

- Что такое Qwen3-Next-80B-A3B: Основы, бенчмарки и ключевые особенности
- Как получить доступ к Qwen3-Next-80B-A3B: Локальное развертывание
- Как получить доступ к Qwen3-Next-80B-A3B: GPU-инстансы
- Как получить доступ к Qwen3-Next-80B-A3B: Доступ через API
- Как получить доступ к Qwen3-Next-80B-A3B: Интеграции со сторонними сервисами
- Заключение
Qwen3-Next-80B-A3B — это недавно выпущенная большая языковая модель, которая принесла значительные обновления в серию Qwen3. Благодаря существенным улучшениям в архитектуре и эффективности, её возможности в области рассуждений, программирования и понимания длинного контекста быстро развились, что делает её одной из самых конкурентоспособных моделей в своём классе.
В этой статье вы получите четкое представление о том, что делает Qwen3-Next-80B-A3B особенной, и узнаете о различных способах начать её использование — будь то локальное развертывание, работа с GPU-инстансами или доступ через API.
Что такое Qwen3-Next-80B-A3B: Основы, бенчмарки и ключевые особенности
Qwen3-Next-80B-A3B создана с 80 миллиардами параметров, но только около 3 миллиардов активируются одновременно благодаря её высокоразреженной архитектуре MoE (Mixture-of-Experts). Такая конфигурация позволяет модели обеспечивать высокую производительность, избегая дополнительных вычислений, обычно связанных с моделями такого размера. На практике Qwen3-Next-80B-A3B достигает крайне высокой эффективности как при обучении, так и при инференсе, что делает её достаточно мощной для сложных рассуждений, но при этом ресурсосберегающей для реального развертывания.
| Параметр | Значение |
| Параметры | Всего 80B, активируется 3B |
| Эксперты | Всего 512, активируется 10 на токен (1 общий) |
| Архитектура | Высокораспреженная смесь экспертов (MoE) |
| Длина контекста | 262 144 токена нативно, расширяется до 1 010 000 токенов |
| Режим | Thinking/Non-Thinking (2 отдельные модели) |
| Мультимодальность | Только текст |
| Лицензия | Apache 2.0 |
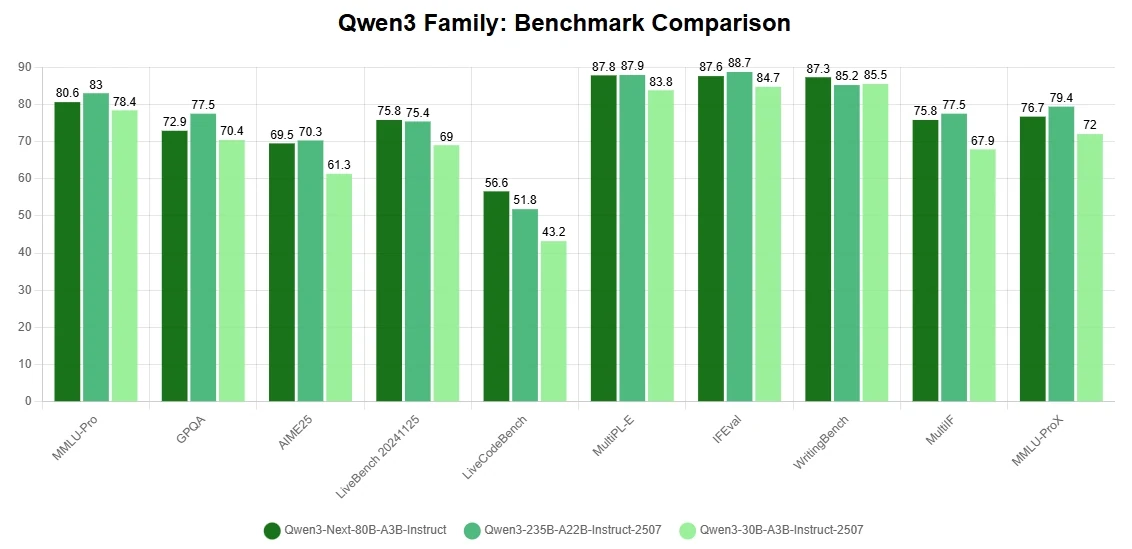
Ключевые особенности
- Прорывные архитектурные решения для снижения стоимости обучения: Модель создана на основе гибридного механизма внимания, высокоразреженной структуры смеси экспертов и оптимизаций обучения, ориентированных на стабильность, а также поддерживает предсказание нескольких токенов для ускорения инференса. Эти инновации позволяют Qwen3-Next-80B-A3B достигать производительности, сравнимой или даже превосходящей плотную модель Qwen3-32B, при потреблении менее 10% от её стоимости обучения (GPU-часы).
- Крайне высокая эффективность инференса на длинном контексте: При обработке последовательностей длиннее 32K токенов модель обеспечивает более чем в 10 раз большую пропускную способность по сравнению с обычными конфигурациями. Это обеспечивает исключительную эффективность как при обучении, так и при инференсе, снижая вычислительные затраты без потери точности.
- Высокий уровень возможностей в рассуждениях и программировании: Показывает отличные результаты на бенчмарках для продвинутых рассуждений и кодирования, входя в число самых сильных открытых моделей. Это делает Qwen3-Next-80B-A3B универсальным выбором как для исследований, так и для производственных приложений.
Как получить доступ к Qwen3-Next-80B-A3B: Локальное развертывание
Запуск Qwen3-Next-80B-A3B локально дает вам максимальный контроль и безопасность данных. Вы владеете средой, можете свободно дообучать модель и хранить всё на своей инфраструктуре.
- Преимущества: Полный контроль, оптимально для конфиденциальных данных, гибкость для исследований.
- Недостатки: Крайне высокие требования к оборудованию (80B параметров требуют мощных GPU), долгое время настройки и постоянные затраты на обслуживание.
Запуск Qwen3-Next-80B-A3B локально дает свободу, но comes with высокими затратами на оборудование и время — обычно требуются GPU как минимум уровня A100 или H100. Именно поэтому многие разработчики используют GPU-инстансы — более умный способ получить такую же мощность без лишних накладных расходов.
Как получить доступ к Qwen3-Next-80B-A3B: GPU-инстансы
Запуск Qwen3-Next-80B-A3B через облачные GPU-инстансы обеспечивает практический баланс между производительностью и доступностью.
Преимущества:
- Не нужно инвестировать в дорогое локальное оборудование
- Эластичное масштабирование с производительностью, близкой к локальной
- Более быстрая настройка и простое обслуживание по сравнению с полностью локальными средами
Недостатки:
- Все ещё требуется некоторое управление средой (загрузка весов модели, конфигурация рантаймов, мониторинг инференса)
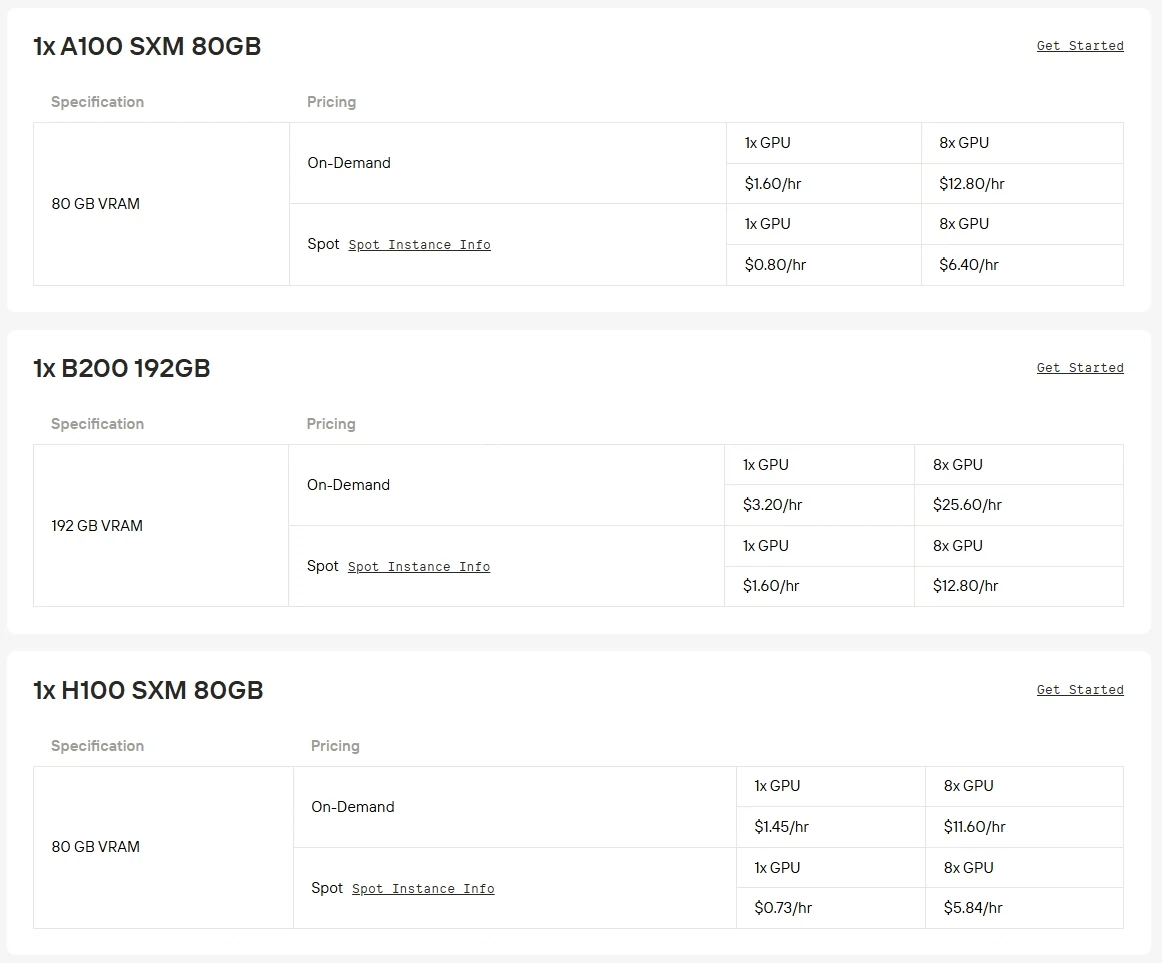
Требования к оборудованию: Qwen3-Next-80B-A3B — это модель с 80B параметров, для эффективного инференса которой требуются мощные GPU, такие как A100, H100 или H200. Запуск на потребительских GPU обычно непрактичен из-за ограничений по объему видеопамяти и пропускной способности.
Novita AI теперь предлагает корпоративную мощность GPU со скидкой до 50%, что делает крупномасштабные модели, такие как Qwen3-Next-80B-A3B, более доступными, чем когда-либо. Нажмите кнопку ниже, чтобы попробовать прямо сейчас!
Попробуйте GPU Novita AI сейчас!
На Novita AI также доступны высокопроизводительные GPU, такие как RTX 5090, RTX 6000 Ada, с гибкой тарификацией по конкурентоспособной цене.

Чтобы сделать развертывание не менее эффективным, Novita AI также предоставляет готовые шаблоны, которые исключают сложность настройки, убирая необходимость ручной конфигурации.
Предварительно настроенные шаблоны предлагают оптимизированные среды с проверенными параметрами, предустановленными переменными окружения и контейнеризированными конфигурациями — так что вы можете запускаться мгновенно с DeepSeek, LLaMA и другими современными фреймворками. Для продвинутых пользователей Поддержка пользовательских шаблонов обеспечивает максимальную гибкость за счет персонализированных скриптов, кастомных стеков и тонко настроенных оптимизаций.
Если вы предпочитаете полностью избежать развертывания и управления инфраструктурой, доступ через API Novita AI предлагает самый простой и экономически эффективный способ запустить Qwen3-Next-80B-A3B.
Как получить доступ к Qwen3-Next-80B-A3B: Доступ через API
Вариант 1: Прямая интеграция с API
API Novita AI предлагает корпоративный уровень производительности — очень низкую задержку 0,85 секунды и высокую пропускную способность 189,6 tps — а также прозрачное ценообразование всего за $0,15 за 1M входных токенов и $1,50 за 1M выходных токенов, что делает его быстрым и экономически эффективным для разработчиков, работающих с большими объемами.

Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Попробуйте Qwen3-Next бесплатно!
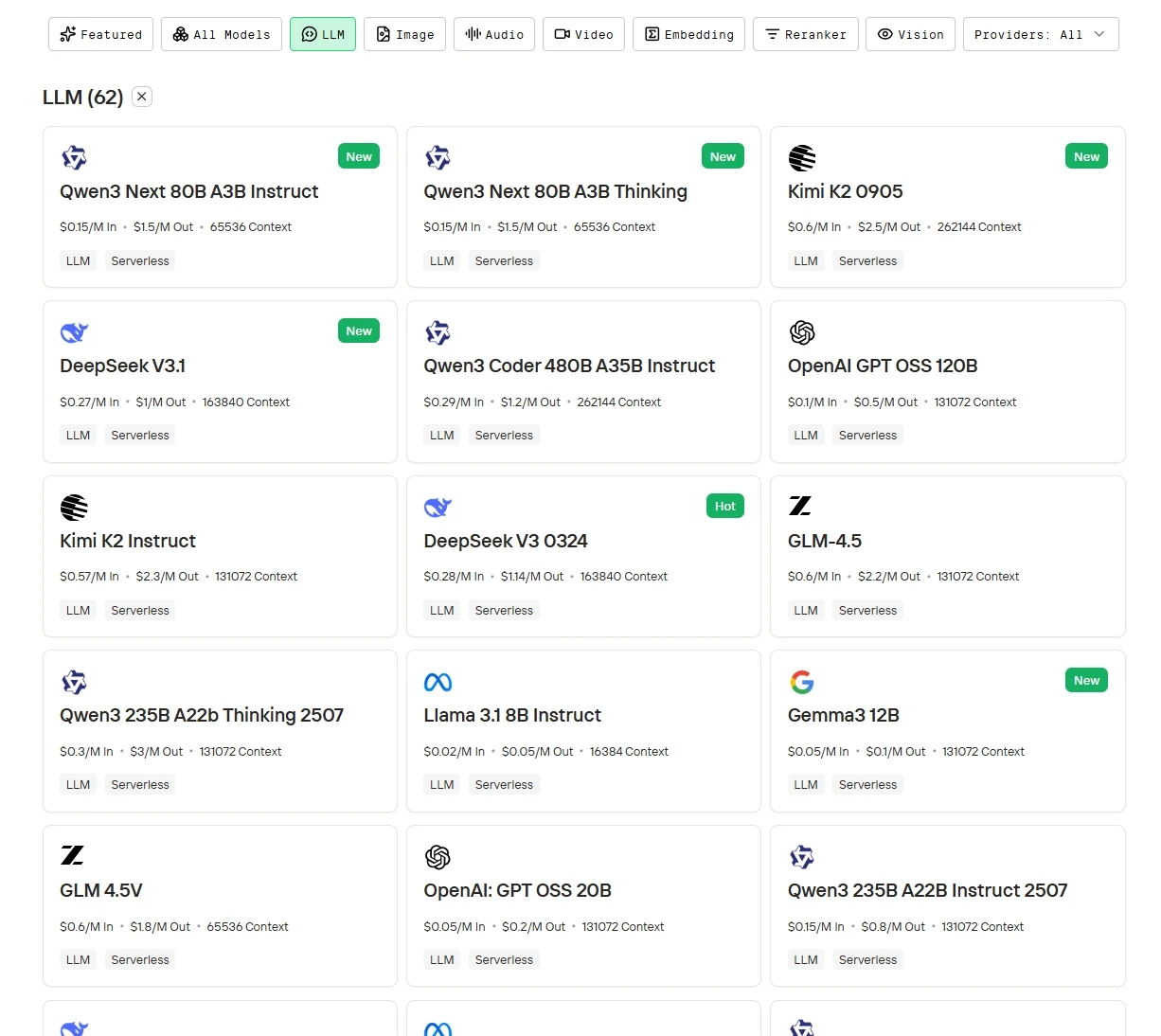
Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит вашим задачам.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки аккаунта», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Это пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Возможности платформы:
- Совместимый с OpenAI endpoint:
/v3/openaiдля бесшовной интеграции - Гибкие параметры: Управляйте генерацией с помощью температуры, top-p, штрафов и других параметров
- Поддержка стриминга: Выбирайте между потоковыми или пакетными ответами
- Выбор модели: Доступны как instruct, так и thinking варианты
Вариант 2: Мультиагентные рабочие процессы с OpenAI Agents SDK
Создавайте агентные системы, которые используют эффективность Qwen3-Next через инфраструктуру Novita AI:
- Совместимость с OpenAI Agents SDK: Используйте OpenAI Agents SDK с endpoint Novita для агентных рабочих процессов
- Возможности агентов: Проектируйте системы, которые получают выгоду от крайне высокой разреженности и производительности на длинном контексте
- Простая интеграция: Направьте SDK на
https://api.novita.ai/v3/openai
Как получить доступ к Qwen3-Next-80B-A3B: Интеграции со сторонними сервисами
- Интеграция с фреймворками: Получайте доступ к Qwen3-Next-80B-A3B через LangChain, Dify и Langflow
- Инструменты для разработки: Совместим со стандартными для OpenAI инструментами, включая Trae, Claude Code, Qwen Code, Cline и Cursor
- Экосистема Hugging Face: Интегрируйте в Spaces и пайплайны через API Novita AI
Заключение
Qwen3-Next-80B-A3B представляет собой новое поколение крупномасштабного ИИ, который выделяется возможностями вызова инструментов и продвинутыми рассуждениями при выполнении очень сложных задач. Однако способ доступа к ней формирует ваш опыт реального использования: локальное развертывание дает полный контроль, но требует экстремально мощного оборудования; GPU-инстансы обеспечивают баланс между мощностью и гибкостью; а доступ через API предоставляет самый быстрый и бесшовный путь к интеграции.
С Novita AI все три варианта доступны в одном месте — с поддержкой конкурентоспособного ценообразования, готовых шаблонов и глобальной инфраструктуры. Будь вы исследователем, стартапом или крупным предприятием, Novita AI делает развертывание Qwen3-Next-80B-A3B практичным и экономически эффективным.
Часто задаваемые вопросы
Какие ключевые улучшения у Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B использует ультраразреженную архитектуру смеси экспертов с общим количеством параметров 80 миллиардов, но только 3 миллиарда активны во время инференса. Эта эффективность позволяет ей превосходить Qwen3-32B при потреблении менее одной десятой части ресурсов для обучения. Её прорывовая архитектура, включающая гибридное внимание, разреженность MoE 1:50 и предсказание нескольких токенов, обеспечивает более чем в 10 раз более быстрый инференс, особенно на задачах с длинным контекстом.
Какое оборудование требуется для локального запуска Qwen3-Next-80B-A3B?
Для локального развертывания Qwen3-Next-80B-A3B обычно требуются GPU NVIDIA A100, H100 или H200, так как потребительские GPU не имеют необходимого объема видеопамяти и пропускной способности.
Сколько стоит использование Qwen3-Next-80B-A3B через API Novita AI?
Использование API Qwen3-Next-80B-A3B тарифицируется прозрачно: $0,15 за 1M входных токенов и $1,50 за 1M выходных токенов на Novita AI
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывать ИИ-модели с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.



