

Qwen3-VL-30B-A3B processes images, documents, and video alongside text using 30 billion parameters. The model handles everything from OCR in 32 languages to hours-long video analysis with 256K context.
Novita AI hosts two variants. Instruct delivers fast, direct responses. Thinking shows its reasoning process for complex tasks. Access both through the playground or API.
What is Qwen3-VL-30B-A3B?
Qwen3-VL-30B-A3B comes from Alibaba Cloud’s Qwen team. The model runs on MoE (Mixture-of-Experts) architecture with 30.5 billion total parameters and 3.3 billion activated. This design delivers strong performance while keeping costs manageable.
The model sits between the smaller Qwen3-VL variants and the flagship Qwen3-VL-235B-A22B, balancing capability with efficiency. Where the 235B model excels at the most demanding reasoning tasks, the 30B variant provides similar capabilities at lower cost and faster inference speeds.
Major upgrades include:
- Native 256K context, expandable to 1M tokens
- OCR support for 32 languages (up from 19)
- 2D and 3D spatial grounding
- GUI interaction capabilities
- Code generation from visual inputs
- Video understanding with second-level indexing
Two variants serve different needs. Instruct works for speed. Thinking handles complex reasoning.
Key features and improvements
Visual agent capabilities
The model recognizes interface elements and completes tasks on PC and mobile GUIs. It understands what buttons do and how to navigate applications.
Visual coding
Show Qwen3-VL a screenshot and get working code. The model generates Draw.io diagrams, HTML, CSS, and JavaScript from images and videos.
Spatial perception
The model judges object positions, viewpoints, and occlusions. It provides 2D grounding and enables 3D grounding for spatial reasoning and embodied AI applications.
Extended context for long videos
Native 256K context expands to 1M tokens. The model handles books and hours-long video with full recall. Second-level indexing lets you query specific moments.
Advanced OCR
OCR now supports 32 languages. The model works in low light, handles blur and tilt, reads rare and ancient characters, and parses long documents while preserving structure.
STEM and math reasoning
The model excels at causal analysis and evidence-based answers for science, technology, engineering, and math problems.
Upgraded recognition
Broader pretraining lets the model recognize celebrities, anime characters, products, landmarks, plants, and animals.
Model architecture and specifications
Architecture: Qwen3VLMoeForConditionalGeneration with integrated ViT-based vision encoder
Core specs:
- Total parameters: 30.5B
- Activated parameters: 3.3B
- Context length: 256K tokens (native), expandable to 1M
- Supported formats: JPEG, PNG, WebP, BMP, video
Three architectural innovations:
Interleaved-MRoPE allocates full frequency over time, width, and height through positional embeddings. This improves long-horizon video reasoning.
DeepStack fuses multi-level ViT features to capture fine details and sharpen image-text alignment.
Text-Timestamp Alignment provides precise, timestamp-grounded event localization for stronger video temporal modeling.
Qwen3-VL-30B-A3B-Instruct vs Qwen3-VL-30B-A3B-Thinking
Instruct: fast and direct
The Instruct variant responds immediately without showing its work. It’s optimized for speed and throughput.
Use cases:
- Real-time image classification
- Document OCR and text extraction
- Content moderation at scale
- High-volume API calls
- Simple visual Q&A
Thinking: detailed reasoning
The Thinking variant shows step-by-step analysis before answering. It breaks down complex problems into logical steps, similar to how the larger Qwen3-VL-235B-A22B Thinking variant operates.
Use cases:
- Math problems from images
- Multi-step visual reasoning
- Scientific document analysis
- Educational applications
- Tasks requiring explainability
Choose Instruct for most production workloads. Switch to Thinking when you need transparent reasoning or handle complex analytical tasks.
Performance benchmarks
Thinking variant results
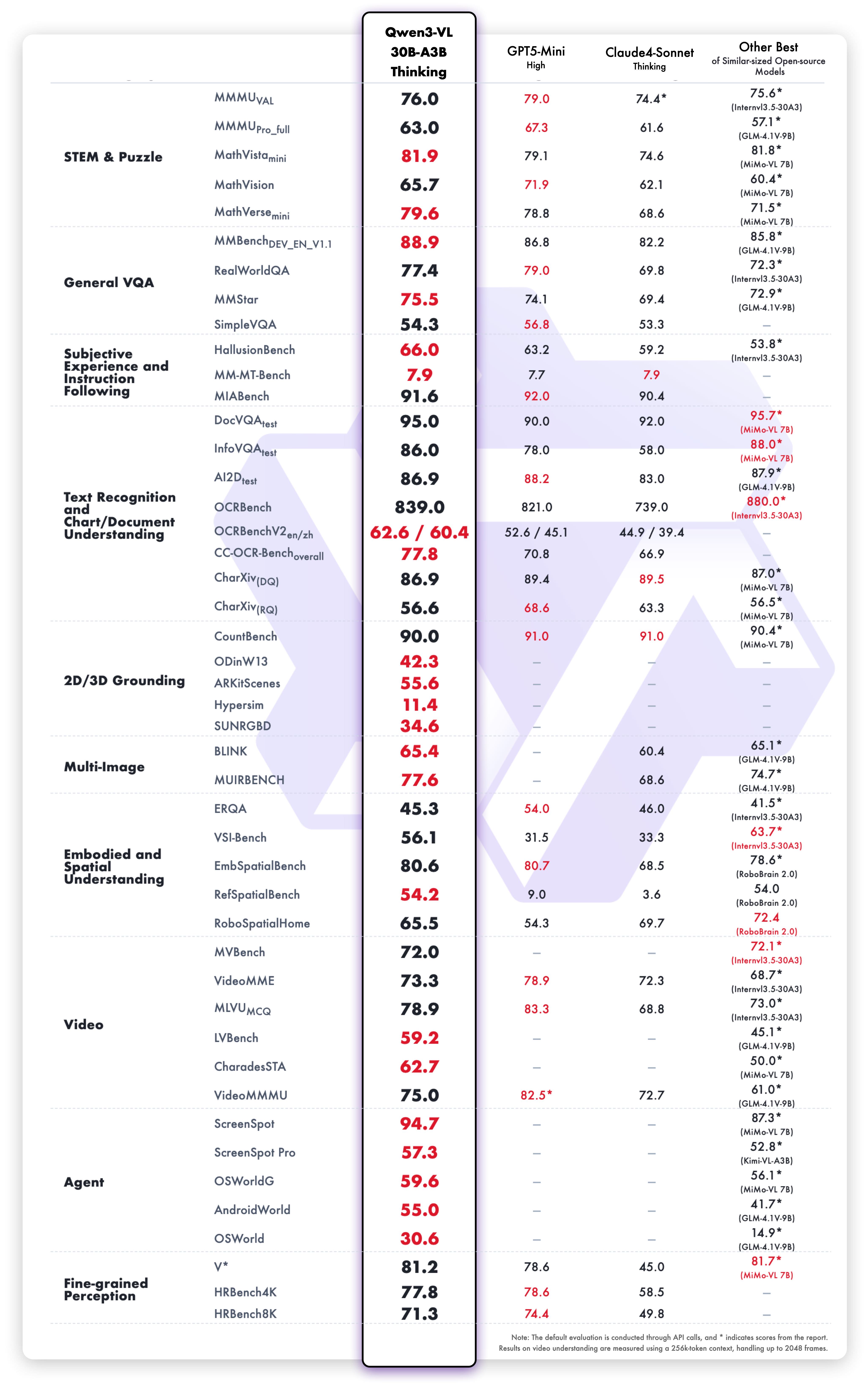
Strong performance across:
- Math reasoning: MathVista, MathVerse, GeoQA
- Visual Q&A: VQAv2, GQA, TextVQA
- Documents: DocVQA, InfoVQA, ChartQA
- General vision: MMMU, MMBench, Seed-Bench
- Video: Temporal reasoning and video Q&A
Chain-of-thought reasoning handles multi-step problems by breaking them into logical stages.
Instruct variant results
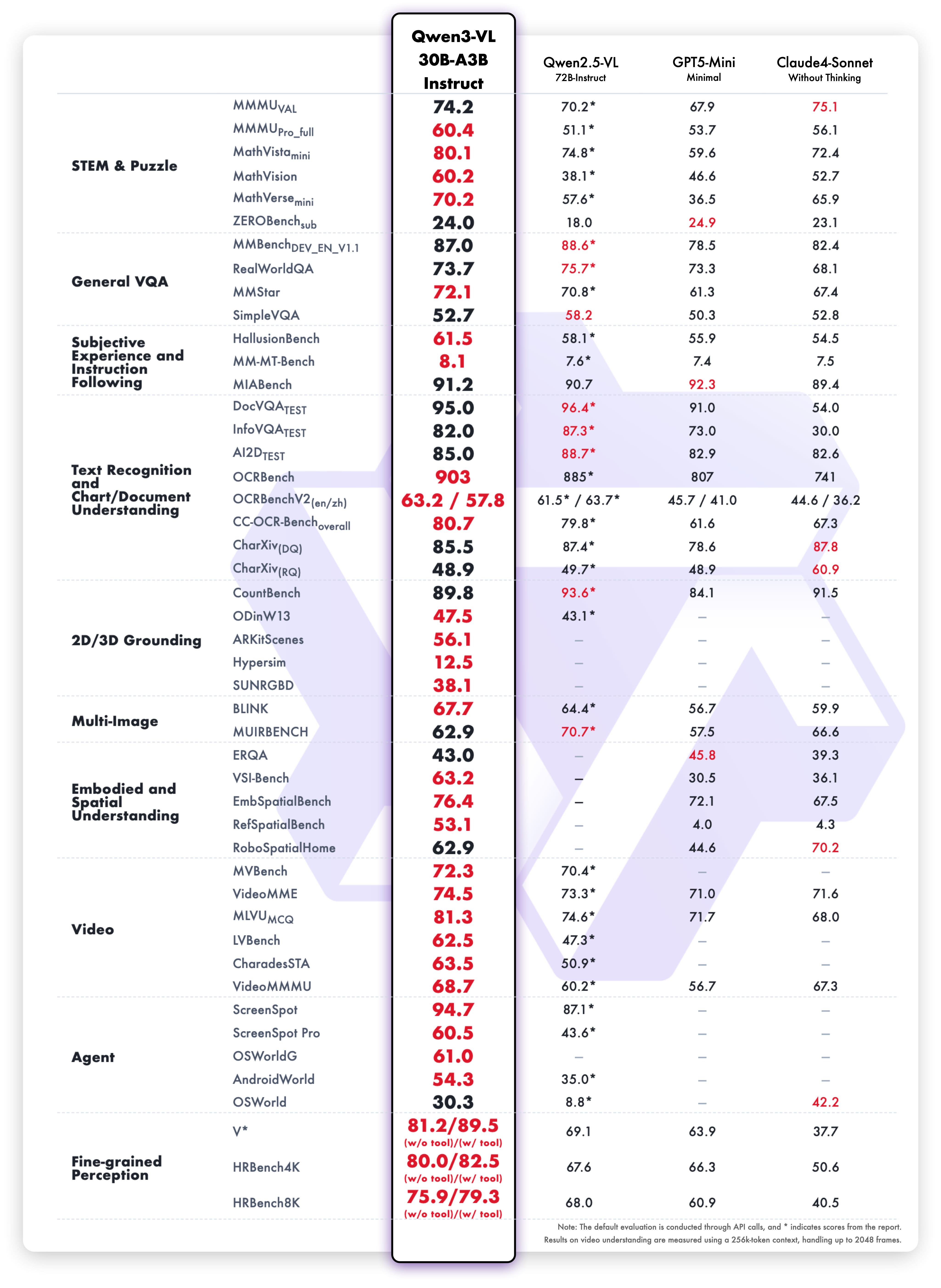
Balanced performance:
- Vision-language: Multimodal understanding benchmarks
- Text tasks: Reading comprehension and language
- OCR: Text extraction accuracy
- Speed: Lower latency without sacrificing quality
- Languages: Multiple language support
The Instruct variant delivers faster inference while maintaining accuracy. This makes it ideal when speed matters.
Which to choose
- Thinking: Detailed reasoning, math problems, explainable AI
- Instruct: Fast responses, high throughput, straightforward Q&A
The MoE architecture lets both variants compete with larger models at lower cost.
Core capabilities
Visual understanding
The model generates descriptions from brief captions to detailed analyses. It identifies objects, people, scenes, spatial relationships, and abstract concepts.
Document processing
32-language OCR works in challenging conditions: low light, blur, tilt. The model reads rare characters, ancient scripts, and technical jargon while preserving document structure.
Supported formats:
- Scanned documents and PDFs
- Receipts and invoices
- Forms and tables
- Charts and diagrams
- Multi-column layouts
Visual Q&A
Ask specific questions and get contextual answers about:
- Object counts and attributes
- Spatial relationships
- Actions and activities
- Scene composition
- Abstract concepts
Math and science
The Thinking variant solves problems from images. It reads equations, interprets diagrams, and shows solutions for geometry, algebra, and word problems.
Video analysis
256K context (expandable to 1M tokens) handles hours-long video. Second-level indexing tracks events across time.
GUI interaction
The model recognizes interface elements, understands their functions, and completes tasks. This enables visual workflow automation.
Code from visuals
Generate Draw.io diagrams, HTML, CSS, and JavaScript from images and videos. Show a UI mockup and get working code.
Spatial reasoning
2D grounding and 3D grounding for spatial tasks. The model judges positions, viewpoints, and occlusions.
Real-world applications
E-commerce
Generate product descriptions from photos. Extract color, size, and material attributes. Tag inventory automatically. Match customer queries to product images.
Healthcare
Process medical forms and reports. Extract structured data from clinical documents. Read prescription images. Interpret handwritten notes and structured forms.
Education
Help students solve homework from textbook photos. Explain diagrams, charts, and scientific illustrations. Grade visual assignments. The Thinking variant provides step-by-step solutions.
Finance
Process invoices, receipts, and financial statements. Extract line items, totals, dates, and vendor information. 32-language support handles diverse document types.
Customer support
Answer questions about product manuals by analyzing diagrams. Troubleshoot issues from customer photos. Visual agent capabilities guide users through interfaces.
Content moderation
Screen user-uploaded images for policy violations. Understand context beyond object detection. Handle edge cases requiring visual reasoning.
Research
Analyze scientific diagrams. Interpret charts. Extract data from research papers. The model excels at STEM and math with causal analysis.
Getting started with Qwen3-VL-30B-A3B on Novita AI platform
Novita AI offers multiple pathways to access Qwen3-VL-30B-A3B, tailored to different technical expertise levels and use cases. Whether you’re exploring AI capabilities or building production applications, the platform provides the tools you need.
Use the playground (available now, no coding required)
Instant access: Sign up and start experimenting with Qwen3-VL-30B-A3B in seconds.
Interactive interface: Test prompts with your images and visualize outputs in real time.
Model comparison: Compare Qwen3-VL-30B-A3B Instruct and Thinking variants for your specific use case.
The playground enables you to test various prompts and see immediate results without any technical setup. Perfect for prototyping, testing ideas, and understanding model capabilities before full implementation.
Integrate via API (live and ready for developers)
Connect Qwen3-VL-30B-A3B to your applications with Novita AI’s unified REST API.
Option 1: Direct API integration
Python example:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)Option 2: Multi-agent workflows with OpenAI Agents SDK
Build sophisticated multi-agent systems using Qwen3-VL-30B-A3B’s advanced capabilities:
Plug-and-play integration: Drop Qwen3-VL-30B-A3B into any OpenAI Agents workflow.
Advanced agent capabilities: Support for handoffs, routing, and tool integration with visual understanding.
Scalable architecture: Design agents that combine Qwen3-VL-30B-A3B’s multimodal capabilities with other specialized models.
Option 3: Connect with third-party platforms
Development tools: Integrate with popular IDEs and development environments like Cursor, Trae, Qwen Code, and Cline through OpenAI-compatible APIs and Anthropic-compatible APIs.
Orchestration frameworks: Connect with LangChain, Dify, CrewAI, Langflow, and other AI orchestration platforms using official connectors.
Hugging Face integration: Novita AI serves as an official inference provider of Hugging Face, ensuring broad ecosystem compatibility.
Try Qwen3-VL-30B-A3B today
Qwen3-VL-30B-A3B delivers 32-language OCR, 256K context video understanding, spatial reasoning, and GUI interaction. Both Instruct and Thinking variants provide production-ready performance for document processing, visual Q&A, and complex multimodal reasoning.
Start experimenting with Qwen3-VL-30B-A3B in the Novita AI Playground.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



