

- Was ist Qwen3-Next-80B-A3B: Grundlagen, Benchmarks und Highlights
- So greifen Sie auf Qwen3-Next-80B-A3B zu: Lokale Bereitstellung
- So greifen Sie auf Qwen3-Next-80B-A3B zu: GPU-Instanz
- So greifen Sie auf Qwen3-Next-80B-A3B zu: API-Zugriff
- So greifen Sie auf Qwen3-Next-80B-A3B zu: Integrationen von Drittanbietern
- Fazit
Qwen3-Next-80B-A3B ist ein neu veröffentlichtes großes Sprachmodell, das wichtige Updates für die Qwen3-Serie mit sich bringt. Dank erheblicher Verbesserungen bei Architektur und Effizienz haben sich seine Fähigkeiten in den Bereichen Reasoning, Codierung und Langkontext-Verständnis schnell weiterentwickelt, sodass es zu den wettbewerbsfähigsten Modellen seiner Klasse zählt.
In diesem Artikel erfahren Sie, was Qwen3-Next-80B-A3B besonders macht, und lernen die verschiedenen Möglichkeiten kennen, es zu nutzen – ob lokal, über GPU-Instanzen oder per API.
Was ist Qwen3-Next-80B-A3B: Grundlagen, Benchmarks und Highlights
Qwen3-Next-80B-A3B verfügt über 80 Milliarden Parameter, von denen jedoch dank seiner hochgradig sparse MoE-Architektur (Mixture of Experts) jeweils nur etwa 3 Milliarden aktiviert werden. Diese Konfiguration ermöglicht es dem Modell, eine hohe Leistung zu erbringen, während es den zusätzlichen Rechenaufwand vermeidet, der normalerweise mit Modellen dieser Größe verbunden ist. In der Praxis erreicht Qwen3-Next-80B-A3B eine extreme Effizienz sowohl beim Training als auch bei der Inferenz, sodass es leistungsstark genug für komplexe Reasoning-Aufgaben ist, aber gleichzeitig ressourcenschonend für den praktischen Einsatz.
| Merkmal | Detail |
| Parameter | Insgesamt 80B, 3B aktiviert |
| Experten | Insgesamt 512, pro Token 10 aktiviert (1 gemeinsam genutzt) |
| Architektur | Hochgradig sparse Mixture-of-Experts (MoE) |
| Kontextlänge | Nativ 262.144, erweiterbar auf bis zu 1.010.000 Token |
| Modus | Thinking/Non-Thinking (2 separate Modelle) |
| Multimodal | Nur Text |
| Lizenz | Apache 2.0 |
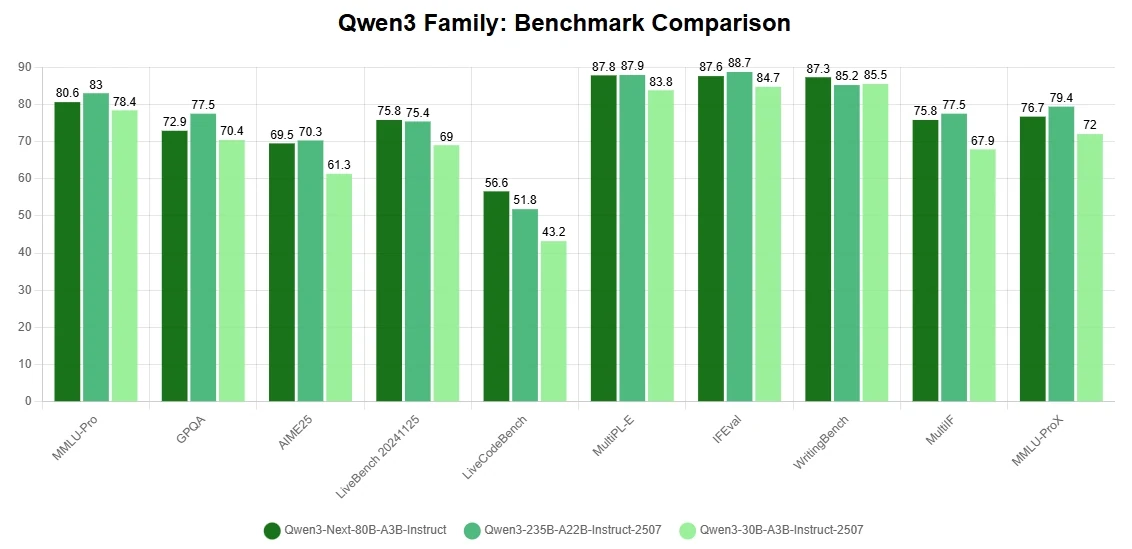
Wichtige Highlights
- Architektonische Durchbrüche für niedrigere Trainingskosten: Das Modell basiert auf einem hybriden Aufmerksamkeitsmechanismus, einer hochgradig sparse Mixture-of-Experts-Struktur und stabilisierungsorientierten Trainingsoptimierungen sowie Multi-Token-Vorhersage für schnellere Inferenz. Diese Innovationen ermöglichen es Qwen3-Next-80B-A3B, in der Leistung mit dem dichten Qwen3-32B gleichzuziehen oder es sogar zu übertreffen, während es weniger als 10 % seiner Trainingskosten (GPU-Stunden) verbraucht.
- Extreme Effizienz bei der Langkontext-Inferenz: Bei der Verarbeitung von Sequenzen mit mehr als 32K Token liefert das Modell einen mehr als 10 Mal höheren Durchsatz als herkömmliche Konfigurationen. Dies führt zu einer außergewöhnlichen Effizienz sowohl beim Training als auch bei der Inferenz, wodurch Rechenkosten gesenkt werden, ohne die Genauigkeit zu beeinträchtigen.
- Erstklassige Reasoning- und Codierungsfähigkeiten: Das Modell glänzt in fortgeschrittenen Reasoning- und Codierungs-Benchmarks und gehört zu den stärksten verfügbaren Open-Source-Modellen. Dies macht Qwen3-Next-80B-A3B zu einer vielseitigen Wahl sowohl für die Forschung als auch für produktionsreife Anwendungen.
So greifen Sie auf Qwen3-Next-80B-A3B zu: Lokale Bereitstellung
Die lokale Ausführung von Qwen3-Next-80B-A3B bietet Ihnen maximale Kontrolle und Datensicherheit. Sie besitzen die Umgebung, können das Modell frei feinabstimmen und alles vor Ort behalten.
- Vorteile: Volle Kontrolle, am besten für sensible Daten, Forschungsflexibilität.
- Nachteile: Extrem hohe Hardwareanforderungen (80B Parameter erfordern leistungsstarke GPUs), lange Einrichtungszeit und laufende Wartungskosten.
Die lokale Ausführung von Qwen3-Next-80B-A3B gibt Ihnen Freiheit, aber zu hohen Kosten in Bezug auf Hardware und Zeit – normalerweise werden mindestens A100- oder H100-GPUs benötigt. Deshalb greifen viele Entwickler auf GPU-Instanzen zurück – ein intelligenterer Weg, um die gleiche Leistung ohne den damit verbundenen Aufwand zu erhalten.
So greifen Sie auf Qwen3-Next-80B-A3B zu: GPU-Instanz
Die Ausführung von Qwen3-Next-80B-A3B über Cloud-GPU-Instanzen bietet ein praktisches Gleichgewicht zwischen Leistung und Zugänglichkeit.
Vorteile:
- Keine Investition in teure lokale Hardware erforderlich
- Elastische Skalierung mit fast lokaler Leistung
- Schnellere Einrichtung und einfachere Wartung im Vergleich zu vollständig lokalen Umgebungen
Nachteile:
- Erfordert immer noch etwas Umgebungsmanagement (Laden von Modellgewichten, Konfigurieren von Laufzeiten, Überwachen der Inferenz)
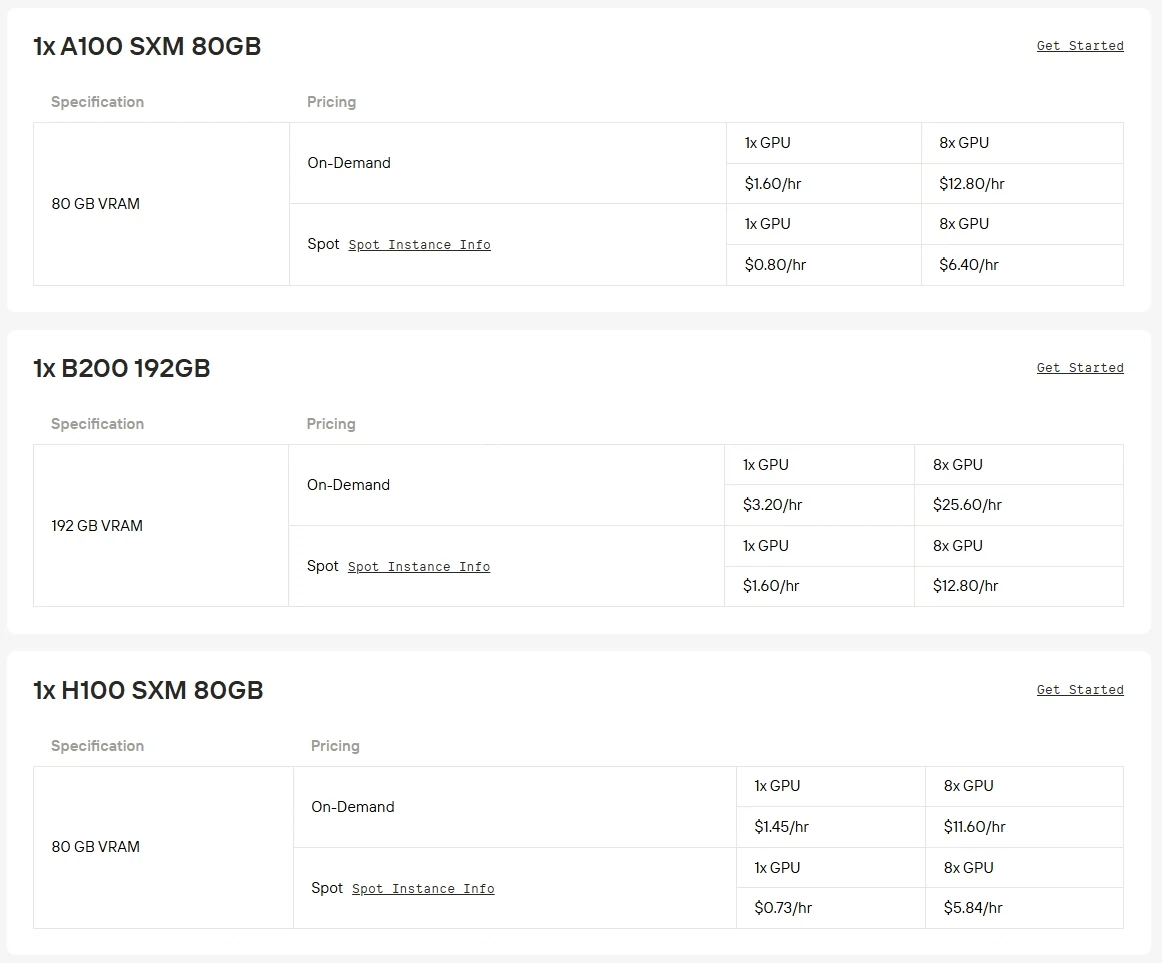
Hardwareanforderungen: Qwen3-Next-80B-A3B ist ein Modell mit 80B Parametern, das für effiziente Inferenz leistungsstarke GPUs wie A100, H100 oder H200 erfordert. Die Ausführung auf Consumer-GPUs ist aufgrund von VRAM- und Durchsatzbeschränkungen in der Regel unpraktisch.
Novita AI bietet jetzt Enterprise-GPU-Leistung mit bis zu 50 % Rabatt an, sodass großskalige Modelle wie Qwen3-Next-80B-A3B zugänglicher sind als je zuvor. Klicken Sie auf die Schaltfläche unten, um es sofort auszuprobieren!
Jetzt Novita AI GPUs ausprobieren !
Weitere Optionen für leistungsstarke GPUs wie RTX 5090, RTX 6000 Ada sind ebenfalls bei Novita AI mit flexibler Abrechnung zu wettbewerbsfähigen Preisen verfügbar.

Um die Bereitstellung ebenso effizient zu gestalten, bietet Novita AI außerdem vorkonfigurierte Vorlagen, die die Komplexität der Einrichtung durch den Wegfall manueller Schritte beseitigen.
Vorkonfigurierte Vorlagen bieten optimierte Umgebungen mit validierten Parametern, voreingestellten Umgebungsvariablen und containerisierten Konfigurationen – sodass Sie sofort mit DeepSeek, LLaMA und anderen state-of-the-art-Frameworks starten können. Für fortgeschrittene Benutzer sorgt der Support für benutzerdefinierte Vorlagen für maximale Flexibilität durch personalisierte Skripte, benutzerdefinierte Stacks und feinabgestimmte Optimierungen.
Wenn Sie Bereitstellung und Infrastrukturverwaltung vollständig vermeiden möchten, bietet der API-Zugang von Novita AI den einfachsten und kosteneffizientesten Weg, Qwen3-Next-80B-A3B auszuführen.
So greifen Sie auf Qwen3-Next-80B-A3B zu: API-Zugriff
Option 1: Direkte API-Integration
Die API von Novita AI bietet Enterprise-Leistung – sehr niedrige Latenz von 0,85 Sekunden und hoher Durchsatz von 189,6 tps – sowie transparente Preise von nur 0,15 $ pro 1M Eingabe-Token und 1,50 $ pro 1M Ausgabe-Token, sodass sie für Entwickler im großen Maßstab sowohl schnell als auch kosteneffizient ist.

Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Qwen3-Next kostenlos ausprobieren!
Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Kontoeinstellungen" können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completion-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Plattformfunktionen:
- OpenAI-kompatibler Endpunkt:
/v3/openaifür nahtlose Integration - Flexible Parameter: Steuern Sie die Generierung mit Temperatur, Top-p, Strafen und mehr
- Streaming-Unterstützung: Wählen Sie zwischen Streaming- oder Batch-Antworten
- Modellauswahl: Greifen Sie auf sowohl Instruct- als auch Thinking-Varianten zu
Option 2: Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie Agent-Systeme, die die Effizienz von Qwen3-Next über die Infrastruktur von Novita AI nutzen:
- Kompatibilität mit dem OpenAI Agents SDK: Nutzen Sie den OpenAI Agents SDK mit dem Endpunkt von Novita für Agent-Workflows
- Agent-Fähigkeiten: Entwerfen Sie Systeme, die von extremer Sparsity und Langkontext-Leistung profitieren
- Einfache Integration: Zeigen Sie das SDK auf
https://api.novita.ai/v3/openai
So greifen Sie auf Qwen3-Next-80B-A3B zu: Integrationen von Drittanbietern
- Framework-Integration: Greifen Sie auf Qwen3-Next-80B-A3B über LangChain, Dify und Langflow zu
- Entwicklungstools: Kompatibel mit OpenAI-Standardtools, darunter Trae, Claude Code, Qwen Code, Cline und Cursor
- Hugging Face Ökosystem: Integrieren Sie es in Spaces und Pipelines über die API von Novita AI
Fazit
Qwen3-Next-80B-A3B repräsentiert eine neue Generation von großskaliger KI, die mit herausragenden Fähigkeiten beim Tool-Calling und fortgeschrittenem Reasoning bei hochkomplexen Aufgaben glänzt. Die Art des Zugriffs bestimmt jedoch Ihre praktische Erfahrung: Lokale Bereitstellung bietet volle Kontrolle, erfordert aber extreme Hardware; GPU-Instanzen stellen ein Gleichgewicht zwischen Leistung und Flexibilität her; und der API-Zugang bietet den schnellsten, nahtlosesten Weg zur Integration.
Bei Novita AI sind alle drei Optionen unter einem Dach verfügbar – unterstützt durch wettbewerbsfähige Preise, vorkonfigurierte Vorlagen und eine globale Infrastruktur. Egal, ob Sie Forscher, Startup oder Unternehmen sind, Novita AI macht die Bereitstellung von Qwen3-Next-80B-A3B sowohl praktisch als auch kosteneffizient.
Häufig gestellte Fragen
Was sind die wichtigsten Verbesserungen von Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B verwendet ein ultradichtes Mixture-of-Experts-Design mit insgesamt 80 Milliarden Parametern, von denen jedoch nur 3 Milliarden während der Inferenz aktiv sind. Diese Effizienz ermöglicht es ihm, Qwen3-32B zu übertreffen, während es weniger als ein Zehntel der Trainingsressourcen verbraucht. Seine bahnbrechende Architektur – mit Hybrid Attention, 1:50 MoE-Sparsity und Multi-Token-Vorhersage – führt zu einer mehr als 10 Mal schnelleren Inferenz, insbesondere bei Langkontext-Aufgaben.
Welche Hardware wird für die lokale Ausführung von Qwen3-Next-80B-A3B benötigt?
Für die lokale Bereitstellung von Qwen3-Next-80B-A3B werden in der Regel NVIDIA A100-, H100- oder H200-GPUs benötigt, da Consumer-GPUs nicht über den erforderlichen VRAM und Durchsatz verfügen.
Wie viel kostet die Nutzung von Qwen3-Next-80B-A3B über die API von Novita AI?
Die Nutzung der Qwen3-Next-80B-A3B API wird bei Novita AI transparent mit 0,15 $ pro 1M Eingabe-Token und 1,50 $ pro 1M Ausgabe-Token abgerechnet
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern einen einfachen Weg zur Bereitstellung von KI-Modellen über unsere einfache API bietet und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Entwicklung und Skalierung bereitstellt.



