

Qwen3-Next-80B-A3B 是 Qwen3 系列最新發布的大型語言模型,帶來架構與效能上的重大更新。它在推理、編程與長文本理解能力上進步迅速,已成為同級別中最具競爭力的模型之一。
本文將帶你清楚了解 Qwen3-Next-80B-A3B 的突出優勢,並學會三種不同的使用方式:本地部署、GPU 實例運行,或是透過 API 呼叫。
Qwen3-Next-80B-A3B 是什麼:基礎資訊、基準測試與亮點
Qwen3-Next-80B-A3B 總共擁有 800 億個參數,但由於採用高度稀疏的 MoE(混合專家)架構,每次推理時僅會啟動約 30 億個參數。這種設計讓模型能在提供高效能的同時,避免一般同尺寸模型會有的額外計算開銷。實際上,Qwen3-Next-80B-A3B 在訓練與推理階段都達到極高的效率,既足以勝任複雜推理任務,也適合在真實場景中部署。
| 特性 | 詳情 |
| 參數 | 總共 80B,啟動 3B |
| 專家數量 | 總共 512 個,每個 token 啟動 10 個(含 1 個共享專家) |
| 架構 | 高度稀疏混合專家(MoE) |
| 上下文長度 | 原生支援 262,144 tokens,可擴展至 1,010,000 tokens |
| 模式 | 思考/非思考(2 個獨立模型) |
| 多模態 | 僅支援文字 |
| 授權 | Apache 2.0 |
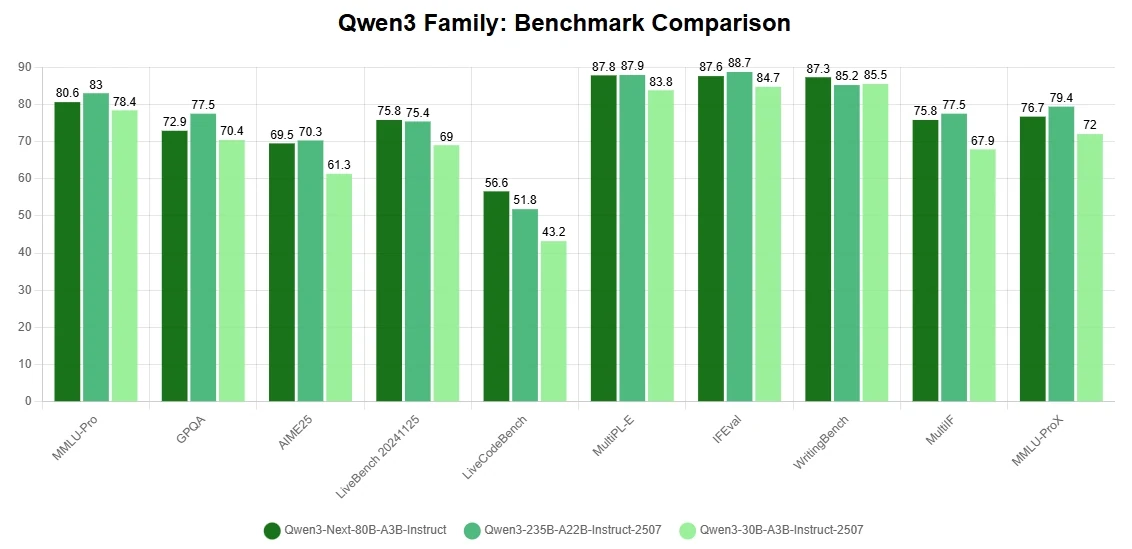
核心亮點
- 架構突破降低訓練成本:採用混合注意力機制、高度稀疏的混合專家結構,以及以穩定性為導向的訓練優化,再加上多 token 預測技術加快推理速度。這些創新讓 Qwen3-Next-80B-A3B 的性能能與甚至超越密集型的 Qwen3-32B,而訓練成本(GPU 時數)卻不到其 10%。
- 長文本推理極致效率:處理超過 32K tokens 的序列時,吞吐量是傳統配置的 10 倍以上。這讓訓練與推理階段都擁有卓越效率,在不犧牲準確率的前提下大幅降低計算成本。
- 頂尖推理與編程能力:在進階推理與編程基準測試中表現優異,屬於目前最強的开源模型之一,是研究與生產級應用的理想選擇。
如何存取 Qwen3-Next-80B-A3B:本地部署
在本地運行 Qwen3-Next-80B-A3B 能讓你獲得最大的控制權與數據安全性。你完全掌控運行環境,可以自由進行微調,所有數據都保留在本地。
- 優點:完全掌控、最適合敏感數據、研究彈性高。
- 缺點:硬體需求極高(80B 參數需要強力 GPU)、設置時間長、後續維護成本高。
在本地運行 Qwen3-Next-80B-A3B 雖然自由,但需要付出高昂的硬體與時間成本——通常至少需要 A100 或 H100 等級的 GPU。這也是許多開發者選擇 GPU 實例的原因:這是一種更聰明的方案,能獲得同等算力,卻無需負擔本地部署的額外開銷。
如何存取 Qwen3-Next-80B-A3B:GPU 實例
透過雲端 GPU 實例運行 Qwen3-Next-80B-A3B,能在性能與易用性之間取得實用的平衡。
優點:
- 無需投入高額成本購買本地硬體
- 彈性擴展,性能接近本地運行
- 相比完全本地環境,設置更快、維護更簡單
缺點:
- 仍需要一定的環境管理(加載模型權重、配置運行時、監控推理過程)
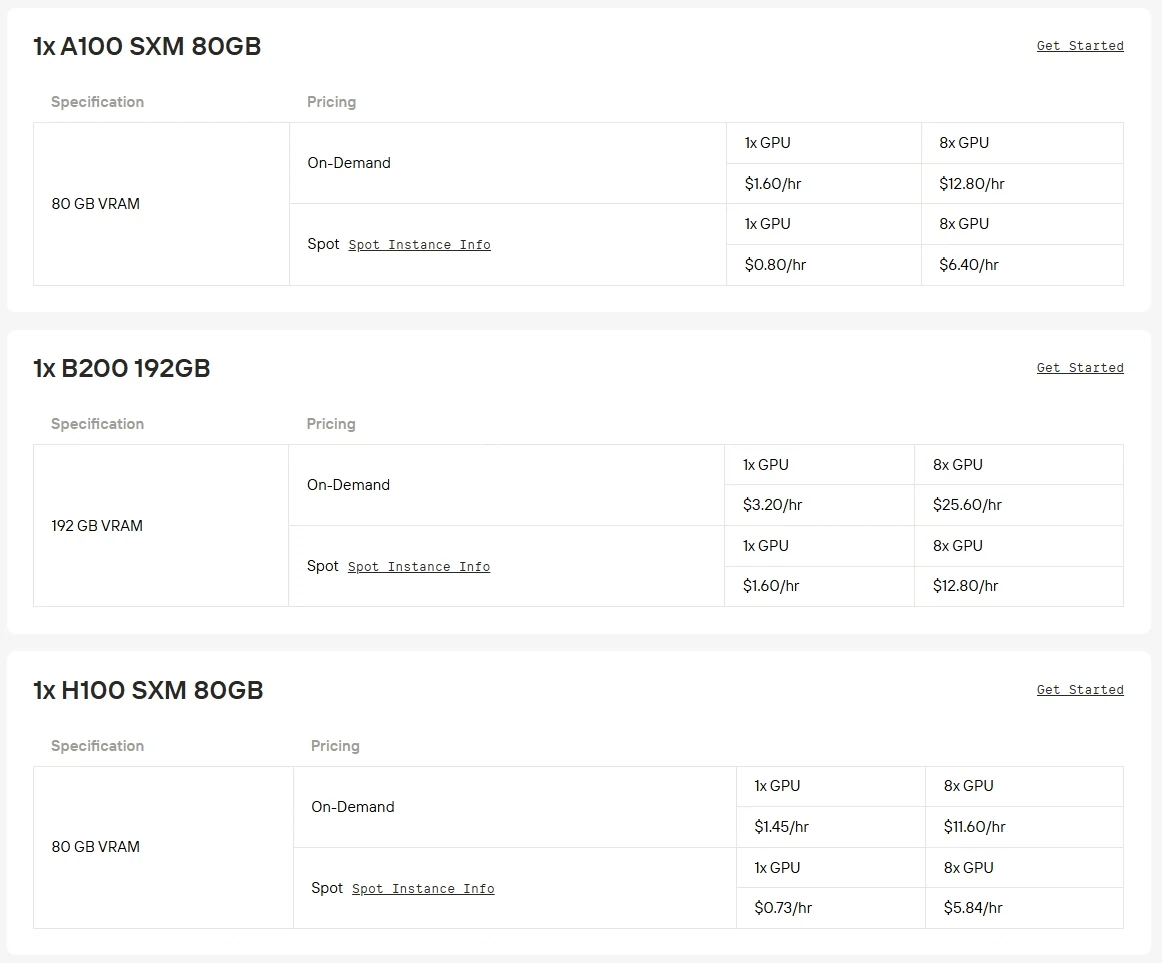
硬體需求: Qwen3-Next-80B-A3B 是 80B 參數的模型,高效推理需要 A100、H100 或 H200 等強力 GPU。由於顯存與吞吐量限制,在消費級 GPU 上運行通常不切實際。
Novita AI 現在提供最高 5 折的企業級 GPU 算力,讓 Qwen3-Next-80B-A3B 這類大型模型比以往更容易取得。立即點擊下方按鈕試用!
Novita AI 也提供 RTX 5090、RTX 6000 Ada 等高階 GPU 選項,搭配有競爭力的價格與彈性計費方案。

為了讓部署同樣高效,Novita AI 也提供 開箱即用模板,省去手動設置的繁雜步驟,降低部署難度。
預配置模板 提供經過驗證的參數、預設環境變量與容器化配置的優化環境,讓你可以立即搭載 DeepSeek、LLaMA 等前沿框架。對於進階用戶,自定義模板支援 可透過個人化腳本、自定義技術棧與微調優化,確保最大的靈活性。
如果你希望完全避免部署與基礎設施管理,Novita AI 的 API 存取是運行 Qwen3-Next-80B-A3B 最省心、成本最低的方案。
如何存取 Qwen3-Next-80B-A3B:API 存取
選項 1:直接 API 整合
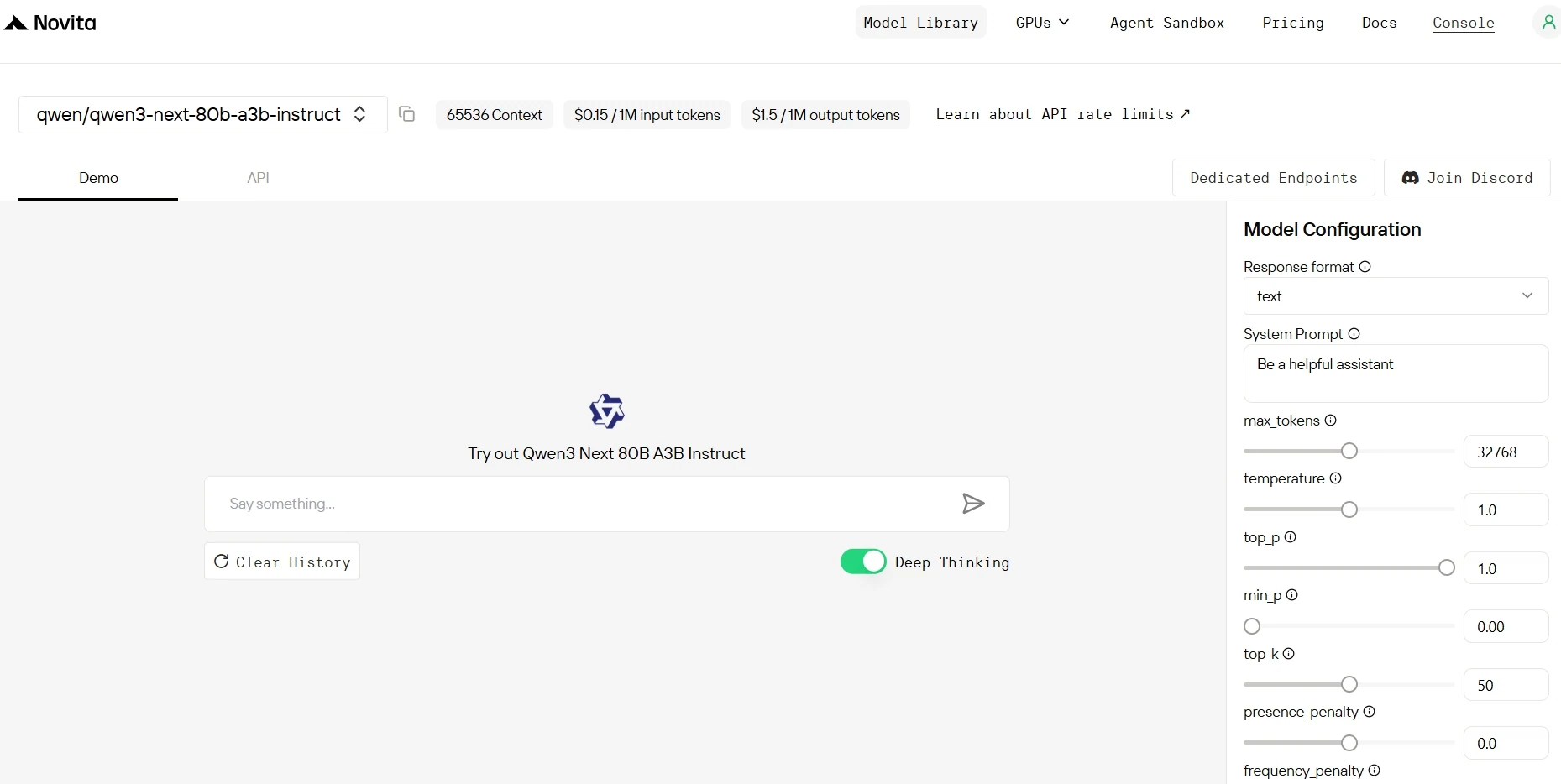
Novita AI 的 API 提供企業級性能——延遲低至 0.85 秒,吞吐量高達 189.6 tps,搭配透明計費,輸入 token 每百萬僅需 0.15 美元,輸出 token 每百萬僅需 1.50 美元,對大規模開發者來說既快速又成本高效。

步驟 1:登入並進入模型庫
登入你的帳號,點擊 模型庫 按鈕。

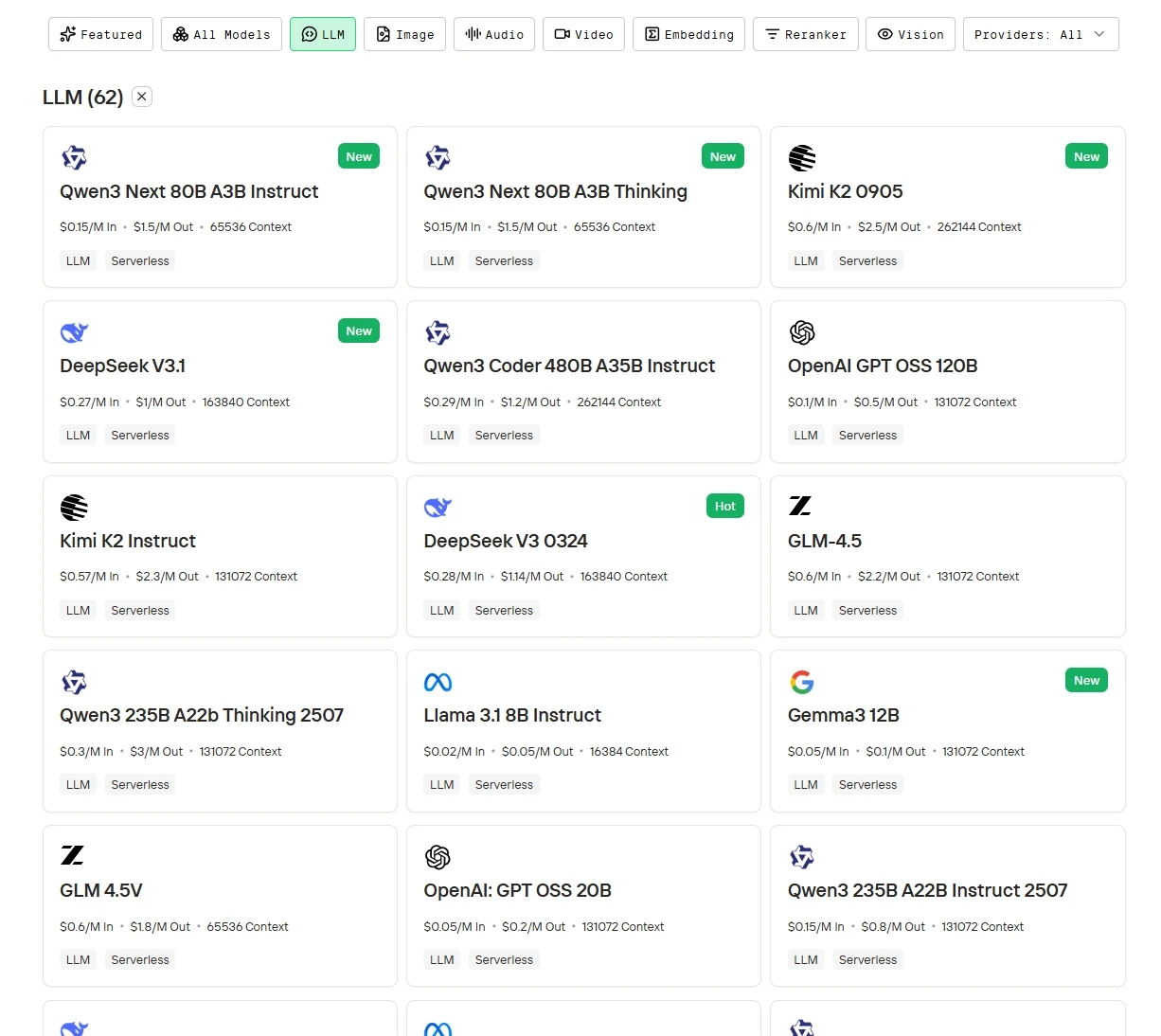
步驟 2:選擇模型
瀏覽可選模型,選擇符合你需求的版本。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:取得 API 金鑰
要進行 API 認證,我們會為你提供新的 API 金鑰。進入「帳號設定」頁面,即可按照圖片指示複製 API 金鑰。

步驟 5:安裝 API 套件
使用對應程式語言的套件管理器安裝 API。
安裝完成後,將必要的函式庫導入你的開發環境,使用 API 金鑰初始化 API,即可開始與 Novita AI 的大型語言模型互動。以下為 Python 使用者呼叫聊天補全 API 的範例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
平台功能:
- OpenAI 相容端點:
/v3/openai實現無縫整合 - 彈性參數:可透過 temperature、top-p、懲罰係數等參數控制生成結果
- 串流支援:可選擇串流回應或批次回應
- 模型選擇:可存取 instruct 與思考兩種變體模型
選項 2:使用 OpenAI Agents SDK 搭建多代理工作流
透過 Novita AI 的基礎設施搭建代理系統,充分利用 Qwen3-Next 的高效能:
- 相容 OpenAI Agents SDK:可搭配 Novita 的端點使用 OpenAI Agents SDK 搭建代理工作流
- 代理能力:可設計能受益於極致稀疏架構與長文本性能的系統
- 簡單整合:將 SDK 指向
https://api.novita.ai/v3/openai即可
如何存取 Qwen3-Next-80B-A3B:第三方整合
- 框架整合:可透過 LangChain、Dify 與 Langflow 存取 Qwen3-Next-80B-A3B
- 開發工具:相容 OpenAI 標準工具,包括 Trae、Claude Code、Qwen Code、Cline 與 Cursor
- Hugging Face 生態系:可透過 Novita AI 的 API 整合至 Hugging Face Spaces 與 pipelines 中
總結
Qwen3-Next-80B-A3B 代表了新一代大型 AI,在工具呼叫能力與複雜任務的進階推理上表現優異。而你存取它的方式,會直接影響實際使用體驗:本地部署能提供完全控制權,但需要極高的硬體規格;GPU 實例在算力與靈活性之間取得平衡;API 存取則是最快速、最無縫的整合路徑。
透過 Novita AI,你可以一站式獲得這三種選項——我們提供有競爭力的價格、開箱即用模板與全球基礎設施支援。無論你是研究人員、新創團隊還是企業用戶,Novita AI 都能讓 Qwen3-Next-80B-A3B 的部署更實惠、更高效。
常見問題
Qwen3-Next-80B-A3B 有哪些關鍵改進?
Qwen3-Next-80B-A3B 採用極致稀疏的混合專家設計,總共 800 億個參數,推理時僅啟動 30 億個。這種高效能讓它在性能上超越 Qwen3-32B,而訓練資源消耗不到其十分之一。其突破性架構——包含混合注意力、1:50 的 MoE 稀疏度與多 token 預測技術——讓推理速度提升超過 10 倍,尤其在長文本任務上表現更為突出。
本地運行 Qwen3-Next-80B-A3B 需要什麼硬體?
本地部署 Qwen3-Next-80B-A3B 通常需要 NVIDIA A100、H100 或 H200 GPU,消費級 GPU 缺乏足夠的顯存與吞吐量,無法勝任。
透過 Novita AI 的 API 使用 Qwen3-Next-80B-A3B 需要多少費用?
在 Novita AI 上,Qwen3-Next-80B-A3B 的 API 使用費用透明計費:每百萬個輸入 token 僅需 0.15 美元,每百萬個輸出 token 僅需 1.50 美元。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 介面,方便部署 AI 模型,同時也提供實惠、可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。



