

Qwen3-VL-30B-A3B 擁有 300 億參數,可同時處理圖像、文件、影片與文字。該模型功能涵蓋從 32 語言 OCR 到基於 256K 上下文的數小時影片分析,各類任務都能勝任。
Novita AI 提供兩個版本。Instruct 版本回應快速直接,Thinking 版本會展示複雜任務的推理過程。您可以透過 playground 或 API 使用這兩個版本。
什麼是 Qwen3-VL-30B-A3B?
Qwen3-VL-30B-A3B 源自阿里巴巴雲 Qwen 團隊。該模型採用 MoE(Mixture-of-Experts,混合專家)架構,總參數達 305 億,其中激活參數僅 33 億。這種設計在保持成本可控的同時,能提供強勁的效能。
該模型定位在較小的 Qwen3-VL 系列與旗艦款 Qwen3-VL-235B-A22B 之間,兼備能力與效率。235B 模型在最苛刻的推理任務上表現優異,而 30B 版本則以更低的成本、更快的推理速度提供相近的能力。
主要升級內容包括:
- 原生支援 256K 上下文,可擴展至 100 萬 tokens
- 支援 32 語言 OCR(從 19 種語言升級而來)
- 2D 與 3D 空間定位
- GUI 互動能力
- 可從視覺輸入生成程式碼
- 配備秒級索引的影片理解能力
兩個版本滿足不同需求:Instruct 版本專注速度,Thinking 版本勝任複雜推理。
主要功能與改進
視覺代理能力
該模型可識別介面元素,並在 PC 與行動裝置 GUI 上完成任務。它能理解按鈕功能與應用程式導航方式。
視覺編程
給 Qwen3-VL 提供一張截圖,即可獲得可運行的程式碼。該模型可從圖像與影片生成 Draw.io 圖表、HTML、CSS 與 JavaScript 程式碼。
空間感知
該模型可判斷物體位置、視角與遮擋情況,提供 2D 定位功能,並支援 3D 定位以滿足空間推理與具身 AI 應用的需求。
長影片擴展上下文
原生 256K 上下文可擴展至 100 萬 tokens。該模型可完整處理書籍與數小時長的影片,實現全量記憶。秒級索引功能讓您可以查詢特定時間點的內容。
進階 OCR
OCR 現已支援 32 種語言。該模型可在低光環境下運作,處理模糊、傾斜的文件,辨識罕見字元與古文字,同時在解析長文件時保留原有結構。
STEM 與數學推理
該模型擅長針對科學、技術、工程與數學問題進行因果分析,並提供基於證據的解答。
升級的辨識能力
更廣泛的預訓練讓該模型可以辨識名人、動漫角色、商品、地標、植物與動物。
模型架構與規格
架構: Qwen3VLMoeForConditionalGeneration,搭載整合式基於 ViT 的視覺編碼器
核心規格:
- 總參數:30.5B
- 激活參數:3.3B
- 上下文長度:原生 256K tokens,可擴展至 1M
- 支援格式:JPEG、PNG、WebP、BMP、影片
三大架構創新: Interleaved-MRoPE 透過位置嵌入,在時間、寬度與高度維度上分配完整頻率,提升長時程影片推理能力。
DeepStack 融合多層級 ViT 特徵,捕捉細微細節,強化圖像-文字對齊效果。
Text-Timestamp Alignment 提供精準的、基於時間戳的事件定位,強化影片時間建模能力。
Qwen3-VL-30B-A3B-Instruct 與 Qwen3-VL-30B-A3B-Thinking 比較
Instruct:快速直接
Instruct 版本會立即回應,不會展示推理過程,針對速度與吞吐量進行了最佳化。
適用場景:
- 即時圖像分類
- 文件 OCR 與文字提取
- 大規模內容審核
- 高流量 API 呼叫
- 簡單視覺問答
Thinking:詳細推理
Thinking 版本會在回答前展示逐步分析過程,將複雜問題拆解為邏輯步驟,運作方式與更大的 Qwen3-VL-235B-A22B Thinking 版本 類似。
適用場景:
- 圖像數學題
- 多步驟視覺推理
- 科學文件分析
- 教育應用
- 需要可解釋性的任務
大多數生產環境工作負載建議選擇 Instruct 版本;若需要透明推理或處理複雜分析任務,則切換至 Thinking 版本。
效能基準測試
Thinking 版本測試結果
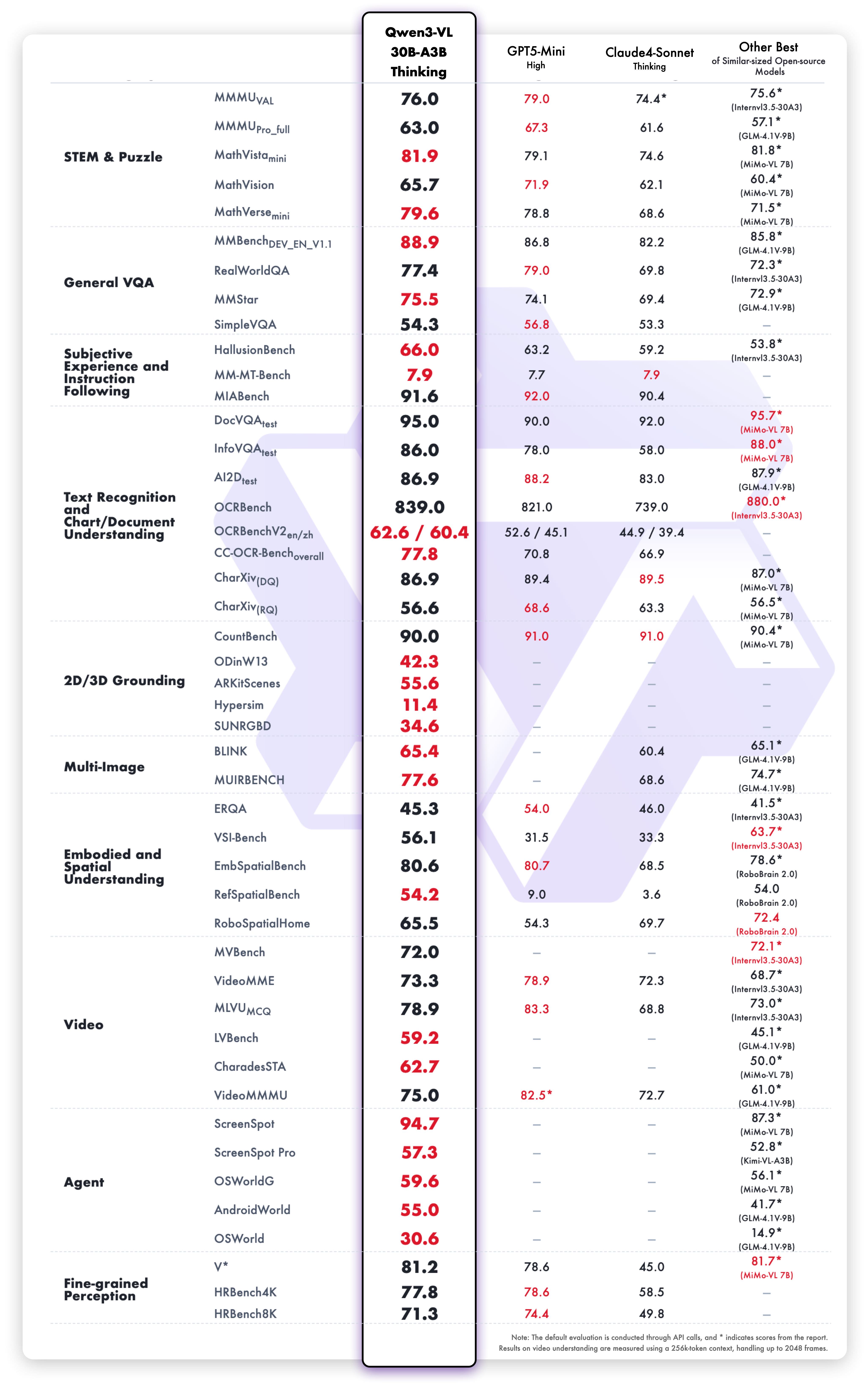
在多項測試中表現優異:
- 數學推理: MathVista、MathVerse、GeoQA
- 視覺問答: VQAv2、GQA、TextVQA
- 文件處理: DocVQA、InfoVQA、ChartQA
- 通用視覺: MMMU、MMBench、Seed-Bench
- 影片處理: 時間推理與影片問答
鏈式思維推理會將多步驟問題拆解為邏輯階段來處理。
Instruct 版本測試結果
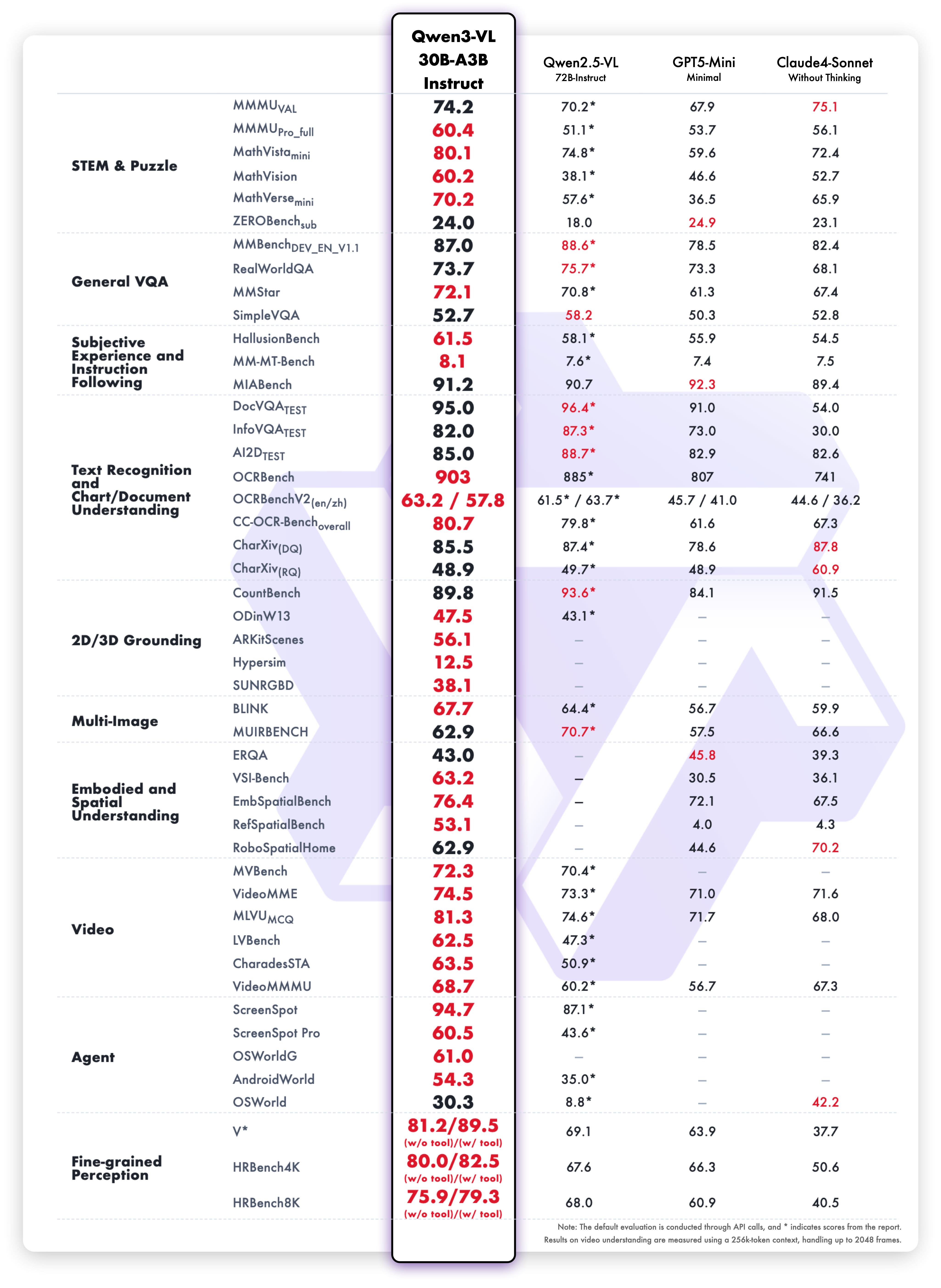
效能表現均衡:
- 視覺語言: 多模態理解基準測試
- 文字任務: 閱讀理解與語言能力
- OCR: 文字提取準確率
- 速度: 低延遲且不犧牲品質
- 語言支援: 多語言支援
Instruct 版本在保持準確率的同時實現更快的推理速度,是對速度有要求的場景的理想選擇。
如何選擇
MoE 架構讓這兩個版本都能以更低的成本與更大的模型競爭。
核心能力
視覺理解
該模型可生成從簡短標註到詳細分析的各類描述,能識別物體、人物、場景、空間關係與抽象概念。
文件處理
32 語言 OCR 可在低光、模糊、傾斜等惡劣條件下運作,能辨識罕見字元、古文字與專業術語,同時保留文件原有結構。
支援格式:
- 掃描文件與 PDF
- 收據與發票
- 表單與表格
- 圖表與圖解
- 多欄排版
視覺問答
提出具體問題,即可獲得相關情境的解答,包括:
- 物體數量與屬性
- 空間關係
- 動作與活動
- 場景構成
- 抽象概念
數學與科學
Thinking 版本可解決圖像中的問題,能讀取方程式、解讀圖解,並提供幾何、代數與應用題的解答。
影片分析
256K 上下文(可擴展至 100 萬 tokens)可處理數小時長的影片,秒級索引功能可追蹤跨時間的事件。
GUI 互動
該模型可識別介面元素、理解其功能並完成任務,實現視覺工作流程自動化。
視覺生成程式碼
可從圖像與影片生成 Draw.io 圖表、HTML、CSS 與 JavaScript 程式碼,提供一張 UI 介面草圖即可獲得可運行的程式碼。
空間推理
針對空間任務提供 2D 與 3D 定位功能,模型可判斷位置、視角與遮擋情況。
實際應用場景
電子商務
根據照片生成商品描述,提取顏色、尺寸、材質等屬性,自動標註庫存,將客戶查詢與商品圖像匹配。
醫療健康
處理醫療表單與報告,從臨床文件中提取結構化數據,辨識處方圖像,解讀手寫筆記與結構化表單。
教育
協助學生解答課本照片中的作業,解釋圖解、圖表與科學插圖,批改視覺類作業,Thinking 版本還可提供逐步解題過程。
金融
處理發票、收據與財務報表,提取明細項目、總額、日期與供應商資訊,32 語言支援可處理各類文件。
客戶支援
透過分析圖解回答產品手冊相關問題,根據客戶照片排查問題,視覺代理能力可引導使用者操作介面。
內容審核
篩選使用者上傳的圖像是否符合政策規範,理解物件檢測之外的上下文,處理需要視覺推理的邊緣案例。
研究
分析科學圖解,解讀圖表,從研究論文中提取數據,該模型在 STEM 與數學領域的因果分析能力表現優異。
在 Novita AI 平台開始使用 Qwen3-VL-30B-A3B
Novita AI 提供多種途徑存取 Qwen3-VL-30B-A3B,針對不同的技術水平與使用場景客製化。無論您是探索 AI 能力還是構建生產環境應用,該平台都能提供您需要的工具。
使用 playground(現已上線,無需編碼)
立即存取: 註冊後即可在幾秒內開始實驗 Qwen3-VL-30B-A3B。
互動介面: 即時測試搭配圖像的提示詞,並可視化查看輸出結果。
模型比較: 針對您的具體使用場景比較 Qwen3-VL-30B-A3B 的 Instruct 與 Thinking 版本。
playground 讓您無需任何技術設定即可測試各類提示詞並查看即時結果,非常適合在完整實施前進行原型驗證、想法測試與了解模型能力。
透過 API 整合(已上線,開發者可立即使用)
使用 Novita AI 的统一 REST API 將 Qwen3-VL-30B-A3B 連接至您的應用程式。
選項 1:直接 API 整合
Python 範例:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-30b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
選項 2:使用 OpenAI Agents SDK 構建多代理工作流
利用 Qwen3-VL-30B-A3B 的進階能力構建複雜的多代理系統:
- 即插即用整合: 可將 Qwen3-VL-30B-A3B 無縫接入任何 OpenAI Agents 工作流。
- 進階代理能力: 支援視覺理解相關的任務交接、路由與工具整合。
- 可擴展架構: 設計可結合 Qwen3-VL-30B-A3B 多模態能力與其他專業模型的代理系統。
選項 3:連接第三方平台
- 開發工具: 透過 OpenAI 相容 API 與 Anthropic 相容 API,與 Cursor、Trae、Qwen Code、Cline 等熱門 IDE 與開發環境整合。
- 編排框架: 使用官方連接器與 LangChain、Dify、CrewAI、Langflow 等 AI 編排平台連接。
- Hugging Face 整合: Novita AI 是 Hugging Face 的官方推理供應商,確保廣泛的生態系統相容性。
立即試用 Qwen3-VL-30B-A3B
Qwen3-VL-30B-A3B 提供 32 語言 OCR、256K 上下文影片理解、空間推理與 GUI 互動能力。Instruct 與 Thinking 兩個版本都能為文件處理、視覺問答與複雜多模態推理任務提供生產級效能。
立即在 Novita AI Playground 開始實驗 Qwen3-VL-30B-A3B。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 以輕鬆部署 AI 模型,同時也提供平價且可靠的 GPU 雲端服務,用於構建與擴展 AI 應用。



