рукописные заметки и структурированные формы.
Образование
Помогайте студентам решать домашние задания по фотографиям из учебников. Объясняйте диаграммы, графики и научные иллюстрации. Оценивайте визуальные задания. Вариация Thinking предоставляет пошаговые решения.
Финансы
Обрабатывайте счета, чеки и финансовые отчёты. Извлекайте позиции, итоговые суммы, даты и информацию о поставщиках. Поддержка 32 языков позволяет работать с разнообразными типами документов.
Поддержка клиентов
Отвечайте на вопросы по руководствам к товарам, анализируя диаграммы. Решайте проблемы по фотографиям от клиентов. Возможности визуального агента помогают пользователям ориентироваться в интерфейсах.
Модерация контента
Проверяйте загружаемые пользователями изображения на нарушение правил. Понимайте контекст за пределами обнаружения объектов. Обрабатывайте краевые случаи, требующие визуального рассуждения.
Исследования
Анализируйте научные диаграммы. Интерпретируйте графики. Извлекайте данные из научных статей. Модель показывает отличные результаты в STEM и математике с причинно-следственным анализом.
Начало работы с Qwen3-VL-30B-A3B на платформе Novita AI
Novita AI предлагает несколько способов доступа к Qwen3-VL-30B-A3B, адаптированных под разные уровни технической экспертизы и сценарии использования. Независимо от того, изучаете ли вы возможности ИИ или создаёте производственные приложения, платформа предоставляет все необходимые инструменты.
Используйте playground (доступен сейчас, не требует написания кода)
Мгновенный доступ: Зарегистрируйтесь и начните экспериментировать с Qwen3-VL-30B-A3B за несколько секунд.
Интерактивный интерфейс: Тестируйте запросы с вашими изображениями и визуализируйте результаты в реальном времени.
Сравнение моделей: Сравните вариации Qwen3-VL-30B-A3B Instruct и Thinking для вашего конкретного сценария использования.
Игровая площадка позволяет тестировать различные запросы и получать мгновенные результаты без какой-либо технической настройки. Идеально подходит для прототипирования, тестирования идей и понимания возможностей модели перед полной реализацией.
Интеграция через API (работает в реальном времени, готова для разработчиков)
Подключите Qwen3-VL-30B-A3B к вашим приложениям с помощью единого REST API Novita AI.
Вариант 1: Прямая интеграция через API
Пример на Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Вариант 2: Многоагентные рабочие процессы с OpenAI Agents SDK
Создавайте сложные многоагентные системы, используя продвинутые возможности Qwen3-VL-30B-A3B:
- Интеграция из коробки: Добавьте Qwen3-VL-30B-A3B в любой рабочий процесс OpenAI Agents.
- Продвинутые возможности агентов: Поддержка передачи задач, маршрутизации и интеграции инструментов с визуальным пониманием.
- Масштабируемая архитектура: Проектируйте агентов, которые сочетают мультимодальные возможности Qwen3-VL-30B-A3B с другими специализированными моделями.
Вариант 3: Подключение к сторонним платформам
- Инструменты разработки: Интегрируйтесь с популярными IDE и средами разработки, такими как Cursor, Trae, Qwen Code и Cline, через совместимые с OpenAI API и совместимые с Anthropic API.
- Фреймворки оркестрации: Подключайтесь к LangChain, Dify, CrewAI, Langflow и другим платформам оркестрации ИИ с помощью официальных коннекторов.
- Интеграция с Hugging Face: Novita AI является официальным провайдером инференса Hugging Face, что обеспечивает широкую совместимость с экосистемой.
Попробуйте Qwen3-VL-30B-A3B уже сегодня
Qwen3-VL-30B-A3B предоставляет OCR на 32 языках, понимание видео с контекстом 256K, пространственное рассуждение и взаимодействие с GUI. Обе вариации Instruct и Thinking обеспечивают производительность, готовую к промышленному использованию, для обработки документов, визуальных вопросов и ответов, а также сложного мультимодального рассуждения.
Начните экспериментировать с Qwen3-VL-30B-A3B в игровой площадке Novita AI.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развёртывания моделей ИИ с помощью нашего простого API, а также доступное и надёжное облако GPU для построения и масштабирования решений.



