

Qwen3-Next-80B-A3Bは、Qwen3シリーズに大きなアップデートをもたらす新しくリリースされた大規模言語モデルです。アーキテクチャと効率性が大幅に改善されており、推論、コーディング、長文コンテキストの理解能力が急速に進化しており、同クラスで最も競争力のあるモデルの1つとなっています。
この記事では、Qwen3-Next-80B-A3Bが他と一線を画す理由を明確に紹介し、ローカル環境、GPUインスタンス、APIのいずれかを利用して使い始めるためのさまざまな方法を学ぶことができます。
Qwen3-Next-80B-A3Bとは:基本情報、ベンチマーク、ハイライト
Qwen3-Next-80B-A3Bは800億個のパラメータで構築されていますが、高度にスパースなMoE(Mixture of Experts)アーキテクチャにより、一度にアクティブになるのは約30億個のみです。この構成により、このサイズのモデルに通常伴う余分な計算を回避しながら、高性能を発揮できます。実際、Qwen3-Next-80B-A3Bは学習と推論の両方で極めて高い効率性を実現しており、複雑な推論に十分な処理能力を持ちながら、実運用に適したリソース効率の良さを備えています。
| 特徴 | 詳細 |
| パラメータ | 合計800億、アクティブ時30億 |
| エキスパート | 合計512、トークンごとに10個アクティブ(うち1個は共有) |
| アーキテクチャ | 高スパース混合専門家(MoE) |
| コンテキスト長 | ネイティブで262,144トークン、最大1,010,000トークンまで拡張可能 |
| モード | Thinking/Non-Thinking(2つの独立したモデル) |
| マルチモーダル | テキストのみ |
| ライセンス | Apache 2.0 |
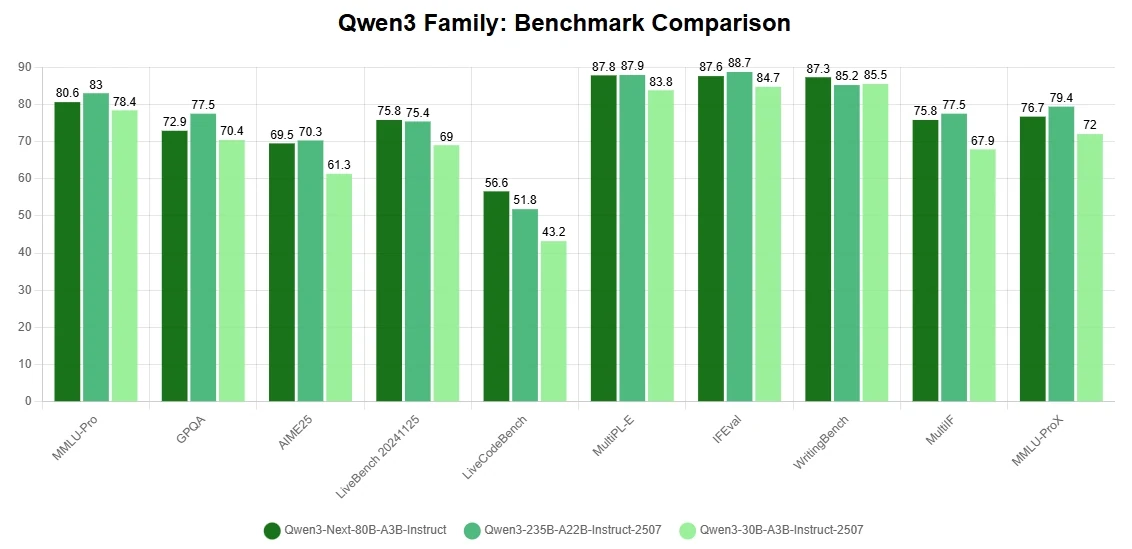
主なハイライト
- 学習コスト削減のためのアーキテクチャブレイクスルー:ハイブリッドアテンション機構、高度にスパースな混合専門家構造、安定性重視の学習最適化、そして高速推論のためのマルチトークン予測を搭載。これらの革新により、Qwen3-Next-80B-A3Bは学習コスト(GPU時間)を10%未満に抑えながら、Qwen3-32Bの性能に匹敵する、あるいはそれを超える性能を発揮します。
- 長文コンテキスト推論の極めて高い効率性:32Kトークンを超えるシーケンスを処理する場合、従来の構成と比較して10倍以上のスループットを実現。これにより学習と推論の両方で極めて高い効率性が得られ、精度を損なうことなく計算コストを削減します。
- 最高クラスの推論・コーディング能力:高度な推論とコーディングのベンチマークで優れた成績を収め、公開されているモデルの中でも最強クラスの地位を確立。これにより、Qwen3-Next-80B-A3Bは研究と実運用向けアプリケーションの両方で汎用的に選択できるモデルとなっています。
Qwen3-Next-80B-A3Bの利用方法:ローカルデプロイ
Qwen3-Next-80B-A3Bをローカルで実行することで、最大限の制御とデータセキュリティが得られます。環境を所有し、自由にファインチューニングでき、すべてをオンプレミスで保持できます。
- メリット:完全な制御、機密データの取り扱いに最適、研究の柔軟性が高い。
- デメリット:非常に高いハードウェア要件(800億パラメータのため高性能GPUが必要)、セットアップに時間がかかる、継続的なメンテナンスコストが発生する。
Qwen3-Next-80B-A3Bをローカルで実行すると自由度は高まりますが、ハードウェアと時間の面で大きなコストがかかります。通常、A100またはH100以上のGPUが必要となるため、多くの開発者はGPUインスタンスを利用しています。これは同じ処理能力をオーバーヘッドなしで得られる、より賢い方法です。
Qwen3-Next-80B-A3Bの利用方法:GPUインスタンス
クラウドGPUインスタンスを利用してQwen3-Next-80B-A3Bを実行することで、性能とアクセスのしやすさの実用的なバランスが得られます。
メリット:
- 高価なオンプレミスハードウェアへの投資が不要
- ローカル環境に近い性能で柔軟にスケーリング可能
- 完全なローカル環境と比較してセットアップが速く、メンテナンスが容易
デメリット:
- ある程度の環境管理(モデル重みの読み込み、ランタイムの設定、推論の監視)が依然として必要
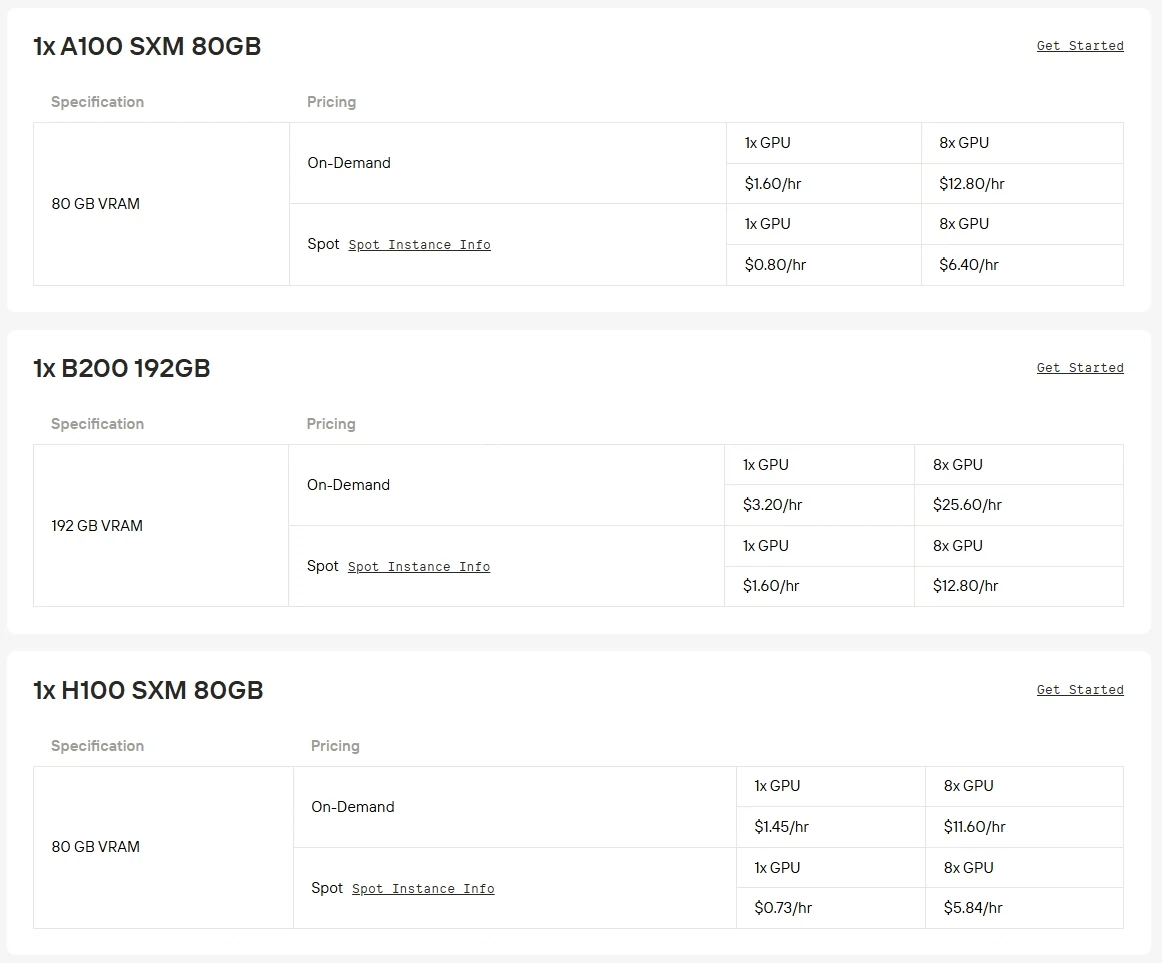
ハードウェア要件: Qwen3-Next-80B-A3Bは800億パラメータのモデルであり、効率的な推論のためにはA100、H100、H200などの高性能GPUが必要です。コンシューマー向けGPUはVRAMとスループットの制限から、通常このモデルを実行するのは現実的ではありません。
Novita AIは現在、エンタープライズグレードのGPU性能を最大50%オフで提供しており、Qwen3-Next-80B-A3Bのような大規模モデルをこれまで以上に利用しやすくしています。下のボタンをクリックして今すぐお試しください!
RTX 5090、RTX 6000 Adaなどの高性能GPUも、競争力のある価格で柔軟な課金システムとともにNovita AIで利用可能です。

デプロイの効率化をさらに進めるため、Novita AIはすぐに使えるテンプレートも提供しています。手動セットアップを不要にすることで、セットアップの複雑さを排除します。
事前設定済みテンプレートは、検証済みのパラメータ、事前設定された環境変数、コンテナ化された構成を備えた最適化された環境を提供します。DeepSeek、LLaMA、その他の最先端のフレームワークを即座に起動できます。上級ユーザー向けには、カスタムテンプレートサポートにより、パーソナライズされたスクリプト、カスタムスタック、微調整された最適化を通じて最大限の柔軟性が確保されます。
デプロイやインフラ管理を完全に回避したい場合、Novita AIのAPIアクセスはQwen3-Next-80B-A3Bを実行するための最も手間がかからず、コスト効率の高い方法です。
Qwen3-Next-80B-A3Bの利用方法:APIアクセス
オプション1:直接API連携
Novita AIのAPIはエンタープライズグレードの性能を提供しており、0.85秒という非常に低いレイテンシと189.6 tpsの高いスループットに加え、100万入力トークンあたり0.15ドル、100万出力トークンあたり1.50ドルという透明性の高い料金体系を備えているため、大規模な開発者にとって高速かつコスト効率に優れています。

ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリボタンをクリックしてください。

ステップ2:モデルを選択
利用可能なオプションを閲覧し、ニーズに合ったモデルを選択してください。
ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始してください。
ステップ4:APIキーを取得
APIでの認証のために、新しいAPIキーを発行します。「アカウント設定」ページに移動すると、画像の指示に従ってAPIキーをコピーできます。

ステップ5:APIをインストール
使用しているプログラミング言語に対応したパッケージマネージャーを使用してAPIをインストールしてください。
インストール後、開発環境に必要なライブラリをインポートしてください。APIキーでAPIを初期化することで、Novita AI LLMとの連携を開始できます。以下はPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
プラットフォームの機能:
- OpenAI互換エンドポイント:シームレスな連携のための
/v3/openai - 柔軟なパラメータ:temperature、top-p、ペナルティなどで生成を制御可能
- ストリーミング対応:ストリーミングまたはバッチレスポンスを選択可能
- モデル選択:インストラクト版とThinking版の両方にアクセス可能
オプション2:OpenAI Agents SDKを利用したマルチエージェントワークフロー
Novita AIのインフラを活用して、Qwen3-Nextの効率性を活かしたエージェントシステムを構築できます:
- OpenAI Agents SDK互換:Novitaのエンドポイントと組み合わせてOpenAI Agents SDKをエージェントワークフローに利用可能
- エージェント機能:極めて高いスパース性と長文コンテキスト性能を活用したシステムを設計可能
- シンプルな連携:SDKを
https://api.novita.ai/v3/openaiに向けるだけで連携可能
Qwen3-Next-80B-A3Bの利用方法:サードパーティ連携
- フレームワーク連携:LangChain、Dify、Langflowを介してQwen3-Next-80B-A3Bにアクセス可能
- 開発ツール:Trae、Claude Code、Qwen Code、Cline、CursorなどのOpenAI標準ツールと互換性あり
- Hugging Faceエコシステム:Novita AIのAPIを介してSpacesやパイプラインに統合可能
結論
Qwen3-Next-80B-A3Bは新世代の大規模AIを代表するモデルで、ツール呼び出し機能と高度な推論能力に優れ、非常に複雑なタスクでも高い性能を発揮します。ただし、その利用方法によって実運用での体験が大きく異なります:ローカルデプロイは完全な制御が可能な反面、極めて高性能なハードウェアが必要です;GPUインスタンスは性能と柔軟性のバランスが取れています;APIアクセスは最も速く、シームレスな統合が可能です。
Novita AIでは、これら3つの選択肢をすべて同じプラットフォームで提供しており、競争力のある料金体系、すぐに使えるテンプレート、グローバルインフラでサポートされています。研究者、スタートアップ、企業のいずれであっても、Novita AIはQwen3-Next-80B-A3Bのデプロイを実用的かつコスト効率の高いものにします。
よくある質問
Qwen3-Next-80B-A3Bの主な改善点は何ですか?
Qwen3-Next-80B-A3Bは、合計800億個のパラメータを持ちながら推論時には30億個のみがアクティブになる超スパースな混合専門家設計を採用しています。この効率性により、学習リソースを10分の1以下に抑えながらQwen3-32Bを上回る性能を発揮します。Hybrid Attention、1:50のMoEスパース性、Multi-Token Predictionを特徴とするブレイクスルーアーキテクチャにより、特に長文コンテキストタスクで10倍以上の高速な推論が可能になっています。
Qwen3-Next-80B-A3Bをローカルで実行するために必要なハードウェアは何ですか?
Qwen3-Next-80B-A3Bのローカルデプロイには通常、NVIDIA A100、H100、H200のGPUが必要です。これはコンシューマー向けGPUでは必要なVRAMとスループットが不足しているためです。
Novita AIのAPIを介してQwen3-Next-80B-A3Bを利用する場合の料金はいくらですか?
Novita AIでのQwen3-Next-80B-A3B APIの利用料金は、100万入力トークンあたり0.15ドル、100万出力トークンあたり1.50ドルと透明性の高い課金体系になっています。
Novita AIは、シンプルなAPIを利用してAIモデルを簡単にデプロイできる開発者向けAIクラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。



