

Qwen3-VL-30B-A3B 使用 300 亿个参数处理图像、文档和视频以及文本。该模型可以处理从 32 种语言的 OCR 到使用 256K 上下文进行长达数小时的视频分析等任务。
Novita AI 提供两种变体。Instruct 提供快速、直接的响应。Thinking 则会展示其针对复杂任务的推理过程。您可以通过 Playground 或 API 访问这两种模型。
什么是 Qwen3-VL-30B-A3B?
Qwen3-VL-30B-A3B 来自阿里巴巴云通义千问团队。该模型基于 MoE(混合专家)架构,总参数为 305 亿,激活参数为 33 亿。这种设计在保持成本可控的同时提供了强劲的性能。
该模型介于较小的 Qwen3-VL 变体和旗舰版 Qwen3-VL-235B-A22B 之间,在能力与效率之间取得了平衡。235B 模型在最具挑战性的推理任务中表现出色,而 30B 变体则以更低的成本和更快的推理速度提供了类似的能力。
主要升级包括:
- 原生 256K 上下文,可扩展至 100 万个 token
- 支持 32 种语言的 OCR(从 19 种提升)
- 2D 和 3D 空间定位
- GUI 交互能力
- 从视觉输入生成代码
- 具有秒级索引的视频理解
两种变体满足不同需求:Instruct 追求速度,Thinking 处理复杂推理。
关键特性与改进
视觉智能体能力
该模型能够识别界面元素,并在 PC 和移动端 GUI 上完成任务。它理解按钮的功能以及如何操作应用程序。
视觉编程
向 Qwen3-VL 展示截图,即可获得可运行的代码。该模型能从图像和视频生成 Draw.io 图表、HTML、CSS 和 JavaScript。
空间感知
模型能够判断物体位置、视角和遮挡情况。它提供 2D 定位,并支持用于空间推理和具身 AI 应用的 3D 定位。
长视频扩展上下文
原生 256K 上下文可扩展至 100 万个 token。模型能够处理书籍和长达数小时的视频,并具有完整的召回能力。秒级索引允许您查询特定时刻。
高级 OCR
OCR 现已支持 32 种语言。模型可在弱光条件下工作,处理模糊和倾斜,读取稀有和古代字符,并解析保留结构的长文档。
STEM 与数学推理
模型在科学、技术、工程和数学问题的因果分析和基于证据的答案方面表现出色。
增强识别
更广泛的预训练使模型能够识别名人、动漫角色、产品、地标、植物和动物。
模型架构与规格
架构: Qwen3VLMoeForConditionalGeneration,集成了基于 ViT 的视觉编码器
核心规格:
- 总参数:305 亿
- 激活参数:33 亿
- 上下文长度:256K token(原生),可扩展至 1M
- 支持的格式:JPEG、PNG、WebP、BMP、视频
三大架构创新:
交织式 MRoPE 通过位置嵌入在时间、宽度和高度上分配完整频率。这改进了长时间范围的视频推理。
DeepStack 融合多级 ViT 特征以捕捉精细细节并增强图像-文本对齐。
文本-时间戳对齐 提供精确的、基于时间戳的事件定位,增强视频时间建模能力。
Qwen3-VL-30B-A3B-Instruct 与 Qwen3-VL-30B-A3B-Thinking
Instruct:快速直接
Instruct 变体立即响应,不展示思考过程。它针对速度和吞吐量进行了优化。
使用场景:
- 实时图像分类
- 文档 OCR 和文本提取
- 大规模内容审核
- 高并发的 API 调用
- 简单的视觉问答
Thinking:详细推理
Thinking 变体在回答前展示逐步分析过程。它类似于更大的 Qwen3-VL-235B-A22B Thinking 变体的操作方式,将复杂问题分解为逻辑步骤。
使用场景:
- 图像中的数学问题
- 多步骤视觉推理
- 科学文档分析
- 教育应用
- 需要可解释性的任务
对于大多数生产工作负载,选择 Instruct。当您需要透明推理或处理复杂分析任务时,切换到 Thinking。
性能基准测试
Thinking 变体结果
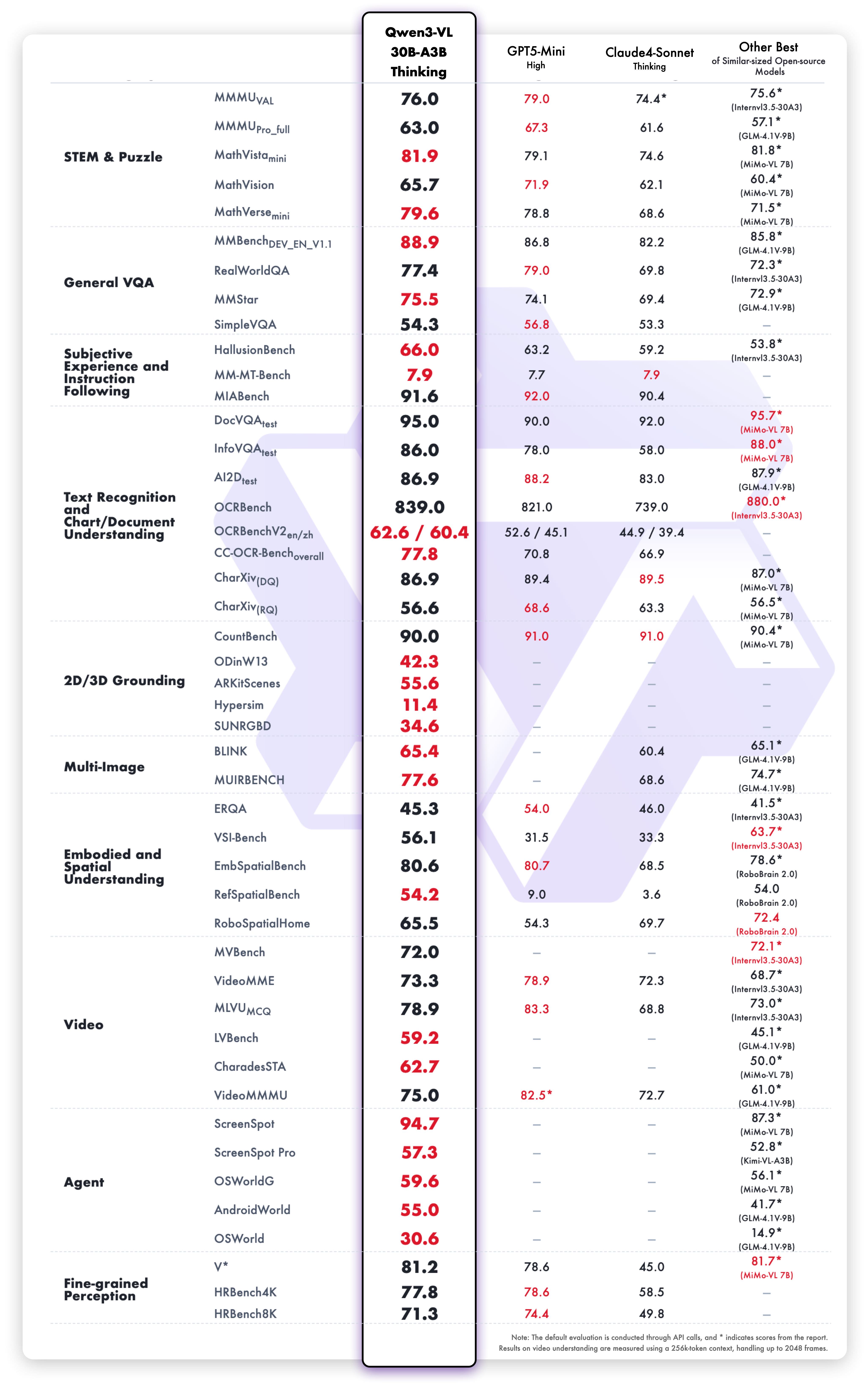
在以下方面表现强劲:
- 数学推理: MathVista、MathVerse、GeoQA
- 视觉问答: VQAv2、GQA、TextVQA
- 文档: DocVQA、InfoVQA、ChartQA
- 通用视觉: MMMU、MMBench、Seed-Bench
- 视频: 时间推理和视频问答
链式思维推理通过将多步问题分解为逻辑阶段来应对。
Instruct 变体结果
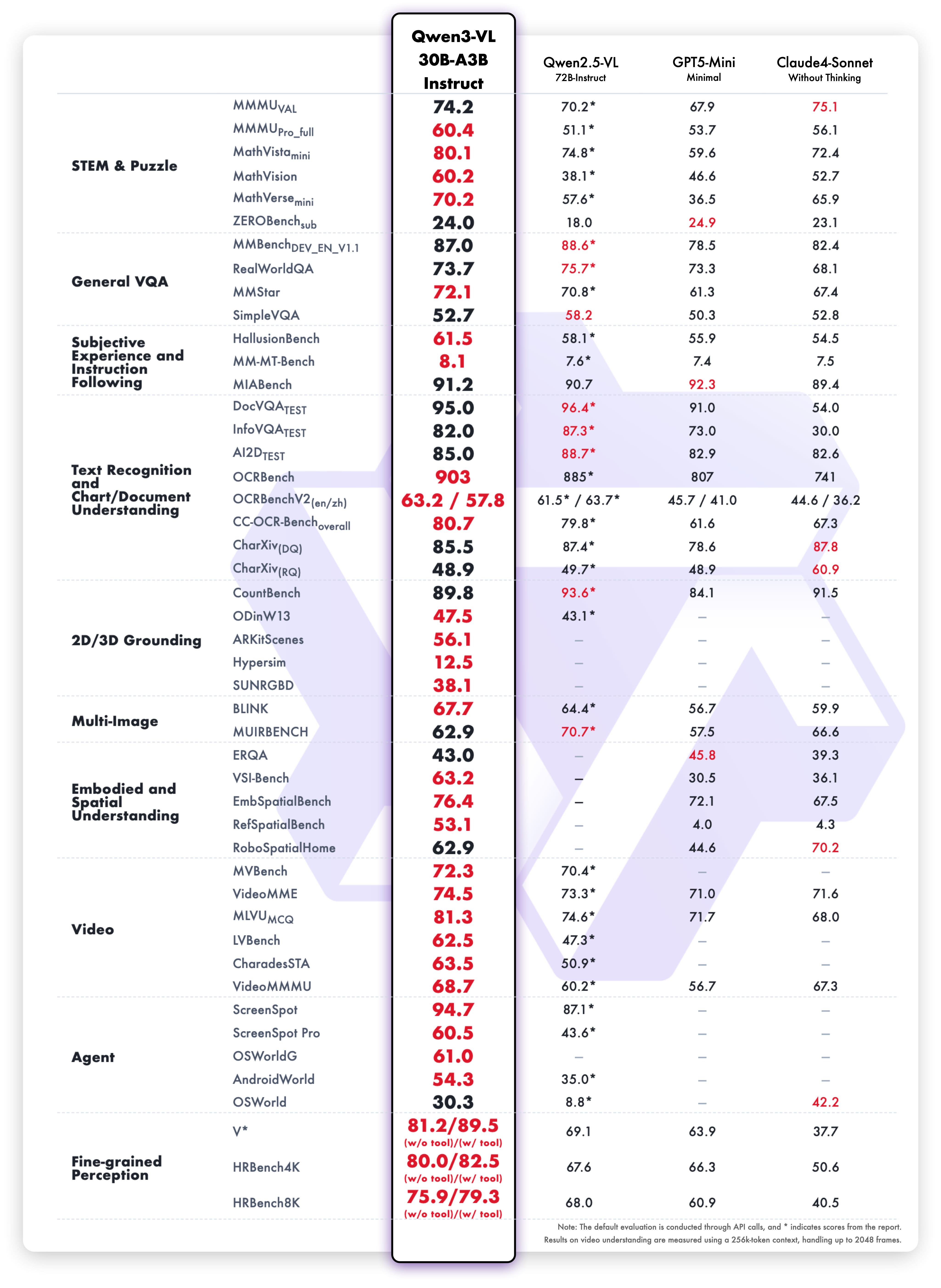
均衡性能:
- 视觉-语言: 多模态理解基准测试
- 文本任务: 阅读理解与语言
- OCR: 文本提取准确性
- 速度: 更低的延迟,同时保持质量
- 语言: 多语言支持
Instruct 变体在保持准确性的同时提供更快的推理速度。这在速度至关重要时是理想选择。
如何选择
MoE 架构使两种变体都能以更低成本与更大模型竞争。
核心能力
视觉理解
该模型能从简短说明到详细分析生成描述。它识别物体、人物、场景、空间关系和抽象概念。
文档处理
32 种语言的 OCR 在具有挑战性的条件下工作:弱光、模糊、倾斜。模型能读取稀有字符、古代文字和技术术语,同时保留文档结构。
支持的格式:
- 扫描文档和 PDF
- 收据和发票
- 表格和表单
- 图表和示意图
- 多列布局
视觉问答
提出具体问题,获得关于以下方面的上下文答案:
- 物体数量和属性
- 空间关系
- 动作和活动
- 场景构成
- 抽象概念
数学与科学
Thinking 变体能够解决图像中的问题。它读取方程、解释图表,并为几何、代数和文字题展示解决方案。
视频分析
256K 上下文(可扩展至 100 万个 token)可处理长达数小时的视频。秒级索引能跨时间追踪事件。
GUI 交互
模型能识别界面元素,理解其功能并完成任务。这实现了视觉工作流自动化。
从视觉生成代码
从图像和视频生成 Draw.io 图表、HTML、CSS 和 JavaScript。展示 UI 模型图即可获得可运行代码。
空间推理
用于空间任务的 2D 定位和 3D 定位。模型能判断位置、视角和遮挡。
实际应用
电子商务
从照片生成产品描述。提取颜色、尺寸和材质属性。自动标记库存。将客户查询与产品图像匹配。
医疗健康
处理医疗表格和报告。从临床文档中提取结构化数据。读取处方图像。解释手写笔记和结构化表格。
教育
帮助学生解答教科书照片中的作业。解释图表、示意图和科学插图。评阅视觉作业。Thinking 变体提供逐步解决方案。
金融
处理发票、收据和财务报表。提取行项目、总计、日期和供应商信息。32 种语言支持可处理多种文档类型。
客户支持
通过分析图表回答产品手册问题。根据客户照片排查问题。视觉智能体能力可引导用户操作界面。
内容审核
筛查用户上传的图片是否违反政策。理解超出物体检测的上下文。处理需要视觉推理的边缘情况。
研究
分析科学图表。解释图表。从研究论文中提取数据。该模型在 STEM 和数学领域擅长因果分析。
在 Novita AI 平台上手 Qwen3-VL-30B-A3B
Novita AI 提供多种途径访问 Qwen3-VL-30B-A3B,针对不同技术水平和用例进行了定制。无论您是在探索 AI 能力还是在构建生产应用程序,该平台都能提供所需工具。
使用 Playground(现已可用,无需编码)
即时访问: 注册即可在数秒内开始体验 Qwen3-VL-30B-A3B。
交互界面: 使用您的图像测试提示,并实时可视化输出。
模型对比: 针对您的具体用例,比较 Qwen3-VL-30B-A3B Instruct 和 Thinking 变体。
Playground 让您无需任何技术设置即可测试各种提示并立即看到结果。非常适合原型设计、测试想法以及在全面实施前了解模型能力。
通过 API 集成(已上线,面向开发者)
使用 Novita AI 的统一 REST API 将 Qwen3-VL-30B-A3B 连接到您的应用程序。
选项 1:直接 API 集成
Python 示例:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
选项 2:使用 OpenAI Agents SDK 的多智能体工作流
利用 Qwen3-VL-30B-A3B 的高级能力构建复杂的多智能体系统:
即插即用集成: 将 Qwen3-VL-30B-A3B 放入任何 OpenAI Agents 工作流。
高级智能体能力: 支持交接、路由和工具集成,结合视觉理解。
可扩展架构: 设计将 Qwen3-VL-30B-A3B 的多模态能力与其他专用模型相结合的智能体。
选项 3:连接第三方平台
开发工具: 通过兼容 OpenAI 和 Anthropic 的 API,与 Cursor、Trae、通义千问代码(Qwen Code)和 Cline 等流行的 IDE 和开发环境集成。
编排框架: 使用官方连接器与 LangChain、Dify、CrewAI、Langflow 等 AI 编排平台连接。
Hugging Face 集成: Novita AI 是 Hugging Face 的官方推理服务提供商,确保广泛的生态系统兼容性。
立即试用 Qwen3-VL-30B-A3B
Qwen3-VL-30B-A3B 提供 32 种语言 OCR、256K 上下文视频理解、空间推理和 GUI 交互。Instruct 和 Thinking 两种变体均为文档处理、视觉问答和复杂多模态推理提供生产级性能。
立即在 Novita AI Playground 开始体验 Qwen3-VL-30B-A3B。
Novita AI 是一个 AI 云平台,为开发者提供简单 API 来部署 AI 模型,同时提供价格实惠且可靠的 GPU 云用于构建和扩展。



