

Qwen3-Next-80B-A3B is a newly released large language model that brings major updates to the Qwen3 series. With significant improvements in architecture and efficiency, its capabilities in reasoning, coding, and long-context understanding have advanced rapidly, positioning it as one of the most competitive models in its class.
In this article, you’ll get a clear look at what makes Qwen3-Next-80B-A3B stand out and learn the different ways you can start using it—whether locally, with GPU instances, or via API.
What is Qwen3-Next-80B-A3B: Basics, Benchmark and Highlights
Qwen3-Next-80B-A3B is built with 80 billion parameters, but only around 3 billion are activated at a time thanks to its highly sparse MoE architecture. This setup allows the model to deliver high-level performance while avoiding the extra computation usually tied to models of this size. In practice, Qwen3-Next-80B-A3B achieves extreme efficiency in both training and inference, making it powerful enough for complex reasoning yet resource-friendly for real-world deployment.
| Feature | Detail |
| Parameter | 80B in total and 3B activated |
| Expert | 512 in total with 10 activated per token (1 shared) |
| Architecture | High-Sparsity Mixture-of-Experts (MoE) |
| Context Length | 262,144 natively and extensible up to 1,010,000 tokens |
| Mode | Thinking/Non-Thinking (2 separate models) |
| Multimodal | Text-only |
| Liscense | Apache 2.0 |
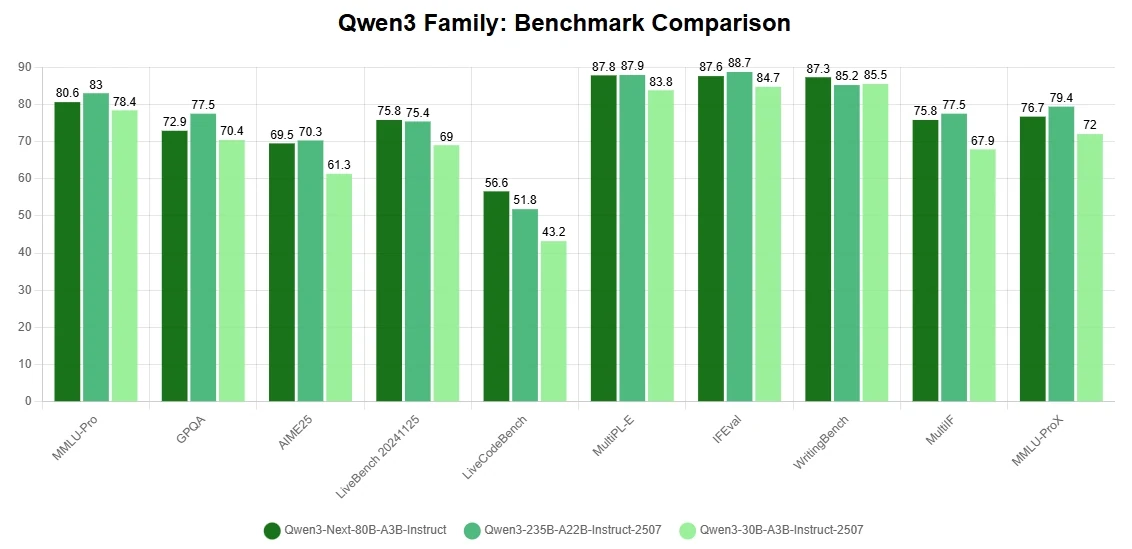
Key Highlights
- Architectural Breakthroughs for Lower Training Cost: Built with a hybrid attention mechanism, a highly sparse Mixture-of-Experts structure, and stability-oriented training optimizations, plus multi-token prediction for faster inference. These innovations enable Qwen3-Next-80B-A3B to match or even surpass the dense Qwen3-32B in performance while consuming less than 10% of its training cost (GPU hours).
- Extreme Efficiency in Long-Context Inference: When handling sequences beyond 32K tokens, the model delivers over 10× higher throughput than conventional setups. This translates into exceptional efficiency across both training and inference, cutting computational costs without compromising accuracy.
- Top-Tier Reasoning and Coding Capabilities: Excels in advanced reasoning and coding benchmarks, ranking among the strongest open models available. This positions Qwen3-Next-80B-A3B as a versatile choice for both research and production-grade applications.
How to Access Qwen3-Next-80B-A3B: Local Deployment
Running Qwen3-Next-80B-A3B locally gives you maximum control and data security. You own the environment, can fine-tune freely, and keep everything on-premise.
- Pros: Full control, best for sensitive data, research flexibility.
- Cons: Extremely high hardware requirements (80B parameters demand powerful GPUs), long setup time, and ongoing maintenance costs.
Running Qwen3-Next-80B-A3B locally gives you freedom, but at a heavy cost in hardware and time—typically requiring at least A100 or H100 GPUs. That’s why many developers turn to GPU instances—a smarter way to get the same power without the overhead.
How to Access Qwen3-Next-80B-A3B: GPU Instance
Running Qwen3-Next-80B-A3B through cloud GPU instances offers a practical balance between performance and accessibility.
Pros:
- No need to invest in expensive on-premise hardware
- Elastic scaling with near-local performance
- Faster setup and easier maintenance compared to fully local environments
Cons:
- Still requires some environment management (loading model weights, configuring runtimes, monitoring inference)
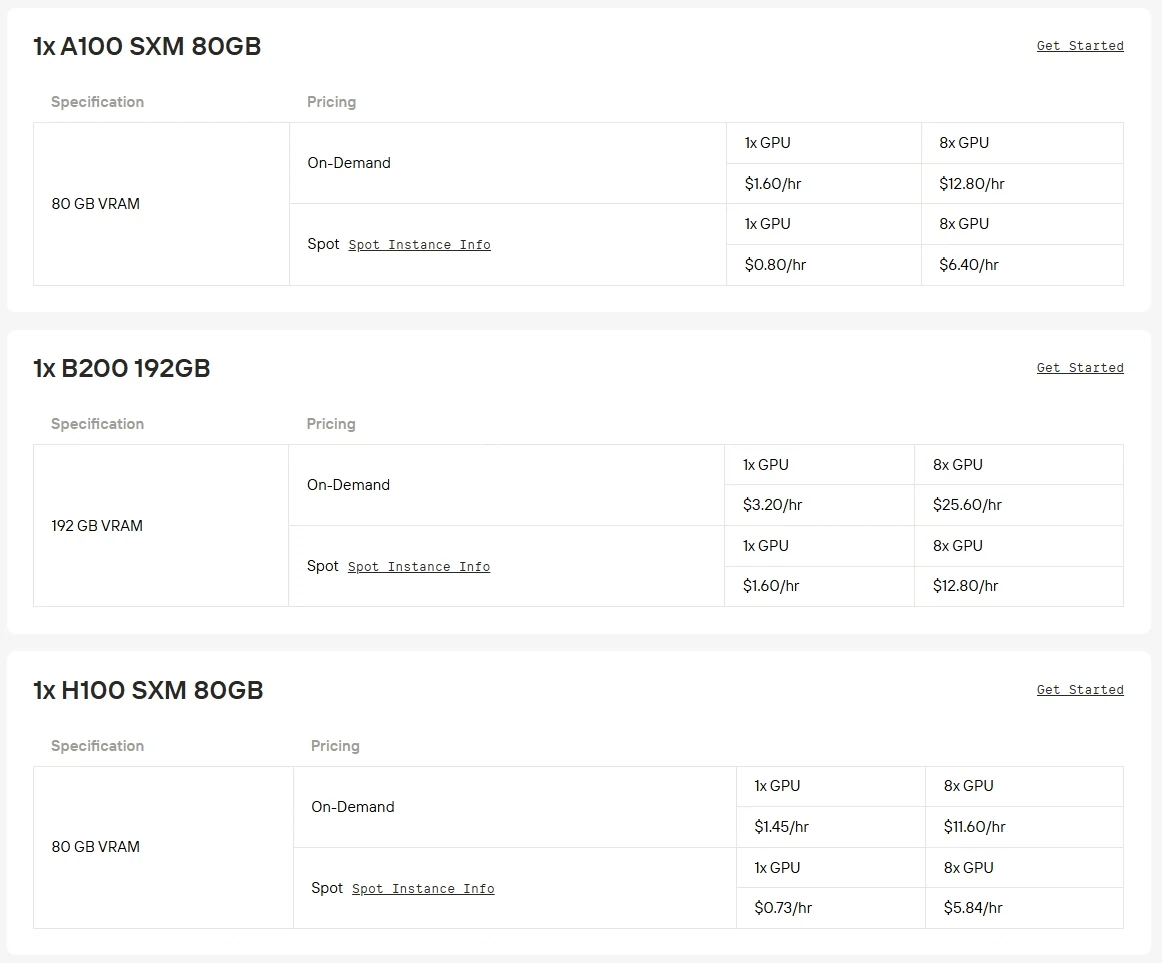
Hardware Requirements: Qwen3-Next-80B-A3B is an 80B-parameter model that demands powerful GPUs such as A100, H100 or H200 for efficient inference. Running it on consumer-grade GPUs is typically impractical due to VRAM and throughput limitations.
Novita AI now offers enterprise-grade GPU power at up to 50% off, making large-scale models like Qwen3-Next-80B-A3B more accessible than ever. Click the button below to have a try at once!
More options of demanding GPUs such as RTX 5090, RTX 6000 Ada are also available on Novita AI with flexible billing at a competitive price.

To make deployment just as efficient, Novita AI also provides ready-to-use templates that remove the complexity of setup by eliminating manual setup.
Pre-configured Templates offer optimized environments with validated parameters, pre-set environment variables, and containerized configurations—so you can launch instantly with DeepSeek, LLaMA, and other state-of-the-art frameworks. For advanced users, Custom Template Support ensures maximum flexibility through personalized scripts, custom stacks, and fine-tuned optimizations.
If you prefer to avoid deployment and infrastructure management altogether, Novita AI’s API access offers the most hassle-free and cost-efficient way to run Qwen3-Next-80B-A3B.
How to Access Qwen3-Next-80B-A3B: API Access
Option 1: Direct API Integration
Novita AI’s API offers enterprise-grade performance—very low latency at 0.85sec and high throughput of 189.6 tps—together with transparent pricing at only $0.15 per 1M input tokens and $1.50 per 1M output tokens, making it both fast and cost-efficient for developers at scale.

Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Account Settings” page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)Platform Features:
- OpenAI-compatible endpoint:
/v3/openaifor seamless integration - Flexible parameters: Control generation with temperature, top-p, penalties, and more
- Streaming support: Choose between streaming or batch responses
- Model selection: Access both instruct and thinking variants
Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build agent systems that leverage Qwen3-Next’s efficiency through Novita AI’s infrastructure:
- OpenAI Agents SDK compatibility: Use the OpenAI Agents SDK with Novita’s endpoint for agent workflows
- Agent capabilities: Design systems that benefit from extreme sparsity and long-context performance
- Simple integration: Point the SDK to
https://api.novita.ai/v3/openai
How to Access Qwen3-Next-80B-A3B: Third-Party Integrations
- Framework Integration: Access Qwen3-Next-80B-A3B through LangChain, Dify, and Langflow
- Development Tools: Compatible with OpenAI-standard tools including Trae, Claude Code, Qwen Code, Cline, and Cursor
- Hugging Face Ecosystem: Integrate in Spaces and pipelines via Novita AI’s API
Conclusion
Qwen3-Next-80B-A3B represents a new generation of large-scale AI, excelling in tool calling capabilities and advanced reasoning across highly complex tasks. Yet the way you access it shapes your real-world experience: local deployment offers full control but requires extreme hardware; GPU instances strike a balance between power and flexibility; and API access provides the fastest, most seamless path to integration.
With Novita AI, all three options are available under one roof—supported by competitive pricing, ready-to-use templates, and a global infrastructure. Whether you are a researcher, a startup, or an enterprise, Novita AI makes deploying Qwen3-Next-80B-A3B both practical and cost-efficient.
Frequently Asked Questions
What are the key improvements of Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B adopts an ultra-sparse Mixture-of-Experts design with 80 billion total parameters but only 3 billion active during inference. This efficiency enables it to outperform Qwen3-32B while consuming less than one-tenth of the training resources. Its breakthrough architecture—featuring Hybrid Attention, 1:50 MoE sparsity, and Multi-Token Prediction—translates into over 10x faster inference, especially on long-context tasks.
What hardware is required to run Qwen3-Next-80B-A3B locally?
Local deployment of Qwen3-Next-80B-A3B typically requires NVIDIA A100, H100, or H200 GPUs, as consumer-grade GPUs lack the necessary VRAM and throughput.
How much does it cost to use Qwen3-Next-80B-A3B via Novita AI’s API?
Qwen3-Next-80B-A3B API usage is billed transparently at $0.15 per 1M input tokens and $1.50 per 1M output tokens on Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



